Kafka在1.1.0版本引入了fetch session的概念,旨在降低“无效”FETCH请求对集群带宽资源的占用。故事的背景是这样的:
众所周知,Kafka的broker和consumer都会定期地向leader broker发送FETCH请求去获取数据。对于分区数很多的topic而言,待发送的FETCH请求就会很大,从而整体上增加网络带宽占用。即使这些分区没有任何新的数据到来,follower和consumer构造的FETCH请求都需要显式地罗列出每个订阅分区的详细数据,这包括:分区号、该分区当前开始位移(log start offset)、位移以及能够请求的最大字节数。
下面我们以1.0.2版本为例查看一下一个普通的FETCH请求有多大?首先启动两台broker服务器,然后创建一个replcation factor是2且有1000个分区的topic:test,之后观察下列JMX指标的值,如下图所示:
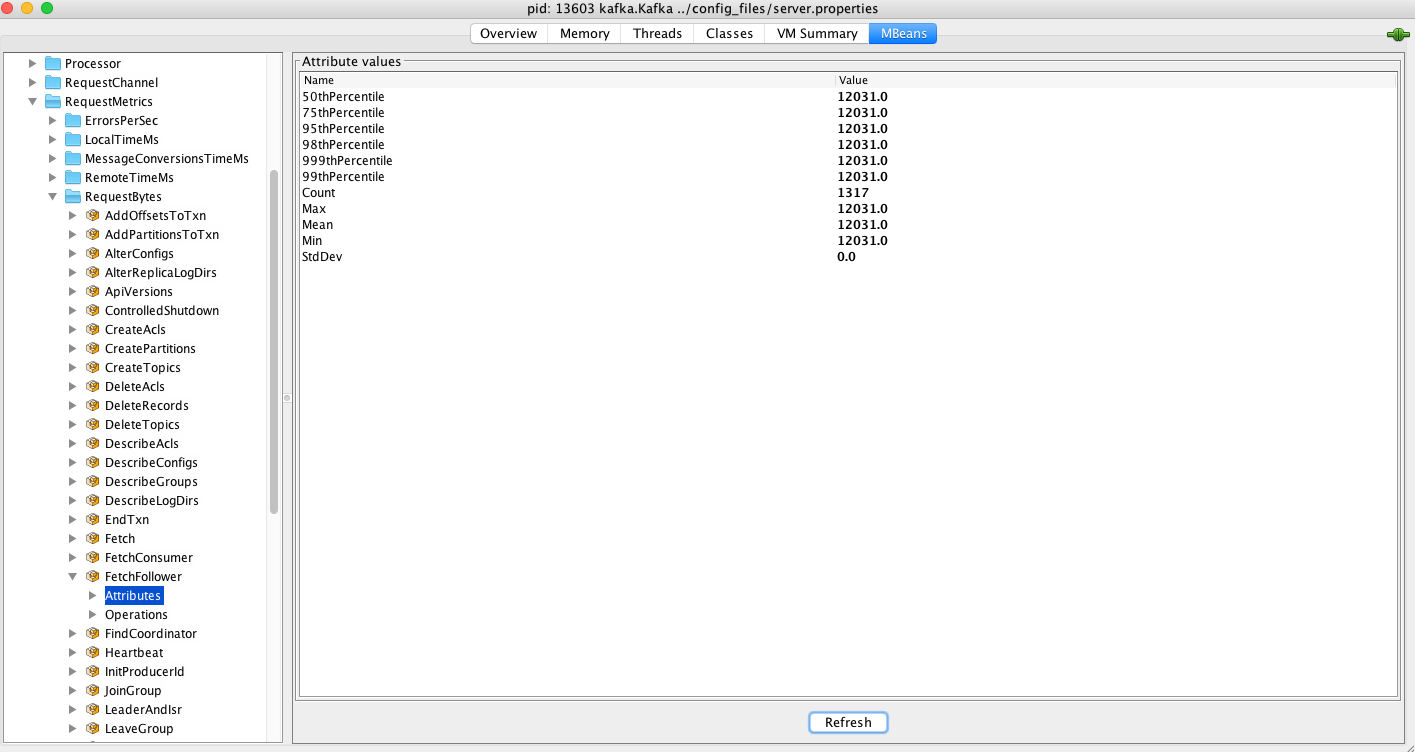
可以看出,对于这个有着1000个分区的topic而言,每台broker上接收到的FETCH请求大小固定是12031个字节,即大约12KB左右。即使我没有给这个topic发送过任何消息(即consumer没有可以消费的消息),FETCH请求都是这么大。
下面我们再用1.1.0版本重试一下这个测试,依然是启动两台1.1.0版本的broker服务器,然后创建一个replication-factor是2,有1000个分区的topic,然后再次查看FETCH请求的大小,如下图所示:
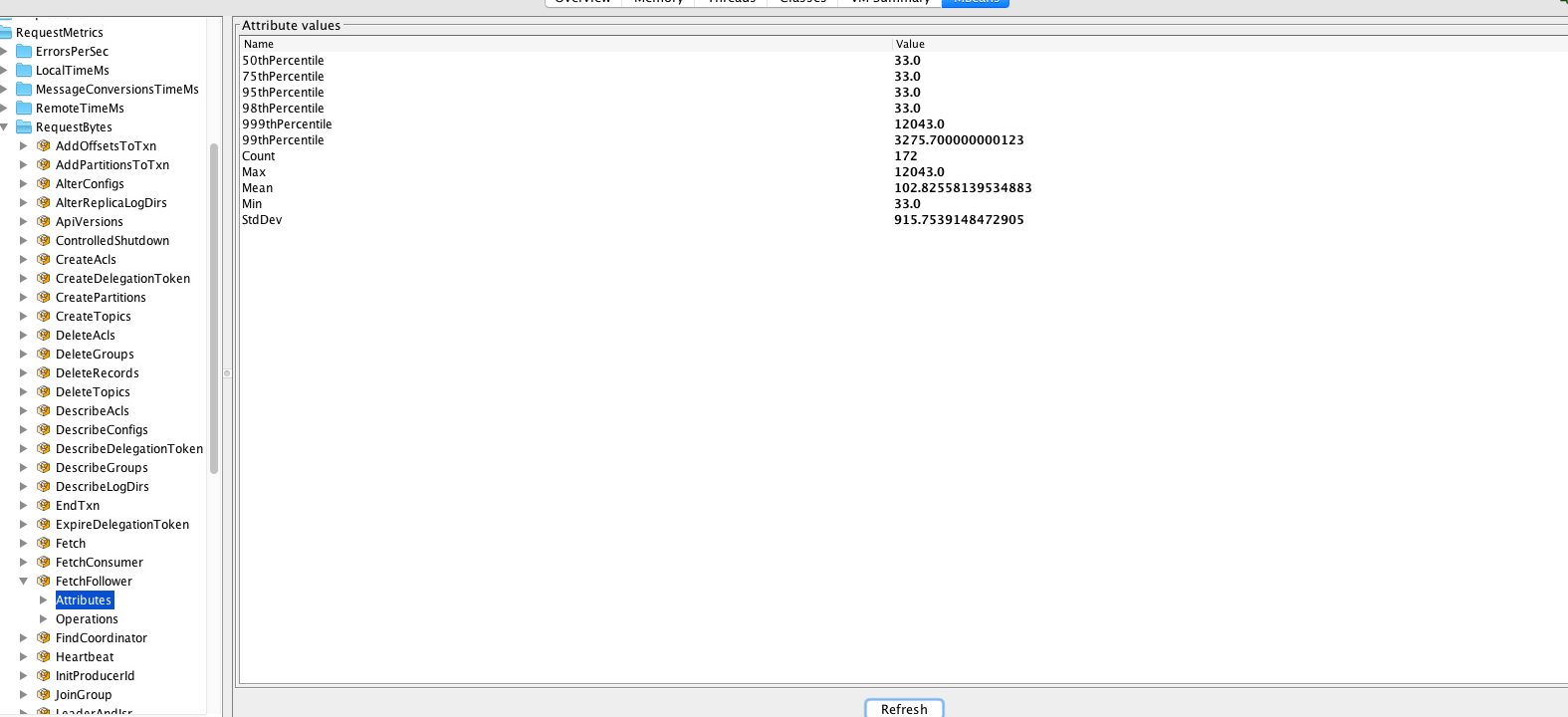
这次我们发现FETCH请求大小的最大值可以达到12043字节,而之后一定稳定在最小值33字节上。从这两组测试结果来看,显然1.1.0版本在某些情况下极大地减少了FETCH请求的大小,节省了网络带宽(针对我们这个测试topic而言,网络流量节省了将近365倍!)。那么这是怎么做到的呢?首先先从FETCH请求的协议格式开始说起。1.1.0之前最新的FETCH请求格式是V6版本,如下图所示:
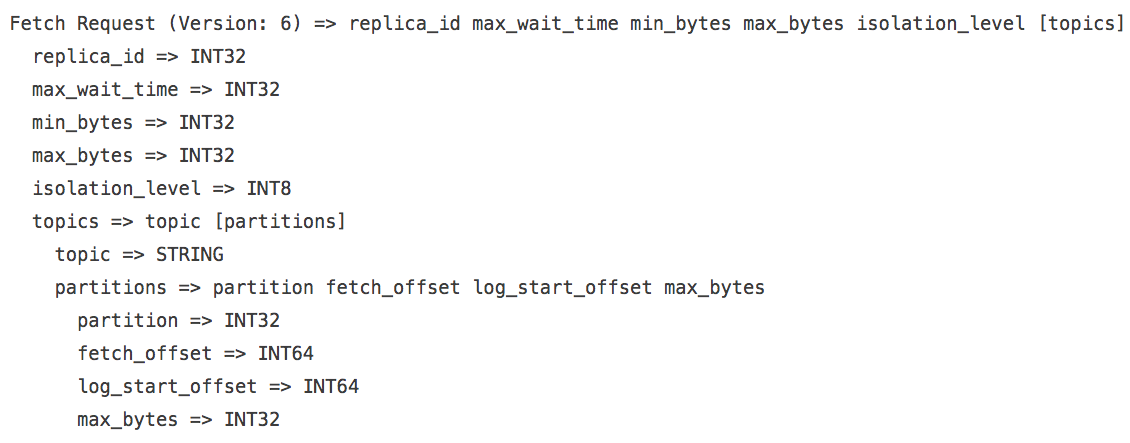
这里我不详细展开各个字段的含义了,因为这与本文要讨论的主题无关。不过我请各位再看下1.1.0版本引入的V7版本格式,如下图所示:
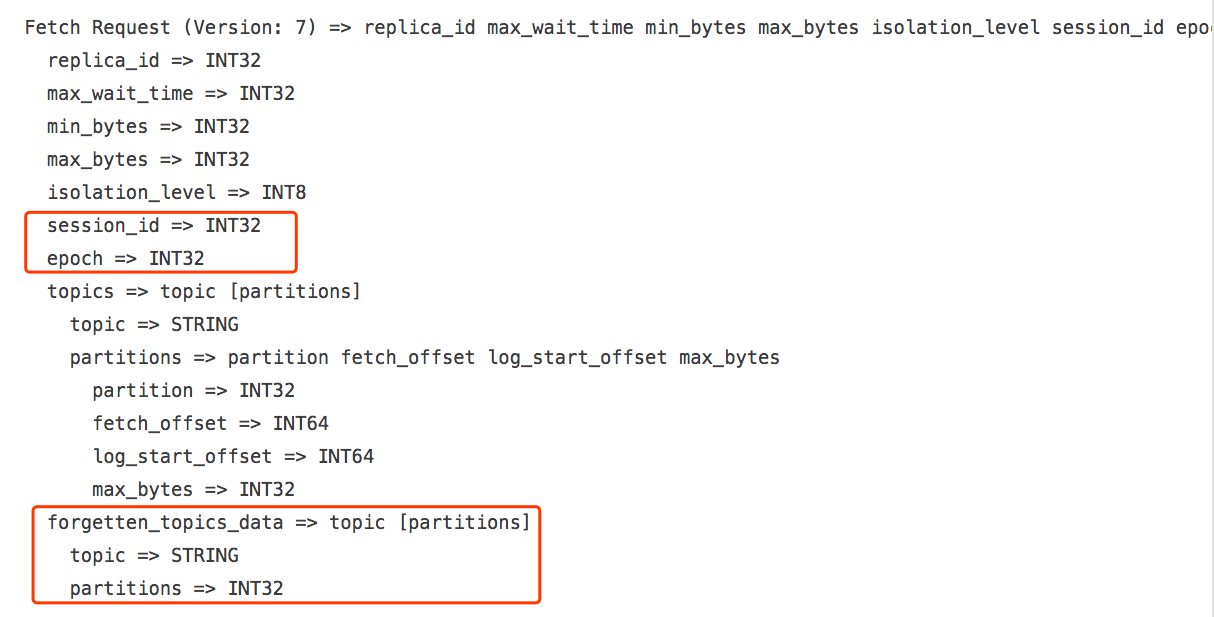
V7与V6版本的差异我已经用红框标识出来了,即在V7版本中新引入了3个主要的变化:session_id/epoch和forgetten_topics_data,其中session_id和epoch合称为fetch session元数据。这里面的fetch session即是1.1.0版本关于FETCH请求的最大变化。一个FETCH SESSION本质上封装了一个fetcher线程的状态,broker端会缓存若干个session在内存中,然后通过FETCH response把相应的状态发送给clients端,这样clients就能知晓当前这个fetcher的状态,从而避免每次FETCH请求中都重复性地请求无意义的数据。
在引入这个变化后,FETCH请求被分成了两类:FULL FETCH请求和Incremental FETCH请求。在首次发送FETCH请求或当session状态发生变化的时候,clients依然发送和以往类似的完整FETCH请求——也就是所谓的FULL FETCH请求,而一旦session稳定下来,且没有变更,那么clients就能安全地发送“瘦身后”的FETCH请求,即增量式FETCH请求,从而起到节省带宽的作用。
上面测试场景中第二张图的MAX值就是FULL FETCH请求的大小(即12043B),如果我们和图1的FETCH请求大小(12031B)做比较会发现V7版本中FULL FETCH请求比之前V6版本的多了12字节(12043 - 12031),这12个字节就是session_id(4B), epoch(4B)和空forgetten_topics_data数组(4B)所占用的内存空间。
FULL FETCH请求的完整格式如下:
{replica_id=1,max_wait_time=500,min_bytes=1,max_bytes=10485760,isolation_level=0,session_id=0,epoch=0,topics=[{topic=test,partitions=[
{partition=0,fetch_offset=0,log_start_offset=0,max_bytes=1048576},
{partition=1,fetch_offset=0,log_start_offset=0,max_bytes=1048576},
...
{partition=999,fetch_offset=0,log_start_offset=0,max_bytes=1048576}
]}], forgotten_topics_data=[]}
由此可见在FULL FETCH请求中session_id和session的epoch都是0。一旦发现这些分区的FETCH session没有变化,clients会自动切换成发送增量式FETCH请求,其格式如下:
{replica_id=1,max_wait_time=500,min_bytes=1,max_bytes=10485760,isolation_level=0,session_id=1253124317,epoch=1,topics=[],forgotten_topics_data=[]}
如果我们验证增量式FETCH请求的大小,可以很容易地计算出其大小=4B(replica_id) + 4B(max_wait_time) + 8B(min_bytes&max_bytes)+ 1B(isolation_level)+ 4B (session_id) + 4B(epoch) + 4B(空topics数组) + 4B(空forgotten_topics_data数组)=33字节,与图2中稳定后的FETCH请求大小正好吻合!
综上所说,Kafka在1.1.0版本引入了FETCH session的概念以期望减少FETCH请求对于网络带宽的占用,从实际使用角度而言,这种减少对于超大规模的集群是有明显提升的,而对于一般的小集群其优化的效果则并非那么显著。不过鉴于这是对用户透明的性能提升,故总然是一件好事情~~