本文将从以下五个方面初识Kafka:
一. Kafka组件介绍
二. 消费者消费的条件
三. Kafka与ActiveMQ的区别
四. Kafka如何保证数据不丢失
五. Kafka的深入学习
一. Kafka组件介绍
1.producer 生产者 会把数据源写入kafka集群中
2.broker kafak服务器, 一个broker就是kafka集群的节点,可以存放数据
3.topic 消息的主题, 是一类消息的集合
4.partition 分区概念 一个topic有多个分区,提高并行处理的效率
5.replication 副本 一个分区可以设置多个副本,副本保证数据的安全性
6.segment 每一个分区数据都有很多个segment
一个segment都有2个文件: ①.log文件(是topic数据存储的文件) ②.index文件(是.log文件索引文件,快速定位某一分区上次消息消费到哪里了,然后往后继续消费)
7.zookeeper 通过zk保存kafka集群元数据信息, 这些元数据信息包括: kafka集群地址,有哪些topic,以及每一个topic的分区数等信息.
8.consumer 消费者 消费者去kafka集群中拉取数据然后进行消费
9.offset 消息的偏移量 保存消息消费到哪里了,把消息消费的数据记录.当前这个记录信息叫做offset偏移量
消息偏移量保存有2种方式: ① 由kafka自己去保存 ② 由zookeeper去保存
二. 消费者消费的条件
1. 消费的topic
2. Zookeeper集群
3. 消息offset的偏移量, kafka集群可以自己记录,不用手动处理
三. Kafka与ActiveMQ的区别
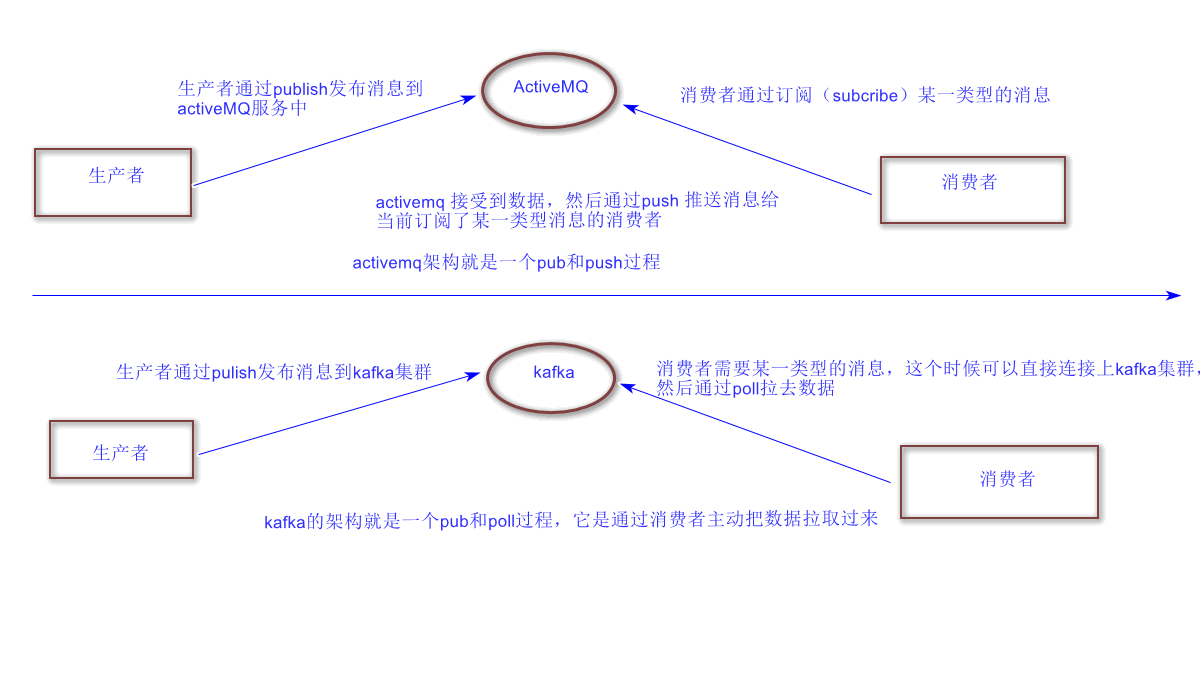
四. Kafka如何保证数据不丢失
Kafka从以下三个方面来保证数据的不丢失
1. Producer
① ack机制-同步模式: 每次发送一条数据,每条数据都需要确认,效率比较低,但是数据安全
producer.type=sync (同步模式)
request.required.acks=1
② ack机制-异步模式: 通过buffer来进行控制数据的发送,有两个值来进行控制,时间阈值与消息的数量阈值,如果buffer满了数据还没有发送出去,若设置的是立即清理模式,风险很大,一定要设置为阻塞模式。
2.Broker
一个topic有很多个分区,每一个分区有很多个副本,可以通过副本保证数据的安全性
3.Consumer
针对每一个消费者在消费数据的时候,都会把当前消费的偏移量保存在kafka集群或者zookeeper,当前消费者挂了,再次重启,重启之后可以读取上一次消费的偏移量,然后继续消费
五. 关于Kafka的深入学习
关于Kafka深入学习视频, 如Kafka领导选举, offset管理, Stream接口, 高性能之道, 监控运维, 性能测试等,
请关注个人微信公众号: 求学之旅, 发送Kafka, 即可收获Kafka学习视频大礼包一枚。
