整体架构图:
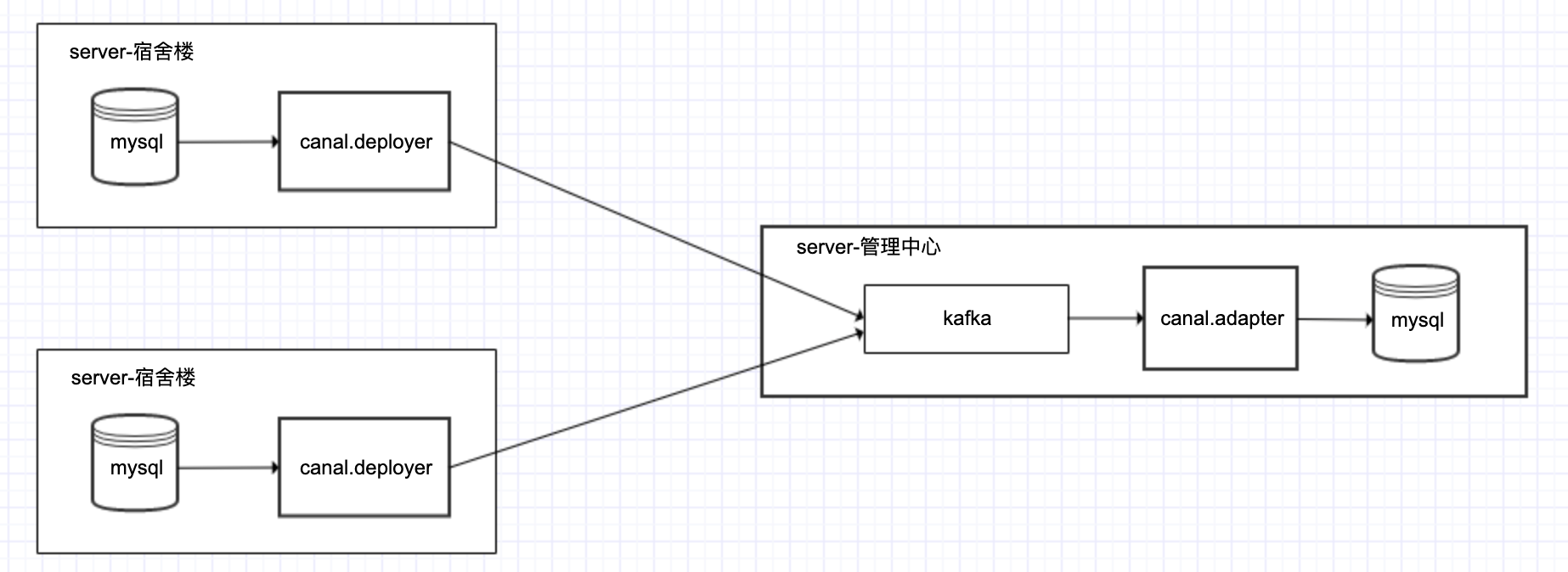
canal.depoyer端配置
1、mysql开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复2、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES;
3、配置canal.deployer 将canal server接收到的binlog数据直接投递到MQ
参考文档:https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
下载 https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
解压canal.deployer-1.1.5.tar.gz 后结构如下:

a、修改canal 配置文件 conf/canal.properties
# tcp, kafka, rocketMQ, rabbitMQ canal.serverMode = kafka .......... ################################################## ######### Kafka ############# ################################################## kafka.bootstrap.servers = 127.0.0.1:9092 #修改成实际的kafka地址 kafka.acks = all kafka.compression.type = none kafka.batch.size = 16384 kafka.linger.ms = 1 kafka.max.request.size = 1048576 kafka.buffer.memory = 33554432 kafka.max.in.flight.requests.per.connection = 1 kafka.retries = 0 kafka.kerberos.enable = false kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf" kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
b、修改instance 配置文件 conf/example/instance.properties
# 按需修改成自己的数据库信息 ################################################# ... canal.instance.master.address=127.0.0.1:3306 # username/password,数据库的用户名和密码 ... canal.instance.dbUsername = canal canal.instance.dbPassword = canal ...
#table regex
canal.instance.filter.regex=sam_cms\..* #配置哪个数据库需要同步
# mq config
canal.mq.topic=sam_cms
4、启动
sh bin/startup.sh
配置canal.adapter
1、下载 canal.adapter
https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.adapter-1.1.5.tar.gz
解压后目录结构
2、配置canal.adapter 接收kafka 消息,把数据同步到mysql
参考文档:https://github.com/alibaba/canal/wiki/ClientAdapter
a、修改 conf/application.yml
canal.conf: mode: kafka #tcp kafka rocketMQ rabbitMQ consumerProperties: # kafka consumer kafka.bootstrap.servers: 192.168.0.103:9092 #实际地址 canalAdapters: - instance: sam_cms # canal instance Name or mq topic name groups: - groupId: g1 outerAdapters: - name: logger - name: rdb key: mysql1 properties: jdbc.driverClassName: com.mysql.jdbc.Driver jdbc.url: jdbc:mysql://127.0.0.1:3306/sam_cms?useUnicode=true jdbc.username: root jdbc.password: 123456
b、修改配置文件 /conf/rdb/mytest_user.yml
destination: sam_cms #cannal的instance或者MQ的topic groupId: g1 #对应MQ模式下的groupId, 只会同步对应groupId的数据 outerAdapterKey: mysql1 #adapter key, 对应上面配置outAdapters中的key concurrent: true #是否按主键hash并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!! dbMapping: mirrorDb: true database: sam_cms #源数据源的database/shcema
3、启动
bin/startup.sh