本文主要介绍了如何对MsCelebV1-Faces-Aligned.tsv文件进行提取
原创by南山南北秋悲
欢迎引用!请注明原地址 http://www.cnblogs.com/hwd9654/p/6796811.html 谢谢!
最近用caffe做人脸识别,一开始用lfw作为数据库,但是体量太小,只有五千多人的图片
后来想用李子青组的casia-webface,从网上找了个,下下来发现居然损坏了,好气啊! 想去官网申请,却发现!!!:
- Sign the agreement (The agreement must be signed by the director or the delegate of the deparmart of university. Personal applicant is not acceptable.
。。。。。。不接受个人申请,而lz的学院领导不给签字 - -
后来索性就直接拿微软的ms celeb 1m来训练
简介如下:官网地址(https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/)
MSR IRC是目前世界上规模最大、水平最高的图像识别赛事之一,由MSRA(微软亚洲研究院)图像分析、大数据挖掘研究组组长张磊发起
ms_celeb_1m就是这个比赛的数据集
从1M个名人中,根据他们的受欢迎程度,选择100K个。然后,利用搜索引擎,给100K个人,每人搜大概100张图片。共100K*100=10M个图片。
有三种下载选项:
1.完整版
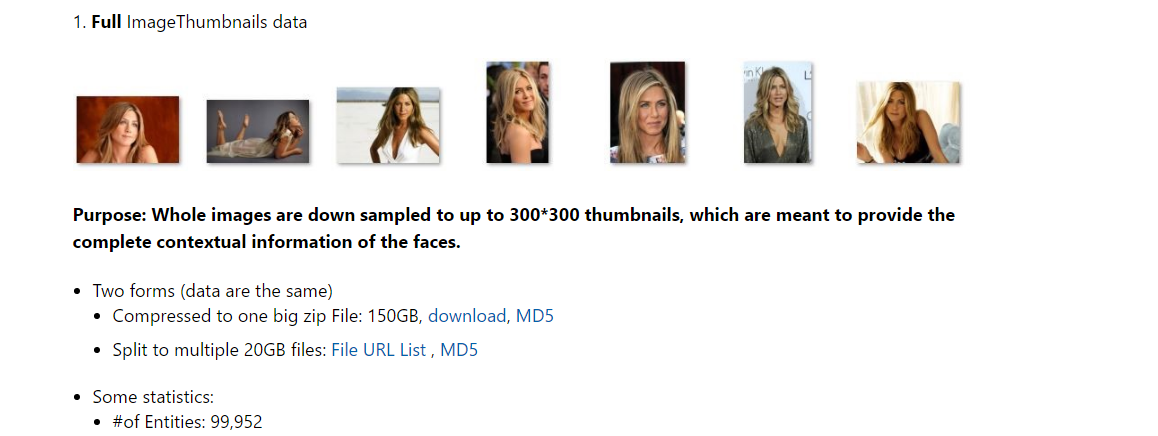
需要自己预处理,人脸检测,人脸对齐。。。
2.微处理版,修剪了一下
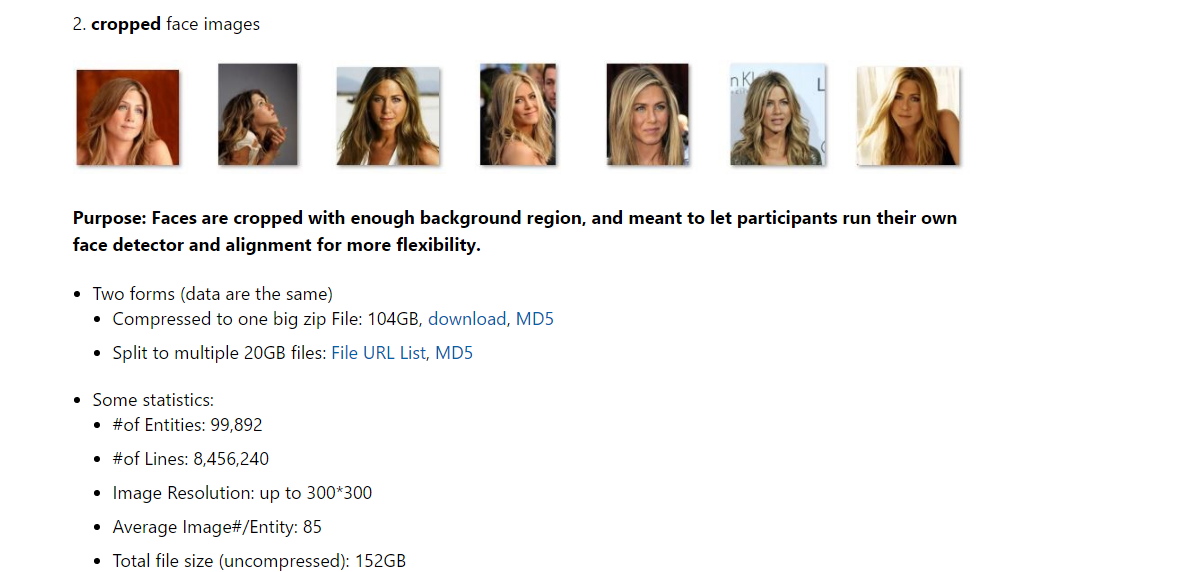
3.对齐过的版本
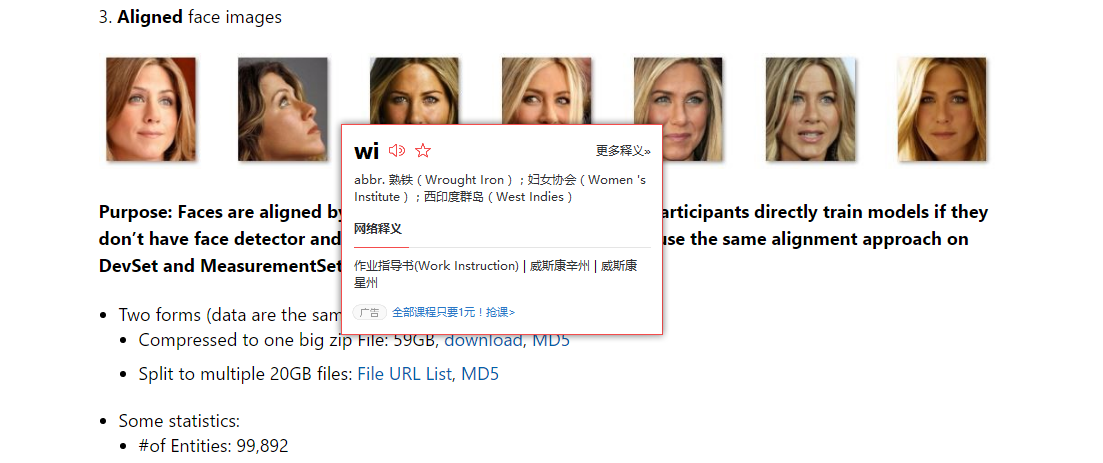
楼主用的是第三个对齐过的版本
下载下来是这么个玩意儿

好了废话不多说
直接上处理脚本
import base64 import csv import os filename = "J:datasetms_celeb_1mMsCelebV1-Faces-Aligned.tsv" outputDir = "I:ms_celeb_1m" with open(filename, 'r') as tsvF: reader = csv.reader(tsvF, delimiter=' ') i = 0 for row in reader: MID, imgSearchRank, faceID, data = row[0], row[1], row[4], base64.b64decode(row[-1]) saveDir = os.path.join(outputDir, MID) savePath = os.path.join(saveDir, "{}-{}.jpg".format(imgSearchRank, faceID)) if not os.path.exists(saveDir): os.mkdir(saveDir) with open(savePath, 'wb') as f: f.write(data) i += 1 if i % 1000 == 0: print("Extracted {} images.".format(i))
自己改下相应路径就可以用了
处理结果:

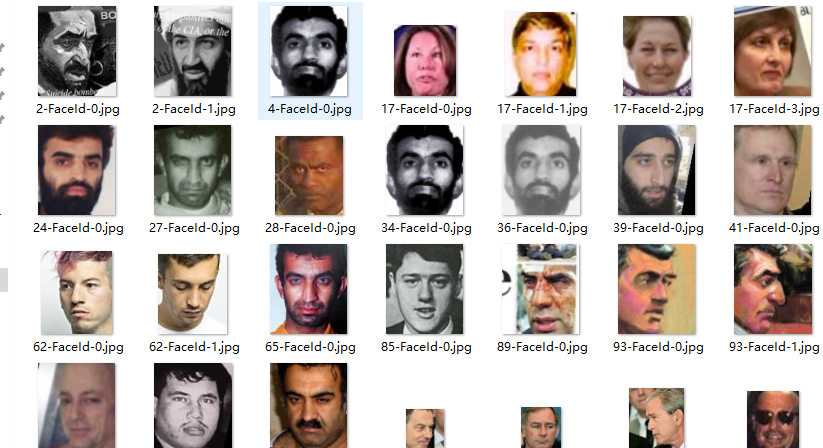
有什么疑问可以留言,不定期查看,慢回勿喷。。。