一、系统配置
3台虚拟机
hadoop1: 4g内存 2核 80g硬盘
hadoop2 2g内存 1核 12g硬盘
hadoop3: 2g内存 1核 12g硬盘
client: 1g内存 1核 12g硬盘
二、scala安装
1、下载scala-2.12.8.tgz安装包
curl -O https://www.scala-lang.org/files/archive/scala-2.12.8.tgz
2、远程传输到hadoop2、hadoop3、client节点上
scp scala-2.12.8.tgz root@hadoop2:`pwd`
scp scala-2.12.8.tgz root@hadoop3:`pwd`
scp scala-2.12.8.tgz root@client:`pwd`
3、解压安装文件
tar zxvf scala-2.12.8.tgz
4、添加环境变量
#scala配置
SCALA_HOME=/usr/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
5、安装验证

二、spark集群安装
1、下载spark-2.4.5-bin-without-hadoop.tgz安装包
curl -O https://mirror.bit.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop.tgz
2、远程传输到hadoop2、hadoop3、client节点上
scp spark-2.4.5-bin-without-hadoop.tgz root@hadoop2:`pwd`
scp spark-2.4.5-bin-without-hadoop.tgz root@hadoop3:`pwd`
scp spark-2.4.5-bin-without-hadoop.tgz root@client:`pwd`
3、解压安装包
tar zxvf spark-2.4.5-bin-without-hadoop.tgz
4、编辑配置文件
/usr/local/softwareinstall/spark-2.4.5/conf
(1)slaves
mv slaves.template slaves
vim slaves
添加如下配置
hadoop2
hadoop3

(2)spark-env.sh
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
添加如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_172
export SCALA_HOME=/usr/scala-2.12.8
#master节点ip
export SPARK_MASTER_IP=hadoop1
#应用程序提交端口
export SPARK_MASTER_PORT=7077
#每个worker节点管理的内存数
export SPARK_WORKER_MEMORY=2g
#每个worker节点管理的cores数
export SPARK_WORKER_CORES=3
export SPARK_MASTER_WEBUI_PORT=8888
当使用不含hadoop的安装文件配置时(xxx--without-hadoop.tgz),还需要添加如下配置,告知spark关于hadoop的安装信息
export SPARK_DIST_CLASSPATH=$(/usr/local/softwareinstall/hadoop-3.1.3/bin/hadoop classpath)
参考:Using Spark's "Hadoop Free" Build
5、重命名spark集群启动脚本名称(/usr/local/softwareinstall/spark-2.4.5/sbin/start-all.sh)
避免与hadoop的start-all.sh脚本(启动hdfs、yarn集群)冲突
mv start-all.sh start-spark.sh
6、添加环境变量
vim /etc/profile
添加如下配置
#spark环境变量配置
SPARK_HOME=/usr/local/softwareinstall/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/sbin
source /etc/profile #使修改生效
7、启动spark集群
./sbin start-spark.sh
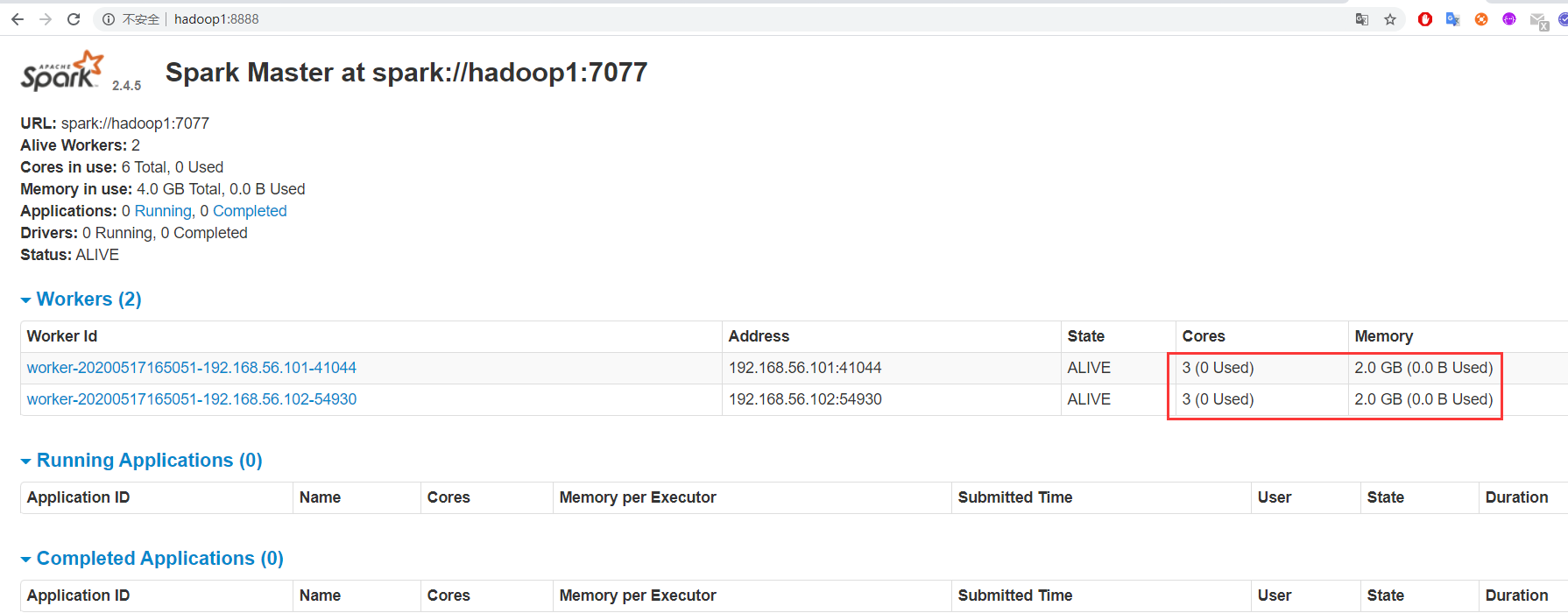
8、ui界面观察
hadoop1:8888
参考:
(1)spark2.4.5
http://spark.apache.org/docs/latest/