2019-09-10 19:46:07
问题描述:Seq2Seq模型引入注意力机制是为了解决什么问题?为什么选择使用双向循环神经网络模型?
问题求解:
在实际任务中使用Seq2Seq模型,通常会先使用一个循环神经网络作为编码器,将输入序列编码成一个向量表示;然后再使用一个循环神经网络模型作为解码器,从编码器得到的向量表示里解码得到输出序列。
这里计算当前隐状态的时候只考虑了上一个隐状态和上一个输出词。
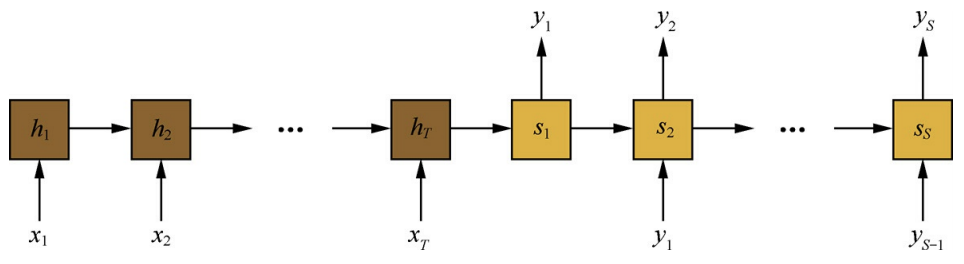
这里有个问题,就是随着输入序列的增长,模型的性能发生了显著下降。这是因为编码时输入序列的全部信息压缩到了一个向量中表示。随着序列的增长,句子越前面的词的信息丢失就越严重。
试想翻译一个有100个词的句子,需要将整个句子全部词的语义信息编码在一个向量中。而在解码的时候,目标语言的第一个词大概率是和源语言的第一个单词对应的,这就意味着第一步的解码就需要考虑100步之前的信息,这个信息是很难维护的,可以用LSTM来缓解,但是本质问题并没有解决。换个角度思考,如果人去翻译一个句子,是会先把一个长句子整个看完再翻译呢,还是先一段段的翻译呢?我想在非常长的句子的时候,一般人都是从前到后一段段的翻译的吧,这个思想其实和注意力机制不谋而合。
Seq2Seq中加入的attension机制就是为了解决上述的问题,在注意力机制中,当前的隐状态不仅仅和上一个隐状态,上一个输出词有关,还有一个语境向量ci相关。
![]()
其中语境向量是全部隐状态的加权和。

这里的alpha就是attention,这个是由神经网络计算得到的权重值,这里的alpha的值其实就是上一个隐状态和每一个hk的通过一个神经网络 a 计算了相关性,然后过了一个softmax归一化。
![]()
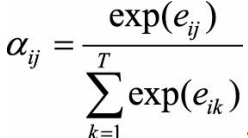
注意力机制是一种思想,上述的实现只是一种方式。在Transformer出现后,又提出了self-attension,本质上也是计算相关性,道理上是想通的。