爬前叨叨
已经编写了33篇爬虫文章了,如果你按着一个个的实现,你的爬虫技术已经入门,从今天开始慢慢的就要写一些有分析价值的数据了,今天我选了一个《掘金网》,我们去爬取一下他的全站用户数据。
爬取思路
获取全站用户,理论来说从1个用户作为切入点就可以,我们需要爬取用户的关注列表,从关注列表不断的叠加下去。
随便打开一个用户的个人中心

绿色圆圈里面的都是我们想要采集到的信息。这个用户关注0人?那么你还需要继续找一个入口,这个用户一定要关注了别人。选择关注列表,是为了让数据有价值,因为关注者里面可能大量的小号或者不活跃的账号,价值不大。
我选了这样一个入口页面,它关注了3个人,你也可以选择多一些的,这个没有太大影响!https://juejin.im/user/55fa7cd460b2e36621f07dde/following
我们要通过这个页面,去抓取用户的ID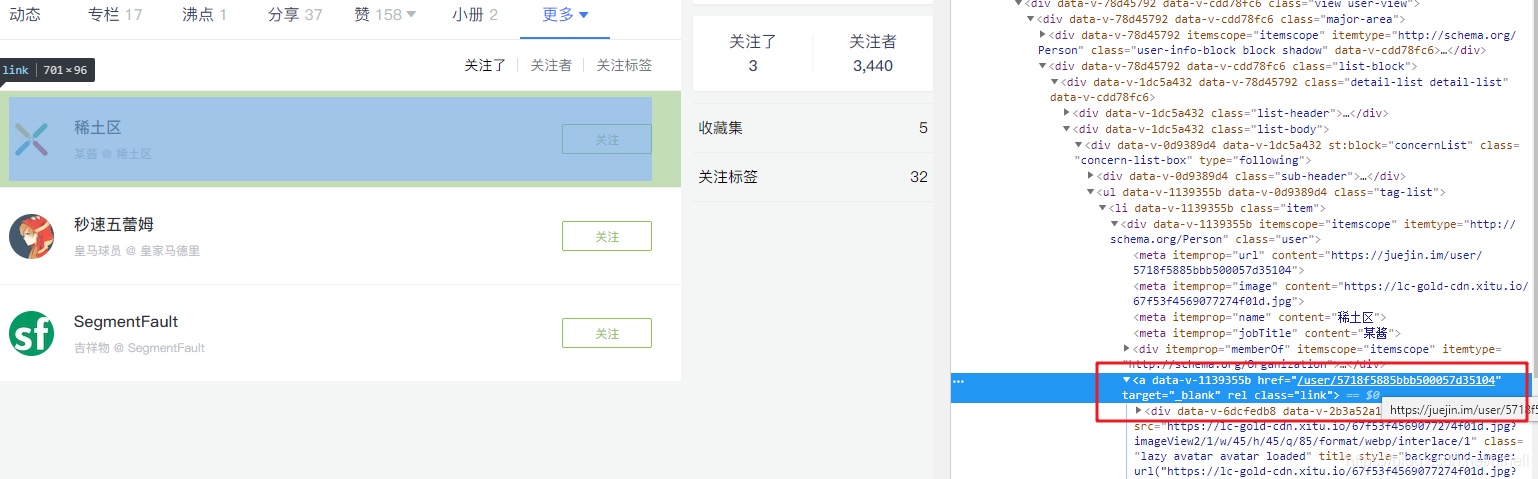
得到ID之后,你才可以拼接出来下面的链接
https://juej