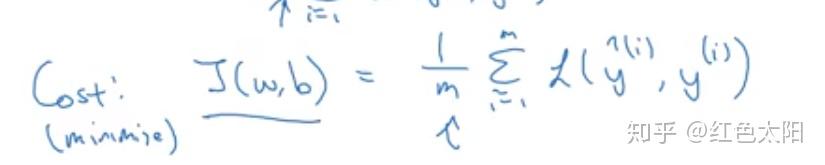2.1二元分类(binary classification)
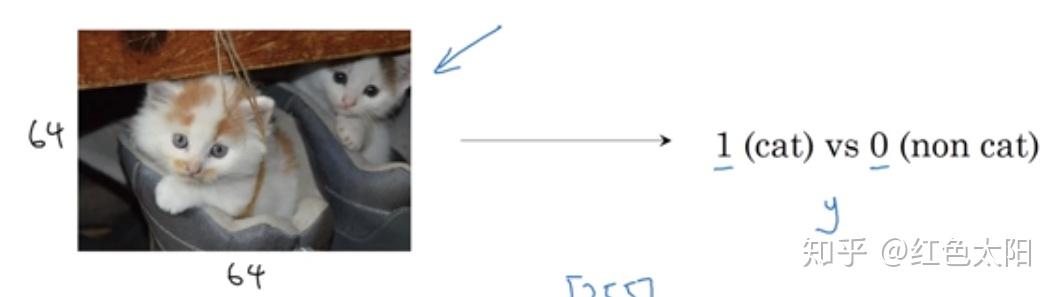
现有一张图片,大小为:64*64像素。标签为:是猫则标1,不是猫则标0.
小知识:图片在计算机中如何表示
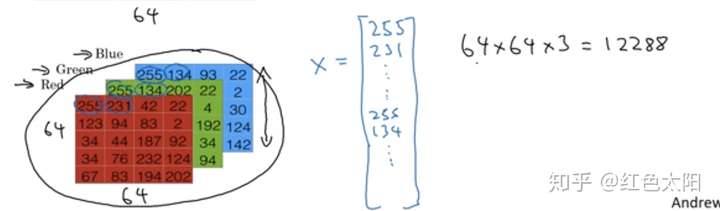
保存一张图片需要三个矩阵,它们分别对应图中的红、绿、蓝三种颜色通道。若图片大小为64*64像素,那么就有三个64*64的矩阵,这三个矩阵表示图片红色,绿色,蓝色的像素强度值分别是多少。为了方便理解,现在有一个大小为54像素的图片如上图。为了方便表示,需要将三个矩阵放入一个向量中,先去红色,再取绿色,最后取蓝色,因此就形成了一个大向量,若图片大小为64*64像素,那么向量的维度为(64*64*3,1)。
关于数据集的符号约定
将数据向量化处理:
2.2 logistic regression
对于一个二元分类问题:给定一个输入特征向量来表示一张图片,识别这张图片是猫( )或者不是猫(
)。
算法思路:
给定一个向量 ,输出为
,这是一个预测值,针对这一问题,我们将其定义为:输入一张图片的特征向量
,那么这张图片是猫也就是
(数据的标签)的概率,数学表达为:
一些符号定义:
求解方法:
- 法一:线性回归
实际上这是行不通的,原因是: 的取值范围是0到1,而上述式子取值为正无穷到负无穷。
- 法二:将线性函数转化为非线性
这里采用Sigmoid非线性函数。
关于Sigmoid函数:
- 公式:
- 图形

- 一些性质
z=0时,对应值为0.5;z趋于正无穷时,值为1;z趋于负无穷大时,值为0。
2.3 logistic regression cost function

为了让模型通过有标签的样本调整权重向量W和偏差b,需要定义一个函数来衡量 之间的差距,上图中,上角标
。
- 损失函数
用来衡量单个样本的预测值 和实际值
有多接近。
常见的损失函数有:
但是在logistic regression中学习参数的过程中,优化目标是非凸的,只能找到多个局部最优值,采用梯度下降法很可能找不到全局最优解。
在logistic regression中采用的损失函数为:
采用损失函数学习参数的过程中是希望损失函数尽可能的小,这里给出采用这个损失函数的简要说明:
1.当 时,
,若要损失函数尽可能小,则
趋近于1.
2.当 时,
,若要损失函数尽可能小,则
趋近于0。
- 代价函数
损失函数是在单个训练样本中定义的,衡量的是算法在单个样本中的表现情况。为了衡量算法在整个训练集中的表现,需要定义代价函数。
假设训练集有 个样本,则代价函数为:
在训练logistic regression时就是通过将代价函数最小从而学到参数 。
2.4 梯度下降法
算法朝着最陡的方向更新参数,也就是朝着梯度的方向更新参数。

训练算法的目的就是通过找到上图曲面的最小值,从而得到参数 。这是一个凸函数,采用梯度下降算法可以找到最小值。
现只考虑W来具体讲述梯度下降算法。

这时采用梯度下降算法来更新参数W,只要算法收敛前就重复执行下面的程式。
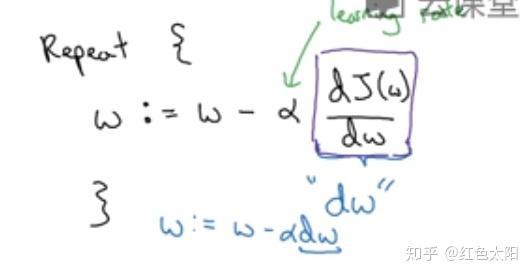
其中 为学习率,用来控制步长,也就是向着梯度方向走一步的长度。
当两个参数都考虑时,也就是在 的曲面上找全局最优解,参数更新如下。

2.7 计算图
从一个简单例子说起:

画出计算图:

验证是否画对:
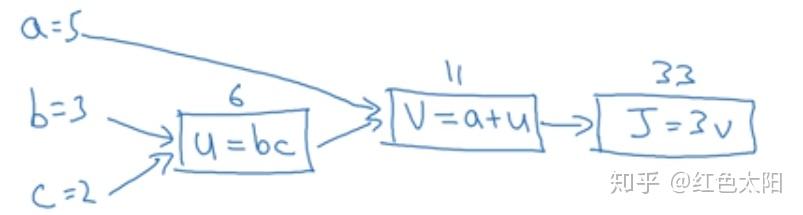
实际值为 ,因此画对了。
在采用梯度下降算法时,需要用到导数,这就需要反向传播,从而更新参数。
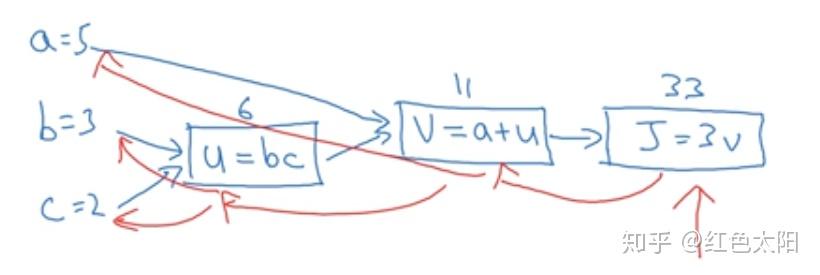
上面讲述了从左到右的计算过程,也就是正向传播;下面将讲述反向传播过程,这是在计算导数。
反向传播计算导数:
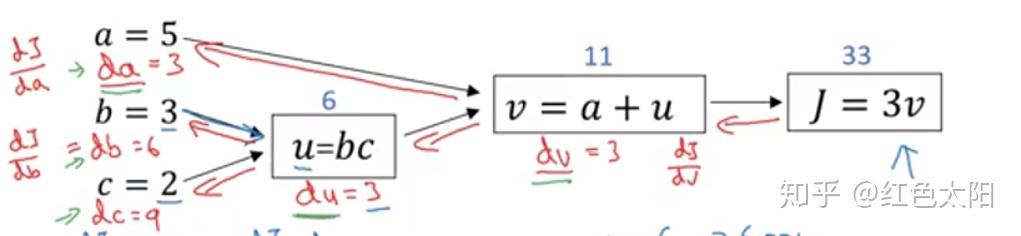
2.8 Logistic Regression 中的梯度下降法
以单个样本为例说明
引入一些变量对模型进行分解来画出计算图:

假设样本只有两个特征 ,则有
。
正向传播:
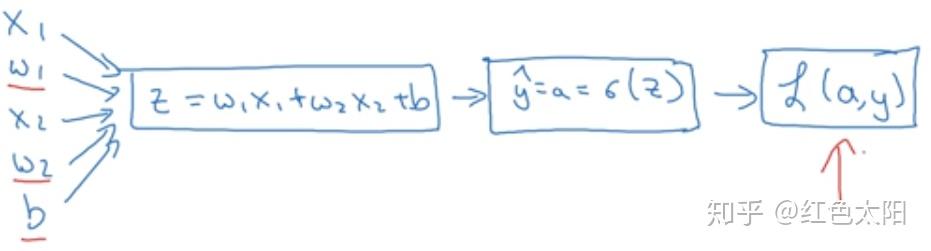
反向传播计算导数:

由于需要学习的参数是w和b,因此,x的导数不用计算,计算结果如下:

更新参数:
2.8 m个样本的梯度下降法
前面介绍了单个样本的梯度下降法,现在介绍m个样本的梯度下降法。
现知道m个样本的损失也就是代价函数,其实这也就是样本1到m项的各个损失的平均,所以它表示代价函数对权重参数的微分。为此,让算法遍历m个样本以后得到权重参数和偏差参数的微分在m个样本上的总和,然后求其平均值,这个值就是全局梯度值,将其用来更新权重参数和偏差参数就是实现了m个样子的梯度下降法。
具体实现:

最后就是更新参数:

方法缺点
该方法需要用到两个for循环,第一个for循环是一个小循环来遍历m个样本;第二个for循环是一个遍历所有特征的for循环。这里只有两个特征,但是当特征很多时候需要用到for循环。
在深度学习算法中,样本数量很大,特征的数量规模也是很庞大的,因此,for循环是非常低效的,代码可能要花费很长的时间去运行,可以用接下来讲的向量化技术来解决这个问题。
2.9 向量化
作用:消除代码中的for循环。

如果训练样本数量很大或者特征很多,向量化技术非常有必要。
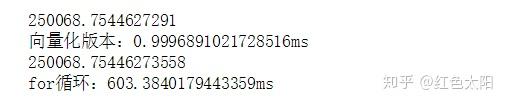
给出向量化技术和非向量化技术运算时间的比较:
import numpy as np #导入numpy库
a = np.array([1,2,3,4])#建立一个数组
print(a)#打印出这个数组
import time #导入时间库
a = np.random.rand(1000000)
b = np.random.rand(1000000)#建立两个一百万维度的数组
tic = time.time() #测量一下当下时间
#下面用分别用向量化版本和非向量化版本来从上面建立的数组进行相同运算从而比较哪种版本的运算更快
# 向量化的版本
c = np.dot(a,b)
toc = time.time()#计算当下的时间(运算结束后的时间)
print(c)#输出运算结果
print("向量化版本:"+ str(1000*(toc-tic))+"ms")#打印向量化版本的时间
#继续增加非向量化版本
c = 0
tic = time.time()#测出程序执行到此处的时间
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()#测出运算结束后的时间
print(c)
print("for循环:" + str(1000*(toc-tic))+"ms")#打印for循环版本的时间最终结果:
2.10 更多向量化的例子
1)将左边转化为右边
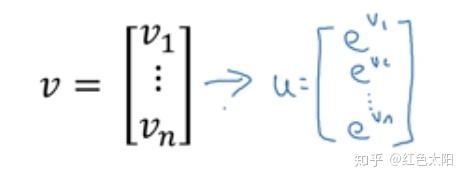
for循环的实现:
u = np.zeros((n,1))
for i in range(n):
u[i] = math.exp(v[i])向量化版本实现:
import numpy as np
u = np.exp(v)2)逻辑回归的向量化
采用for循环时:

将其改为采用向量化实现:

这里采用向量化替代了原来的多个特征采用for循环的实现逻辑,大大提高了算法运行速度。
但是,还有一个遍历样本数量的for循环。
2.11 Logistic Regression正向传播的向量化
当没有采用向量化时候,需要用for循环计算出下图
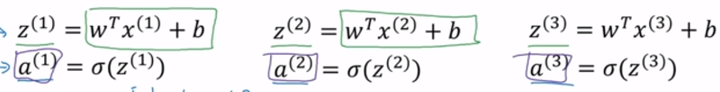
现采用向量化:
step1:设样本集为 ,维度为
,行表示特征维,列表示样本数量。
step2:

上图在python中的实现代码为:
Z = np.dot(w.T,X)+b
step3:

在python中的实现见本周编程作业。
一个小知识:
在step2中的b表示一个数值,但是b是和一个矩阵在相加,我们知道只有同型矩阵才能相加,这里运用了python的广播(brosdcasting)机制。
2.12 Logistic Regression反向传播的向量化
关于
for循环时为:

利用向量化处理则有:
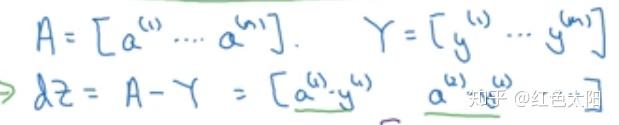
关于权重的梯度:
采用for循环时:

现采用向量化实现:

关于偏差的梯度:
for循环时:
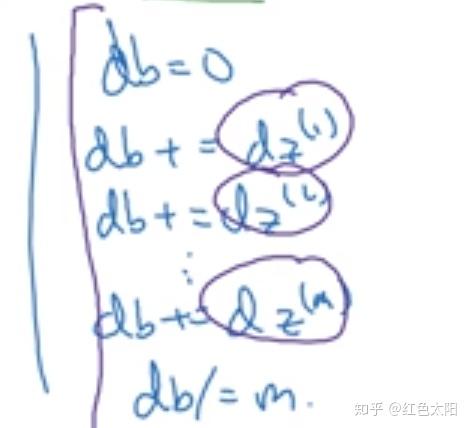
现采用向量化实现:

给出整个逻辑回归的for循环与向量化的对比:

如果我们想要多次对整个样本集使用多次梯度下降,还是需要一个for循环用在最外层。
2.13 python中的广播技术
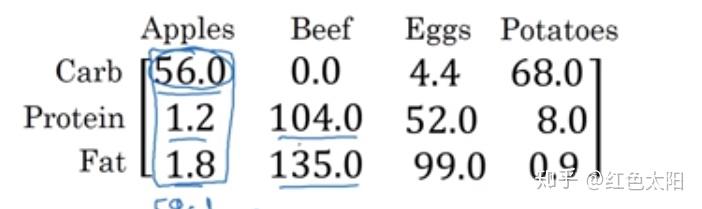
计算上图中,三种营养成分各占该种食物的百分比。
#计算给定食物中三种成分的百分比
import numpy as np
A = np.array([[56.0,0.0,4.4,68.0],
[1.2,104.0,52.0,8.0],
[1.8,135.0,99.0,0.9]])
print(A) 结果:

cal = A.sum(axis=0)#对A的每一列求和
print(cal)结果:

percentage = 100*A/cal.reshape(1,4)#求出各营养成分的百分比
print(percentage)结果:

对于这个程序的一些解释:
1).A.sum(axis = 0)中的axis:用来指明将要进行的运算是沿着哪个轴执行,在numpy中,0是垂直,1是水平,也就是行。
2).A/cal.reshape(1,4)指令则调用了numpy中的广播机制,这里是的矩阵A除以
的矩阵cal。
从技术的角度来说:并不需要将矩阵cal 重塑为
但是当我们不确定矩阵的维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或者行向量。
另一个广播的例子:

上图在python中的实现:

同样有:
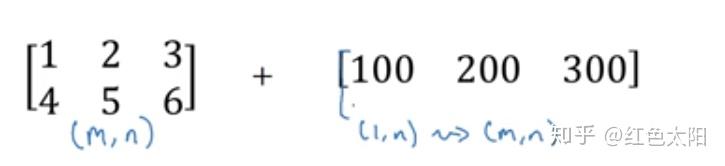
python实现:
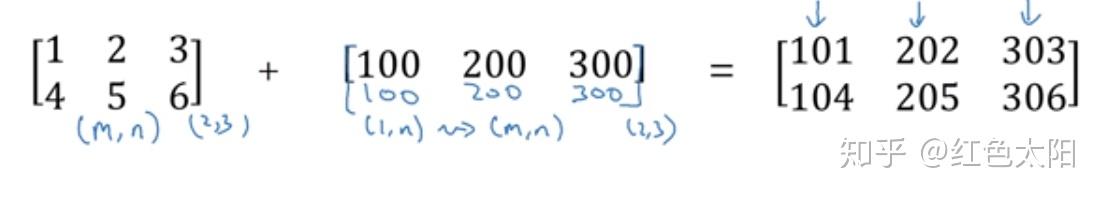
再有:
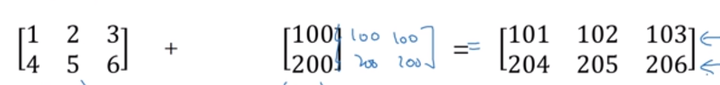
总结:
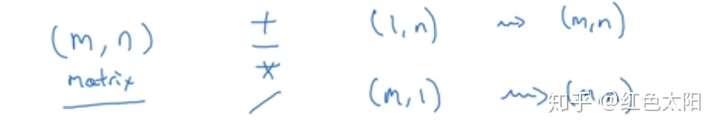
符号前的矩阵为(m,n),则符号后的矩阵扩展为(m,n)。
2.14 关于numpy的说明
本节的重点就是:设置一个数组的时候一定要把维度都设置全,比如要想获得一个 的数组,那么代码为:
a = np.random.randn(5,1)
此外要经常使用断言来看看设置的维度或者计算后的维度是不是我们想要的。

2.15 Logistic Regression的代价函数
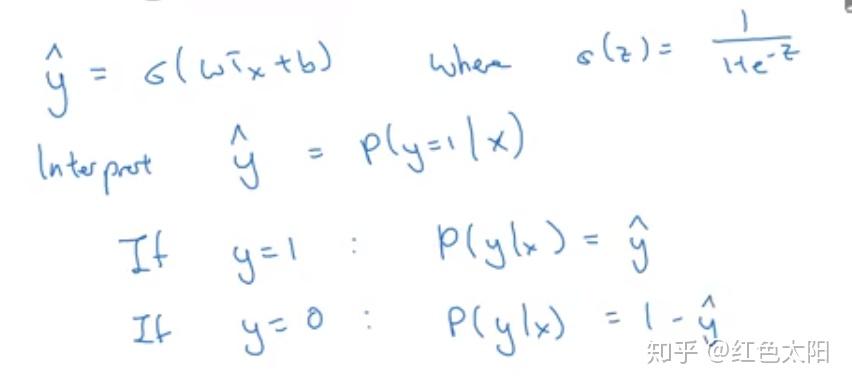
上图是逻辑回归实现的推理过程,现在我们可以将最后两行合并成以下公式:

假设: 表示y=1的概率,那么
就是y=0的概率。
我们自然希望概率越大越好,这样就是算法预测的效果越好。为此我们需要最大化 ,为了更加方便我们对其取对数,则有,最大化
,可以将其写为:
上面等号后面是我们要最大化的,也就是损失函数的相反数。
现在就把问题转化为:最小化损失函数了。这样就可以采用梯度下降法求解损失函数的最小值了从而学得参数:权重矩阵和偏差向量。
上面介绍了单个样本,现在介绍在整个样本上是如何建立代价函数的。
假设:
所有的训练样本服从同一分布且相互独立。
因此则有:
所有样本的概率的乘积就是每个样本概率的乘积:
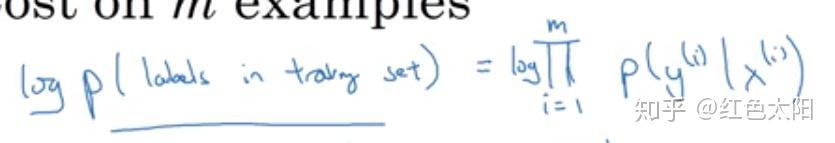
现采用最大似然估计使得给定样本的观测概率值最大:

由于 ,因此在我们采用算法时是在计算目标函数的最小值,所有需要去掉前面的负号,最后为了方便,我用采用平均化,因此对建立的代价函数进行缩放,则有: