本示例使用phpspider作为爬虫,抓取了华尔街见闻部分栏目文章,下面是具体的实现过程。
phpspider 文档:https://doc.phpspider.org/demo-start.html
第一步:使用composer下载phpspider,命令如下:
1 composer require owner888/phpspider
生成的composer.json文件内容如下
1 { 2 "require": { 3 "owner888/phpspider": "^2.1" 4 } 5 }
第二步:在composer.json文件的同级目录下,创建spider.php脚本文件,内容如下:
1 <?php 2 require './vendor/autoload.php'; 3 4 use phpspidercorephpspider; 5 /* Do NOT delete this comment */ 6 /* 不要删除这段注释 */ 7 //看了一下源代码,作者将这注释写到构造函数中了,所以尊重作者意愿,没有去掉,去掉会报错。 8 $configs = array( 9 'name' => '华尔街日报', 10 'domains' => array( 11 'wallstreetcn.com', 12 ), 13 'scan_urls' => array( 14 'http://wallstreetcn.com/' //华尔街见闻网址 15 ), 16 'content_url_regexes' => array( 17 "http://wallstreetcn.com/articles/d+" //华尔街见闻网站文章url模式 18 ), 19 'fields' => array( 20 array( 21 // 抓取内容页的文章内容 22 'name' => "article_content", 23 'selector' => "//*[@class='node-article-content']", //文章内容区域class 24 'required' => true 25 ), 26 // 抓取内容页的文章题目 27 array( 28 'name'=>'article_title', 29 'selector'=>"//*[@class='article__heading__title']", //文章题目区域class 30 'required'=>true 31 ), 32 //抓取内容页文章时间 33 array( 34 'name'=>'article_time', 35 'selector'=>"//*[@class='meta-item__text']", //文章发布时间区域class 36 'required'=>true 37 ), 38 ), 39 //脚本输出类型,输出到数据库 40 'export'=>array( 41 'type'=>'db', 42 'table'=>'articles' //存放文章的数据表 43 ), 44 //数据库连接配置 45 'db_config'=>array( 46 'host'=>'127.0.0.1', 47 'port'=>3306, 48 'user'=>'mysql', //连接数据库的用户名,根据自己环境定义 49 'pass'=>'123456', //连接数据库的密码,根据自己环境定义 50 'name'=>'test' //存放的数据库 51 ), 52 53 ); 54 55 56 $spider = new phpspider($configs); 57 $spider->start();
第三步:创建文章表articles,SQL语句如下:
1 mysql> show create table articles G 2 *************************** 1. row *************************** 3 Table: articles 4 Create Table: CREATE TABLE `articles` ( 5 `id` int(10) unsigned NOT NULL AUTO_INCREMENT, 6 `article_content` text NOT NULL, 7 `article_title` varchar(255) NOT NULL DEFAULT '', 8 `article_time` varchar(64) NOT NULL DEFAULT '', 9 PRIMARY KEY (`id`) 10 ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 11 1 row in set (0.00 sec) 12 13 mysql>
第四步:命令行下运行脚本spider.php
php spider.php
如下图示:
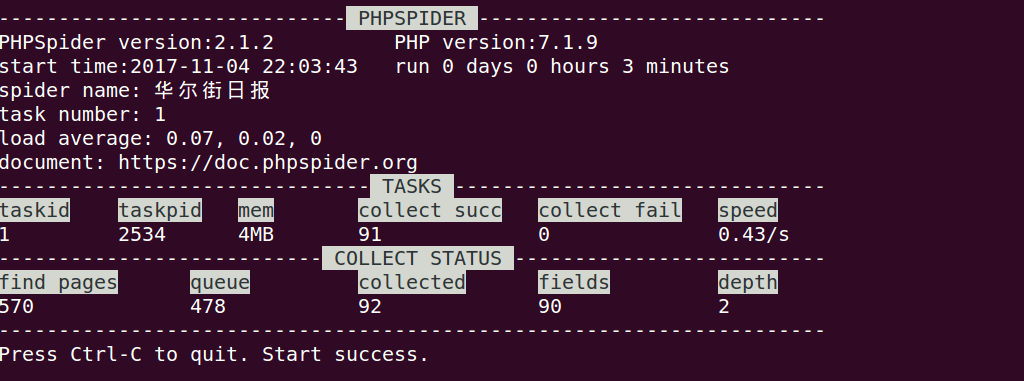
速度还可以,只开启一个任务,三分钟左右就抓取了100文章,如果觉得慢,可以多开几个任务,在spider.php中config数组中配置
注意第一次测试的时候,articles表中article_content使用的类型是varchar,入库后发现文章内容都被截断了,只有部分,后来改为text类型就完整存放下了。
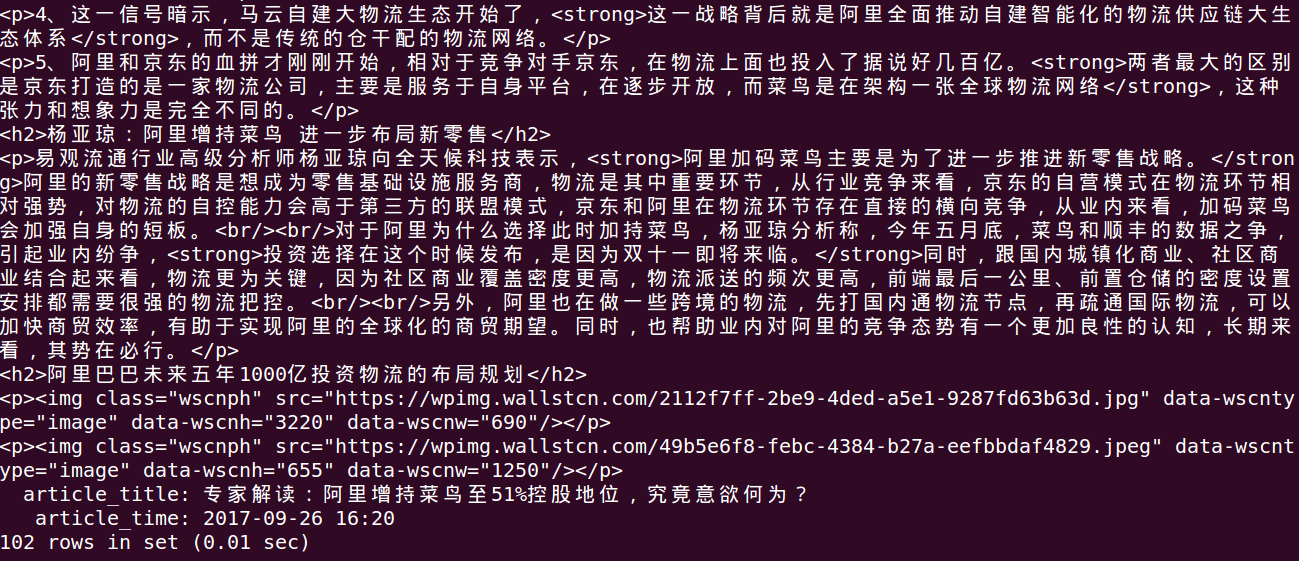
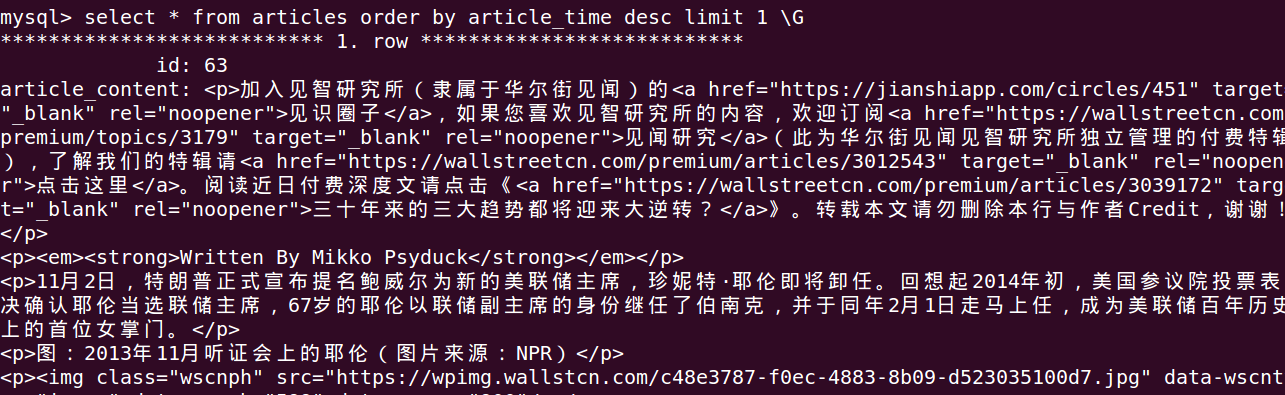
下面是数据抓取入库后的部分截图: