此实验是论文(Byte-level malware classification based on markov images and deep learning)的实现
先将良性和恶意软件转化为256*256的概率矩阵,代码如下:
import PIL.Image as Image, os, sys, array, math
import numpy as np
malware_dir = "D:\android\dataset\drebin-1\"
kind_dir = "D:\android\dataset\Benign_2016\"
malware_save_dir = "D:\dataset\lunwen markov\malware_f\"
kind_save_dir = "D:\dataset\lunwen markov\kind_f\"
def file2arr(file_path,file_save_path): #将文件转换为概率矩阵的方法
fileobj = open(file_path, mode = 'rb')
buffer = array.array('B', fileobj.read())
array1 = np.zeros((256,256), dtype=np.int)
for i in range(len(buffer)-2):
j = i+1
array1[buffer[i]][buffer[j]] += 1
trun_array = np.zeros(256,dtype=np.int)
for i in range(256):
for j in range(256):
trun_array[i] += array1[i][j]
array2 = np.zeros((256,256),dtype=np.float)
for i in range(256):
for j in range(256):
array2[i][j] = array1[i][j]/trun_array[i]
np.save(file_save_path,array1)
count = 1
for file in os.listdir(malware_dir): #最终将概率矩阵二维数组存入
print ("counting the {0} file...".format(str(count)))
count+=1
apk_dir = os.path.join(malware_dir,file)
apk_save_dir = os.path.join(malware_save_dir,file)
file2arr(apk_dir, apk_save_dir)
count = 1
for file in os.listdir(kind_dir):
print ("counting the {0} file...".format(str(count)))
count+=1
apk_dir = os.path.join(kind_dir,file)
apk_save_dir = os.path.join(kind_save_dir,file)
file2arr(apk_dir, apk_save_dir)
基于cnn的马尔可夫图像分类:
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import sys
import cv2
from tensorflow.keras import regularizers
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Activation,Flatten
from tensorflow.keras.layers import Conv2D,MaxPooling2D,BatchNormalization
from tensorflow.keras.optimizers import SGD,Adam,RMSprop
from tensorflow.keras.callbacks import TensorBoard
import sys
from sklearn.datasets import load_digits # 加载手写数字识别数据
import pylab as pl
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler # 标准化工具
from sklearn.svm import LinearSVC
from sklearn.metrics import classification_report # 预测结果分析工具
from tensorflow import keras
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
malware_save_dir = "D:\dataset\lunwen markov\malware\"
kind_save_dir = "D:\dataset\lunwen markov\kind\"
data = []
count = 1
for file in os.listdir(malware_save_dir):
print ("the {0} file...".format(str(count)))
count+=1
output = np.load(os.path.join(malware_save_dir,file))
output2 = keras.preprocessing.image.img_to_array(output)
# output2 = np.expand_dims(output, axis=2) #扩维
# output2 = np.concatenate((output2, output2, output2), axis=-1)
data.append(output2)
count = 1
for file in os.listdir(kind_save_dir):
print ("the {0} file...".format(str(count)))
count+=1
output = np.load(os.path.join(kind_save_dir,file))
output2 = keras.preprocessing.image.img_to_array(output)
# output2 = np.expand_dims(output, axis=2) #扩维
# output2 = np.concatenate((output2, output2, output2), axis=-1)
data.append(output2)
#标签准备
label_mal = [1]*999
label_kind = [0]*1000
labels = label_mal + label_kind
labels = np.array(labels)
import numpy as np
index = np.random.permutation(len(labels))
labels = labels[index]
data_array = data_array[index]
#网络模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(256, 256, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
history = model.fit(data_array, labels, batch_size=32, epochs=50, validation_split=0.2)
除此之外,还参考前几次实验,加入了其他特征,做了多模型实验
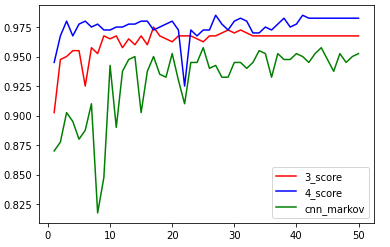
实验结果
基于多模型的四特征分类结果(api,权限,操作码,马尔可夫图像)
[0.945, 0.9675, 0.98, 0.9675, 0.9775, 0.98, 0.975, 0.9775, 0.9725, 0.9725, 0.975, 0.975, 0.9775, 0.9775, 0.98, 0.98, 0.9725, 0.975, 0.9775, 0.98, 0.9725, 0.925, 0.9725, 0.9675, 0.9725, 0.9725, 0.985, 0.9775, 0.9725, 0.98, 0.9825, 0.98, 0.97, 0.97, 0.975, 0.9725, 0.9775, 0.9825, 0.975, 0.9775, 0.985, 0.9825, 0.9825, 0.9825, 0.9825, 0.9825, 0.9825, 0.9825, 0.9825, 0.9825]
基于多模型的三特征(api,权限,操作码)分类结果
[0.9025, 0.9475, 0.95, 0.955, 0.955, 0.925, 0.9575, 0.9525, 0.9675, 0.965, 0.9675, 0.9575, 0.965, 0.96, 0.9675, 0.96, 0.975, 0.9675, 0.965, 0.9625, 0.9675, 0.9675, 0.9675, 0.965, 0.9625, 0.9675, 0.9675, 0.97, 0.9725, 0.97, 0.9725, 0.97, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675, 0.9675]
基于马尔可夫图像的cnn分类结果
[0.87, 0.8775, 0.9025, 0.895, 0.88, 0.8875, 0.91, 0.8175, 0.8475, 0.9425, 0.89, 0.9375, 0.9475, 0.95, 0.9025, 0.9375, 0.95, 0.935, 0.9325, 0.9525, 0.93, 0.91, 0.945, 0.945, 0.9575, 0.94, 0.9425, 0.9325, 0.9325, 0.945, 0.945, 0.94, 0.945, 0.955, 0.9525, 0.9325, 0.9525, 0.9475, 0.9475, 0.9525, 0.95, 0.945, 0.9525, 0.9575, 0.9475, 0.9375, 0.9525, 0.945, 0.95, 0.9525]
结果图: