第一章:数据集群的演化与
早期的服务器架构
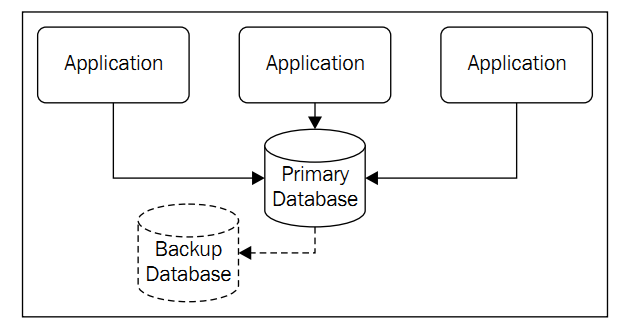
显然,应用是可扩展的,但是由于是集中式服务器,随着数据库性能达到极限,再想扩展就变得极端困难,于是出现了缓存.

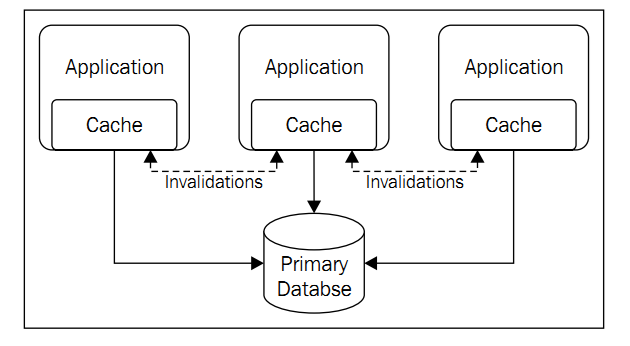
缓存显然再次提升了可扩展性,减轻了数据库的负担.同时也带来了缓存数据同步的问题,书中介绍主要有2种解决办法:
1.时间限制缓存:指定缓存生存期,过期后重新读取(这会有同步问题,但是至少是可控的)
2.直写缓存:数据更新,直接写入数据库,并通知其他缓存该数据无效,这会有读写冲突,并且在读写频繁时性能也大打折扣.
于是,作者引入了
Hazelcast的方式:
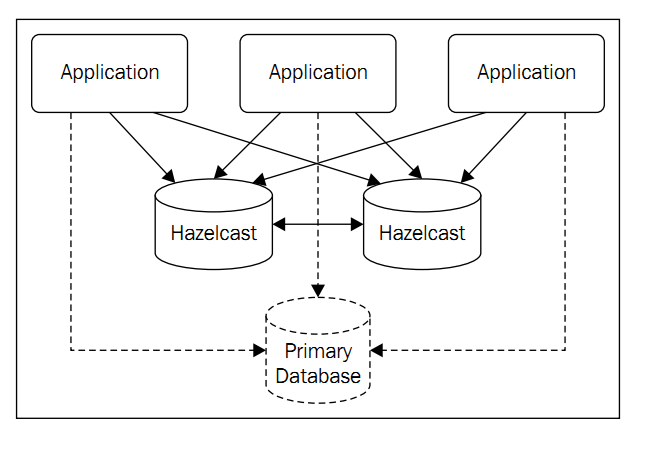
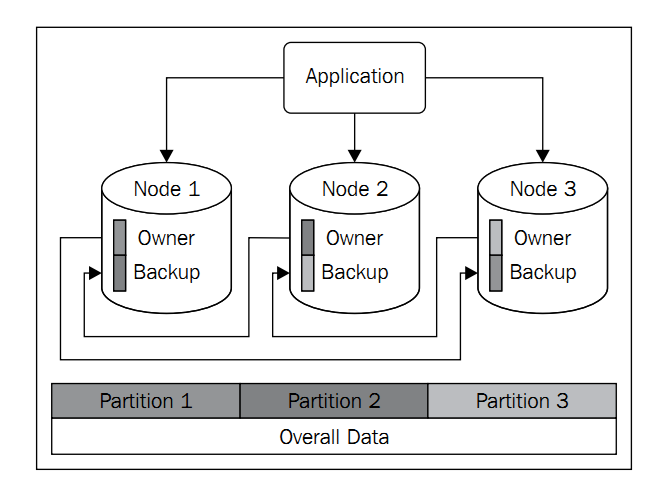
特点:
1.无主节点,活到最久的默认作为leader.
2.纯内存数据,保证了高效性,但是Hazelcast也提供了数据备份(默认支持一台设备意外掉线)
3.每个节点都拥有一部分的数据所有权,这样负载就自动分散开了.(自动切片)
其他功能:


这些.....知道他牛B就好,后面再慢慢看吧....