本文大致梳理了计算机视觉中图像分类的脉络,包括常用数据集、经典模型和性能对比。
1 图像分类常用数据集
以下是几种常用的分类数据集,难度依次递增。列举了各算法在各数据集上的性能排名。
- MNIST,60k训练图像、10k测试图像、10个类别、图像大小1×28×28、内容是0-9手写数字。
- CIFAR-10,50k训练图像、10k测试图像、10个类别、图像大小3×32×32。
- CIFAR-100,50k训练图像、10k测试图像、100个类别、图像大小3×32×32。
- ImageNet,1.2M训练图像、50k验证图像、1k个类别。每年会举行基于ImageNet数据集的ILSVRC竞赛,这相当于计算机视觉界奥林匹克。鉴于图像分类任务上,DL已经超越人类水平,ImageNet挑战赛在2017年是最后一届。
2 图像分类经典结构
基本架构 我们用conv代表卷积层、bn代表批量归一层、pool代表池化层。最常见的网络结构顺序是conv -> bn -> relu -> pool,其中卷积层用于提取特征、池化层用于减少空间大小。随着网络深度的进行,图像的空间大小将越来越小,而通道数会越来越大。当然也有不少其他架构。
两个特点:纵观这些卷积神经网络提高效果的方向,主要是更深、更宽、更多的分支结构和短连接等;AlexNet提出了卷积网络5+3的结构,后续不少经典网络都是在此基础上改进。
经典网络:
- LeNet-5
- AlexNet
- ZF-Net
- GoogLeNet
- VGG
- ResNet
- ResNeXt
- DenseNet
- SENet
2.1 LeNet-5

早期卷积神经网络中最有代表性的架构,是Yann LeCun在1998年设计的,用于手写数字识别的卷积神经网络,当年美国很多银行用它来识别支票上面的手写数字。
2.2 AlexNet
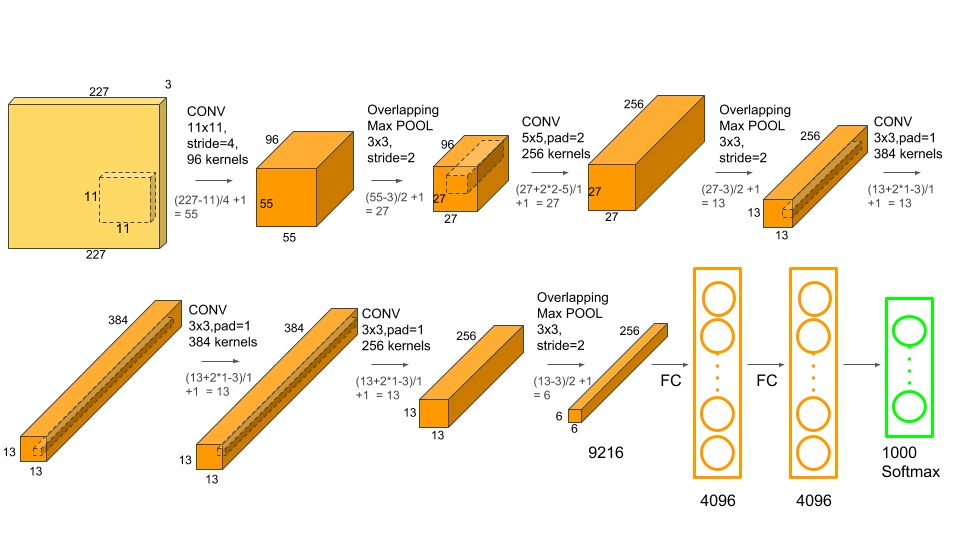
2012年ILSVRC冠军,6千万参数。由于准确率远超传统方法的第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。自此之后,CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。这里有整体架构的可视化和具体的参数。
特点:
- 采用更深的网络结构,为了减弱梯度消失,使用Relu替换之前的sigmoid的作为激活函数;
- 使用Dropout和数据扩充Data Augmentation抑制过拟合;
- 使用Overlapping Pooling(覆盖的池化操作)
- 多GPU训练和LRN(但是没啥用)
2.3 ZF-Net
2013年ILSVRC冠军,结构和AlexNet区别不大,分类效果也差不多。这篇文章的贡献在于,提出了一种CNN特征可视化方法:反池化、反激活、反卷积,从而成为CNN特征可视化的开山之作。
2.4 VGG

2014年ILSVRC亚军网络,1.38亿参数。由于网络结构十分简单,很适合迁移学习,因此至今VGG-16仍在广泛使用。
特点:
- 仍然是5+3结构,只不过用卷积模块代替;
- 小卷积核,小池化核,更深的层,更宽的通道,结构简单规整;
- VGG16内存主要消耗在前两层卷积,而参数在第一层全连接中最多;
- 测试时全连接转卷积,使用了1x1卷积核,省去了AlexNet测试时多次裁剪的麻烦;
- 原论文中无法直接训练深层VGG网络,因此先训练浅层网络,并使用浅层网络对深层网络进行初始化,在BN出现之后才得以直接训练。
2.5 GoogLeNet
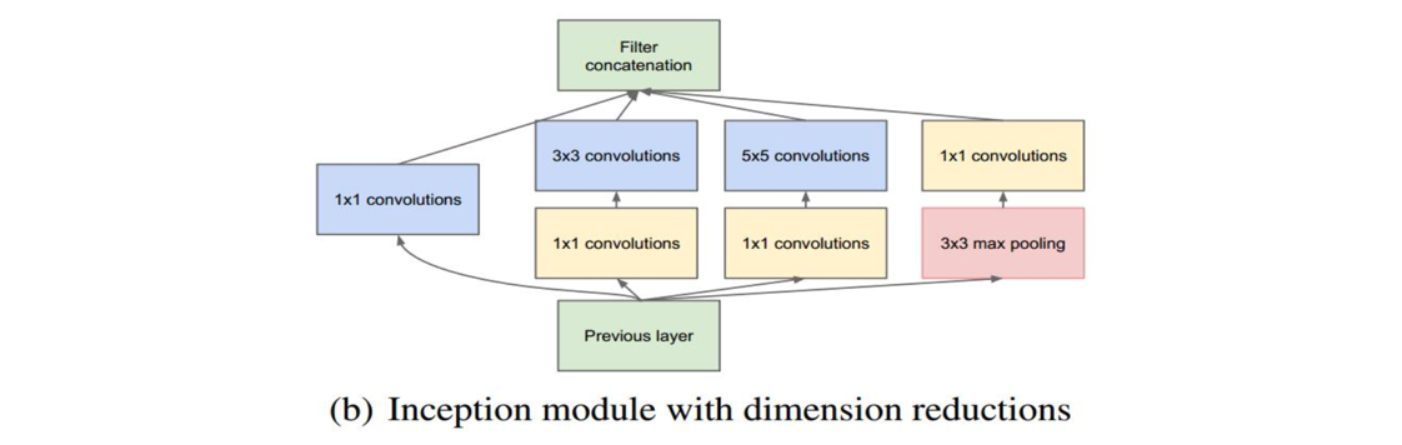
2014年ILSVRC冠军网络。同样也是5+3的模式(以池化层为界),参数量约为5百万,核心模块是Inception Module。Inception历经了V1、V2、V3、V4等多个版本的发展,不断趋于完善。GoogLeNet取名中L大写是为了向LeNet致敬,而Inception的名字来源于盗梦空间中的"we need to go deeper"梗。
Inception V1:加大深度、加大宽度(通过增加分支)、减少参数
深度方面:层数更深,论文采用了22层,为了避免梯度消失问题,GoogLeNet在不同深度处(4b和4e处,以最大池化为界)增加了两个分支,来回传梯度。
宽度方面:采用多分支分别处理然后拼接的Inception Module。
- 用1×1、3×3、5×5、max pooling这四种核并行的方式,让网络自己决定该用什么样的卷积核;
- 采用不同大小的卷积核意味着不同大小的感受野,可以捕捉到不同尺度的信息,最后拼接意味着不同尺度的特征进行信息融合;(不同于2011年Yann LeCun的交通标志识别模型,那个是不同层级特征,这个是不同视野)
- 为了避免concat起来的feature map厚度过大,Inception模块在3×3前、5×5前、max pooling后分别加上了1×1的卷积核,降低feature map厚度。
另外,为了减少参数,网络最后采用了average pooling来代替第一个全连接层,参数可以减少一个数量级。
Inception V2:主要做了两个改动
- 学习VGG网络,将7×7和5×5卷积分解成若干等效3×3卷积;(减少参数同时增加非线性转换)
- 增加了BN层,加快收敛速度,且有一定的正则化效果;(配合其他操作:增大学习率,更彻底的对训练数据进行shuffle,减少数据增广中图像的光学畸变等;要达到V1结构相同的准确率,训练时间只有之前的1/14)
Inception V3:主要在两个方面改造
- 引入Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7×7卷积拆成1×7卷积和7×1卷积。适用于中度大小的feature map,对于m×m大小的feature map,建议m在12到20之间。作用是:1.节约参数,减小计算量,减轻过拟合;2.中间可以加一层relu激活,增加模型非线性表达能力;
- 优化Inception Module的结构。现在模块中有35×35、17×17和8×8三种不同的结构。这些Inception Module只在网络的后部出现,前部还是普通的卷积层。并且还在Inception Module的分支中还使用了分支。
Inception V4:结合了残差神经网络ResNet,进一步降低了0.4%的错误率
2.6 ResNet


2015年ILSVRC冠军网络。核心是带短连接的残差模块,其中主路径有两层卷积核(Res34),短连接把模块的输入信息直接和经过两次卷积之后的信息融合,相当于加了一个恒等变换。短连接是深度学习又一重要思想,除计算机视觉外,短连接思想也被用到了机器翻译、语音识别/合成领域。
结构特点:
- 总体架构:类似5+3结构,第一个模块为普通卷积,第2、3、4、5为模块组,然后经过一个平均池化,直接送到最后一层fc;(注意:GoogleNet中将fc6换成了平均池化层,然后经过fc7,fc8,但是ResNet直接将fc7也省掉了)
- 两种残差模块:除了左图的残差模块,对于很深的网络(超过50层),ResNet使用了更高效的瓶颈结构(BottleNeck)(主路径的第一层和第三层均为1×1卷积,如右图);
- 两路信息融合时:若前后特征图厚度一致,则直接相加;若前后特征图厚度不一致,则用1×1卷积来线性变换(注:前后特征图尺寸不一致时,1×1卷积核的步长为2,起到了下采样的效果);
- 更好的残差模块preResNet:作者在V2中对不同的残差单元做了细致的分析与实验,最优的残差结构如下图所示。改进前后一个明显的变化是采用pre-activation,BN和ReLU都提前了。
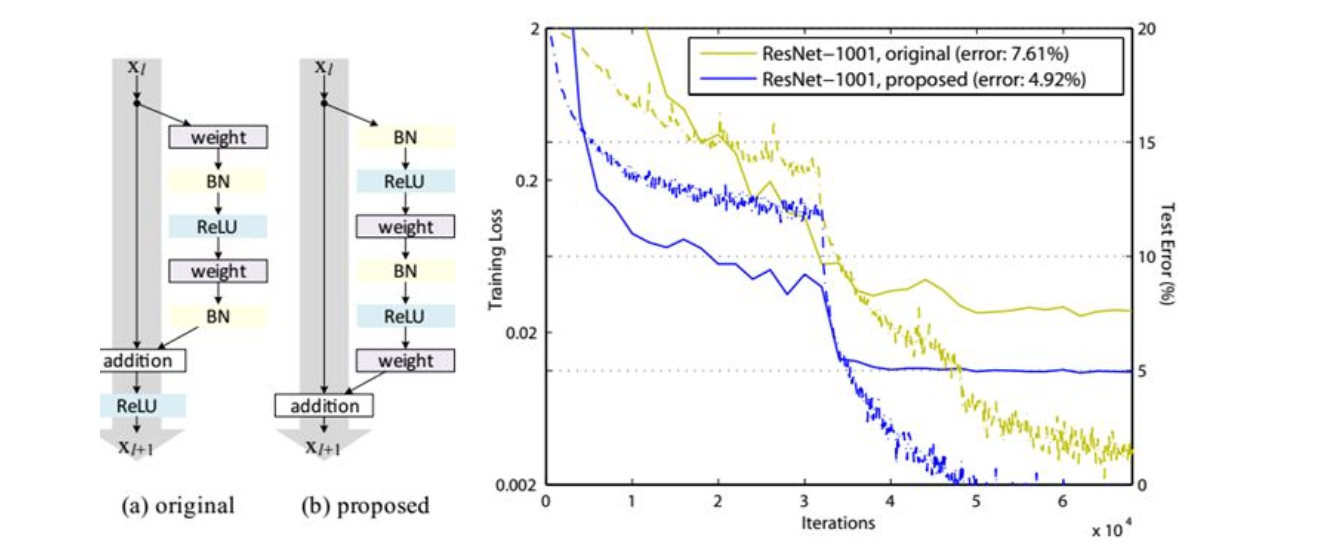
残差网络解决了什么,为什么有效?
- NN好用的原因:一是表达能力特别强大,能拟合任意函数;二是免去了繁重的特征工程,特别适合于非结构化数据。
- 但NN总是有一些问题,除了过拟合之外,还有特别常见的梯度消失/爆炸,和网络退化的问题。
- 网络退化的原因:虽然56层网络的解空间包含了20层网络的解空间,但是我们在训练网络用的是随机梯度下降策略,往往解到的不是全局最优解,而是局部的最优解,显而易见56层网络的解空间更加的复杂,所以导致使用随机梯度下降算法无法解到最优解。
- 残差网络解决了网络深度过大带来的网络退化问题。
残差网络为何有效的三种解释:
- 何恺明等人从前后向信息传播的角度给出了残差网络的一种解释。在反向传播过程中,由于模块学习的是F(x)+x,导数为F(x)的导数加1,因此后面的梯度能比较顺畅地传到前面,即抑制了梯度消失的现象;而在前向传播的过程中,由于普通网络中x在经过网络层时候总要乘以其中的权重矩阵,因此很难保持前后恒等,换句话说,当网络深度过大时候,超出的层因为没法保证这一模块的输入输出一致,导致模型退化,而残差模块F(x)+x因为加了一个恒等项,模块学习的就不再是恒等映射H(x)=x,而是H(x)=0,后者比前者更容易学习,因此在很大程度上解决了网络退化的问题。综上可以认为残差连接使得信息前后向传播更加顺畅。(当然也有人认为主要是解决的网络退化问题,因为梯度消失问题基本上已经通过relu、特殊的初始化、BN来解决了。残差模块虽然有助于减轻梯度消失,但主要还是解决了网络退化。)
- 集成学习的角度。16年一篇论文指出,残差网络展开后实际上相当于一系列浅层网络的集成,在训练中贡献了梯度的是那些相对较短的路径。
- 梯度破碎的角度。2018年的一篇论文指出了一个新的观点,尽管残差网络提出是为了解决梯度弥散和网络退化的问题,但它解决的实际上是梯度破碎问题。梯度破碎就是在标准前馈神经网络中,随着深度增加,梯度逐渐呈现为白噪声的现象,即神经元梯度的相关性(corelation)按指数级减少;同时,梯度的空间结构也随着深度增加被逐渐消除。因为现在基于梯度的许多优化方法假设梯度在相邻点上是相似的,所以破碎的梯度会使这些优化方法的效果大打折扣。而残差连接可以极大地保留梯度的空间结构,缓解了梯度破碎问题。2018年有一篇可视化的论文支持这一说法,作者比较了Res56网络带残差模块和不带残差模块的损失函数三维图,不带残差模块的损失函数表面是一片怪石嶙峋,而带残差模块的损失函数表面像一片平缓的山丘,更有利于优化。
2.7 ResNeXt

ResNet的另一改进。主要是采用了VGG堆叠思想和Inception的split-transform-merge思想,在不增加参数复杂度的前提下提高准确率。ResNeXt发现,增加分支数是比加深或加宽更有效地提升网络性能的方式。结构关键点是:
- 沿用ResNet的短路连接,并且重复堆叠相同的模块组合;
- 多分支分别处理;
- 使用1×1卷积降低计算量;
- 利用分组卷积进行实现(如图c),结构更简洁而且速度更快。
2.8 DenseNet

CVPR2017的oral。主要思想是将每一层都与后面的层连接起来,如果一个网络中有L层,那么会有L(L+1)/2个连接。通过这样的密集连接,每一层在正向时候都能直接接受原始输入信号,在反向时候也都能直接接受损失函数的梯度,即这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。
当然,如果全部采用这种密集连接的方式,特征图的厚度就会很大。于是采用两种方式降低参数量:一是将密集连接的层做成一个模块,整个网络采用模块堆叠的方式,而不是所有层全部密集连接;二是在dense block中引入bottleneck layer,即卷积3x3前增加1x1卷积,以此来减少feature map数量。
缺点是太吃显存。通常占用显存的主要是推断过程中产生的feature map和参数量。有些框架会有优化,自动把比较靠前的层的feature map释放掉,所以显存就会减少,或者inplace操作通过重新计算的方法减少一部分显存,但是densenet因为需要重复利用比较靠前的feature map,所以无法释放,导致显存占用过大。
2.9 SENet

2017年ILSVRC冠军网络。是一个模块,可以和其他的网络架构结合,比如GoogLeNet、ResNet等。
两大步骤:Squeeze和Excitation。相当于在通道上应用注意力机制,即学习各个通道的权重,根据重要程度增强有用的通道、抑制没有用的通道。
3 各种经典模型的比较
前面介绍的各种图像分类模型都比较经典,特别是VGG16、GoogLeNet和ResNet,现在仍然在广泛使用。截至2017年初,各种经典架构对比如下。

Reference