继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable接口为主的序列化模块,还有1个是解压缩模块,所以打算分成2个模块做分析,今天来说说序列化,反序列化的分析学习,当然不只是简单的wrtite,read等的简单调度。在分析之前,看下IO包的类包含图:

在Hadoop中,你可以用java自带的序列化方式的实现,但是不推荐,因为针对Hadoop系统的分布式环境的特点,最好还是调用Hadoop自身设计的一套新的序列化实现,在java中只要接上Serializable接口代表就可以被序列化了,而在HadoZ喎�"/kf/ware/vc/" target="_blank" class="keylink">vcNbQo6y1o8jO1eK49r3Hyau1xL7NysfPwsPm1eK49r3Tv9o6PC9wPgo8cD48cHJlIGNsYXNzPQ=="java;">public interface Writable { /** * Serialize the fields of this object to out. * * @param out DataOuput to serialize this object into. * @throws IOException */ void write(DataOutput out) throws IOException; /** * Deserialize the fields of this object from in. * *
For efficiency, implementations should attempt to re-use storage in the * existing object where possible.
* * @param in DataInput to deseriablize this object from. * @throws IOException */ void readFields(DataInput in) throws IOException; } 里面定义了很简单的2个方法。基本的一些数据类型都继承了这个接口,比如下面的这些:

上面的子类型只是列举出了一部分,基本上每种基本类型都有对应的Writable形式。在默认的上述子类型中都已经实现了接口的方法,所以用户在使用时可以忽略里面的细节。在上述序列化框架中还有一个特殊的设计就是WritableFactories工厂的设计。
/** Factories for non-public writables. Defining a factory permits {@link * ObjectWritable} to be able to construct instances of non-public classes. */ public class WritableFactories { /** * Writable工厂模式的变量保存 */ private static final HashMap<class, writablefactory=""> CLASS_TO_FACTORY = new HashMap<class, writablefactory="">(); private WritableFactories() {} // singleton </class,></class,>
在这里维护了1个map容器。那么WritableFactory是什么呢:
/** A factory for a class of Writable. * @see WritableFactories */ public interface WritableFactory { /** Return a new instance. */ Writable newInstance(); }
其实也就是一个接口,不过,通过这个factory你可以返回你想要的Writable对象,这个工厂产生的Writable对象可能会用于某些ObjectWritable的readFileds()等等方法中。当然,Hadoop还能接入其他比较优秀的序列化框架,比如Hadoop Avro,Apache Thrift或者Google Protocol Buffer。
上面说的都是Hadoop中的各种序列化机制,那为什么Hadoop就不能采用java自带的Serialization的序列化机制呢,这个问题还得归咎于Hadoop系统的本身,Hadoop作为一种分布式平台,数据的传输都是通过RPC的形式,与网络的环境,带宽等都非常有影响。所以这时候,就要求传递的数据最好短小,精炼,序列化,反序列应该是越快速越好了哦。但是这些要求在java自带的机制中就有些不符合了。下面来看个java自带程序的序列化例子:
声明了一个类A,一个类B:
public class A implements Serializable{ protected int age; }
public class B extends A{ /** * */ private static final long serialVersionUID = -5079514899384299792L; private float height; private ContainClass contain = new ContainClass(); public void setHeight(float height){ this.height = height; } }
还有1个contain内部类:
public class ContainClass implements Serializable{ private int value = 11; }
然后再场景类中调用,将Object B的信息序列化到文件中:
/** * 序列化测试类 * @author lyq * */ public class Client { public static void main(String[] args){ B b = new B(); b.age = 22; b.setHeight(170); String filePath = "D:test.txt"; serialization(filePath, b); } /** * serialize to file * * @param filePath * @param obj * @return * @throws RuntimeException * if an error occurs */ public static void serialization(String filePath, Object obj) { ObjectOutputStream out = null; try { out = new ObjectOutputStream(new FileOutputStream(filePath)); out.writeObject(obj); out.close(); } catch (FileNotFoundException e) { throw new RuntimeException("FileNotFoundException occurred. ", e); } catch (IOException e) { throw new RuntimeException("IOException occurred. ", e); } finally { if (out != null) { try { out.close(); } catch (IOException e) { throw new RuntimeException("IOException occurred. ", e); } } } } }
最后就序列化到我的D盘的目录下了,这时如果你直接用txt打开估计是看不出什么东西的,建议,用一个代码编辑器以16进制的形式打开,就会看到下面的样子:
AC ED 00 05 73 72 00 0F 53 65 72 69 61 6C 69 7A 65 54 65 73 74 2E 42 B9 81 F0 1C 86 E5 0E F0 02 00 02 46 00 06 68 65 69 67 68 74 4C 00 07 63 6F 6E 74 61 69 6E 74 00 1C 4C 53 65 72 69 61 6C 69 7A 65 54 65 73 74 2F 43 6F 6E 74 61 69 6E 43 6C 61 73 73 3B 78 72 00 0F 53 65 72 69 61 6C 69 7A 65 54 65 73 74 2E 41 D7 91 1A 56 65 43 36 5D 02 00 01 49 00 03 61 67 65 78 70 00 00 00 16 43 2A 00 00 73 72 00 1A 53 65 72 69 61 6C 69 7A 65 54 65 73 74 2E 43 6F 6E 74 61 69 6E 43 6C 61 73 73 72 41 F3 7A E0 C6 43 DF 02 00 01 49 00 05 76 61 6C 75 65 78 70 00 00 00 0B
关看上面的字节码也许你会头大,下面看一下对应的字符表
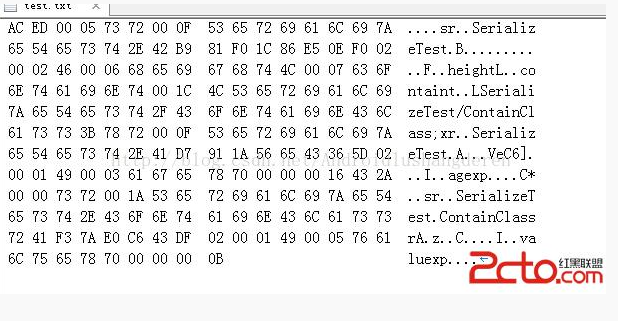
我们可以清晰的看到里面不关关保留了类B的本身类名信息,还有他的父类A的信息,还有A中的变量域等等,可以说还是非常庞杂的信息,设想一下,我这才是非常简单的定义了2个类,变量都只是1,2个int整形值,就已经如此庞大了,如果遇上复杂的类需要序列化,序列化后的文件大小一定不小。所以这也正是Hadoop不采用java自带的序列化机制的原因。但是既然,我们已经分析到这里了,就彻底的了解一下java的序列化机制的原理,也许很多人经常用过序列化,但还不知道序列化后的东西到底是什么吧,还是继续上年这个例子,我们通过上面的字节码去一一解读。在解读之前,有必要知道java的序列化一个简单对象的过程:
1.将对象实例相关的类元数据输出
2.递归地往上输出类的父类描述直到没有父类
3.类元数据输出完毕后,接着反着从最顶上的父类开始输出对象实例的数据值
4.再从上到下递归的输出实例的所有的值
对照上面的算法,我们试试分析一下,首先输出刚刚序列化后的字节码:
AC ED 00 05 73 72 00 0F 53 65 72 69 61 6C 69 7A
65 54 65 73 74 2E 42 B9 81 F0 1C 86 E5 0E F0 02
00 02 46 00 06 68 65 69 67 68 74 4C 00 07 63 6F
6E 74 61 69 6E 74 00 1C 4C 53 65 72 69 61 6C 69
7A 65 54 65 73 74 2F 43 6F 6E 74 61 69 6E 43 6C
61 73 73 3B 78 72 00 0F 53 65 72 69 61 6C 69 7A
65 54 65 73 74 2E 41 D7 91 1A 56 65 43 36 5D 02
00 01 49 00 03 61 67 65 78 70 00 00 00 16 43 2A
00 00 73 72 00 1A 53 65 72 69 61 6C 69 7A 65 54
65 73 74 2E 43 6F 6E 74 61 69 6E 43 6C 61 73 73
72 41 F3 7A E0 C6 43 DF 02 00 01 49 00 05 76 61
6C 75 65 78 70 00 00 00 0B
字母和大小有点不一致导致对不齐了,不过可以将就着看:
首先是AC ED:魔数,代表使用了序列化协议
00 05 :代表序列化协议版本
0x73:声明了这是一个新的对象
首先刚刚算法的第一步,输出对象类的类元数据:
首先A----->B
0x72:代表一个新的类的开始标记
00 0F:表示新的Class的名字长度,这里的值为15,因为名字为SerializeTest.B,总共15个字符
53 65 72 69 61 6C 69 7A
65 54 65 73 74 2E 42:表示类名,值为SerializeTest.B,通过字符的Ascall码制做映射,比如A的码制为65,a为65+32=97
B9 81 F0 1C 86 E5 0E F0:类的序列化ID,如果用户没有设定则会由算法随机生成一个8字节的ID,因为我为了区分A,B,把B设成了有序列化ID
|
1
2
3
4
5
|
public class B extends A{ /** * */ private static final long serialVersionUID = -5079514899384299792L; |
0x02:标记号,该值表明改对象支持序列化
下面是输出里面的元数据的个数了:
00 02:代表的是所包含的变量的个数,这里是2个,B中的域1个为height,1个为contain类
接下来输出变量的信息了:
0x46:代表的是float类型,int类型为49
00 06:域名字的长度,这里为6,就是height
68 65 69 67 68 74:域名的描述,为字符height
然后是输出另一个域变量了就是内部类contain:
0x4c:域的类型,代表一个引用
00 07:域名字长度7,就是contain
63 6F 6E 74 61 69 6E:类名字描述,contain
0x74:代表用一个string来引用对象
00 1C:该string的长度为28
4C 53 65 72 69 61 6C 69
7A 65 54 65 73 74 2F 43 6F 6E 74 61 69 6E 43 6C
61 73 73 3B:JVM字节码标准的签名描述符,LSerializeTest/ContainClass;
0x78:contain数据类结束标记
下面开始输出父类的信息了
0x72:代表了一个新类
00 0F:名字长度15
53 65 72 69 61 6C 69 7A
65 54 65 73 74 2E 41:描述符为SerializeTest.A
D7 91 1A 56 65 43 36 5D:又代表了1个8字节的序列化ID,这个是系统自动生成的
0x02:标记号,该值表明改对象支持序列化
00 01:代表的是所包含的变量的个数,这里是1个,1个为age
0x49:代表的是int类型
00 03:域名字的长度,这里为3,就是age
61 67 65:域名的描述,为字符age
0x78:A类的数据类结束标记,
0x70:说明A没有父类
到了这里已经把所有的类元数据输出,接着就是自顶向下输出数据的值了:
00 00 00 16:值为16*1+6=22,刚刚好是我设置的age的值。
43 2A 00 00:float类型height的值170的表现形式,不知道二者是怎么对应上的跟整形的不太一样....
下面就是输出contain域的值了,但是contain类还没有输出元数据,所以得执行类似上面的A,B操作;
0x73:声明了这是一个新的对象
0x72:代表一个新的类的开始标记
00 1A:长度域为26
53 65 72 69 61 6C 69 7A 65 54
65 73 74 2E 43 6F 6E 74 61 69 6E 43 6C 61 73 73 :域的描述长度26个字节,为SerializeTest.ContainClass
72 41 F3 7A E0 C6 43 DF:8个字节的序列化ID
0x02:标记号,该值表明改对象支持序列化
00 01:代表域的个数为1个就是里面的int vaule
0x49:类型为int整形 00 05长度为5,
76 61 6C 75 65:描述符为value
0x78:contain类的数据类结束标记,
0x70:说明contain没有父类
描述完整个内部类的元数据后,回到刚刚那个话题,就是输出值了,就剩下最后的contain.value:
00 00 00 0B :就是十进制的11
好了我们大致理一下序列化的过程
输出B的变量信息----->输出父类A的变量信息------>输出A的变量的值------》输出B的变量的值------》输出contain类的变量值时发现没有输出内部类contain的变量信息-----》再次输出contain的变量信息------》最后输出contain类的变量值
总的来说,还是比较复杂的吧,跟jvm的程序的字节码的生成比较类似。