1. 什么是分库分表
- 分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
- 分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
2. 为什么要分库分表?
数据库出现性能瓶颈。用大白话来说就是数据库快扛不住了。
数据库出现性能瓶颈,对外表现有几个方面:
-
大量请求阻塞
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。 -
SQL 操作变慢
如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。 -
存储出现问题
业务量剧增,单库数据量越来越大,给存储造成巨大压力。
从机器的角度看,性能瓶颈无非就是CPU、内存、磁盘、网络这些。
要解决性能瓶颈最简单粗暴的办法就是提升机器性能,但是通过这种方法成本和收益投入比往往又太高了,不划算,所以重点还是要从软件角度入手。
3. 数据库相关优化方案
硬件层面:增加机器性能。比如:将机械硬盘换成固态硬盘。
软件层面:SQL 调优、表结构优化、读写分离、数据库集群、分库分表等。
4. 表结构优化
以一个场景举例说明:
“user”表中有 user_id、nickname 等字段,“order”表中有order_id、user_id等字段,如果想拿到用户昵称怎么办?一般情况是通过 join 关联表操作,在查询订单表时关联查询用户表,从而获取导用户昵称。
但是随着业务量增加,订单表和用户表肯定也是暴增,这时候通过两个表关联数据就比较费力了,为了取一个昵称字段而不得不关联查询几十上百万的用户表,其速度可想而知。
这个时候可以尝试将 nickname 这个字段加到 order 表中(order_id、user_id、nickname),这种做法通常叫做数据库表冗余字段。这样做的好处展示订单列表时不需要再关联查询用户表了。
PS:冗余字段的做法也有一个弊端,如果这个字段更新会同时涉及到多个表的更新,因此在选择冗余字段时要尽量选择不经常更新的字段。
5. 架构优化(读写分离、数据库集群、缓存)
当单台数据库实例扛不住,我们可以增加实例组成 集群 对外服务。
当发现读请求明显多于写请求时,我们可以让主实例负责写,从实例对外提供读的能力【读写分离】。
如果读实例压力依然很大,可以在数据库前面加入缓存如 redis,让请求优先从缓存取数据减少数据库访问【缓存】。
6. 分库分表
6.1 先说说分库分表的缺点
1. 跨库关联查询
在单库未拆分表之前,我们可以很方便使用 join 操作关联多张表查询数据,但是经过分库分表后两张表可能都不在一个数据库中,如何使用 join 呢?
有几种方案可以解决:
-
字段冗余:把需要关联的字段放入主表中,避免 join 操作;
-
数据抽象:通过ETL等将数据汇合聚集,生成新的表;
-
全局表:比如一些基础表可以在每个数据库中都放一份;
-
应用层组装:将基础数据查出来,通过应用程序计算组装;
2. 分布式事物
单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。
3. 分布式ID
如果使用 Mysql 数据库在单库单表可以使用 id 自增作为主键,分库分表了之后就不行了,会出现 id 重复。
常用的分布式 ID 解决方案有:
- UUID
- 基于数据库自增单独维护一张 ID表
- 号段模式
- Redis 缓存
- 雪花算法(Snowflake)
- 百度uid-generator
- 美团Leaf
- 滴滴Tinyid
3. 多数据源
分库分表之后可能会面临从多个数据库或多个子表中获取数据。
一般的解决思路有:客户端适配和代理层适配。
业界常用的中间件有:
- shardingsphere(前身 sharding-jdbc)
- Mycat
如果出现数据库问题不要着急分库分表,先看一下使用常规手段【SQL调优、表结构优化、集群、缓存】是否能够解决。
6.2 分库分表入门简介
不分库
在早期阶段想做一个商城系统,基本就是一个系统包含多个基础功能模块,最后打包成一个 war 包部署,这就是典型的单体架构应用。

分库
该商城系统在前期为了抢占市场,在部分库这一套系统下不停地迭代更新,代码量越来越大,架构也变得越来越臃肿,现在随着系统访问压力逐渐增加,系统拆分就势在必行了。
为了保证业务平滑,系统架构重构也是分了几个阶段进行。
-
阶段一: 将商城系统单体架构按照功能模块拆分为子服务。比如:Portal 服务、用户服务、订单服务、库存服务等。
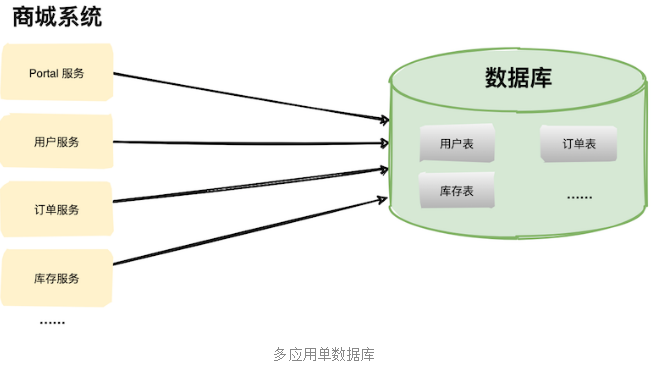
-
阶段二: 多服务多数据库。随着业务推广力度加大,数据库终于成为了瓶颈,这个时候多个服务共享一个数据库基本不可行了。我们需要将每个服务相关的表拆出来单独建立一个数据库

现在非常火的微服务架构也是一样的,如果只拆分应用不拆分数据库,不能解决根本问题,整个系统也很容易达到瓶颈。
不分表
如果系统处于高速发展阶段,拿商城系统来说,一天下单量可能几十万,那数据库中的订单表增长就特别快,增长到一定阶段数据库查询效率就会出现明显下降。
一般来说:单表超过500万的数据量就要考虑分表了。当然500万只是一个经验值,大家可以根据实际情况做出决策。
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。
商品列表中商品名称、商品图片、商品价格等其他字段数据访问频次较高。
商品列表中商品描述字段往往访问频次较低,且该字段存储占用空间较大,访问时间也较长。
分表
分表可划分为:水平切分和垂直切分
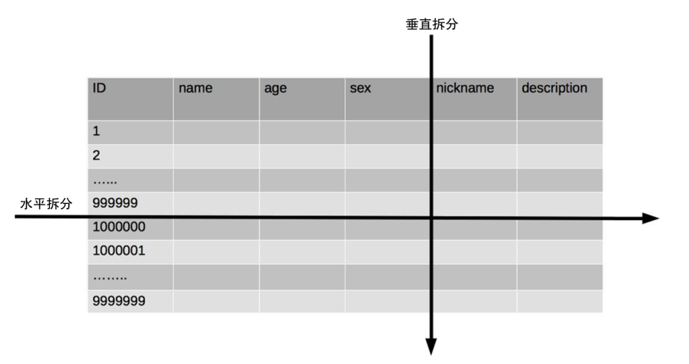
垂直切分:
就拿商品表来说,表中有7个字段:id,name,url,money,address,phone,describe,size。如果 address,phone,describe,size 不常用,我们可以将其拆分为另外一张表:商品详情表,这样就由一张商品表拆分为了商品基本信息表+商品详情表,两张表结构不一样相互独立。
好处:
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
水平切分:
从垂直拆分的角度来,其没有从根本上解决单表数据量过大的问题。因此我们可以做水平拆分。
比如:表中有一万条数据,我们拆分为两张表,id 为奇数的:1,3,5,7……放在 user1, id 为偶数的:2,4,6,8……放在 user2中,这样的拆分办法就是水平拆分了。
比如:按照时间维度取拆分,比如订单表,可以按每日、每月等进行拆分。每日表:只存储当天的数据。每月表:可以起一个定时任务将前一天的数据全部迁移到当月表。
好处:
- 水平切分主要是为了减少单张表的大小,解决单表数据量带来的性能问题。
6.3 分库分表详解实战
参考:
https://blog.csdn.net/weixin_44062339/article/details/100491744
https://zhuanlan.zhihu.com/p/137368446
https://mp.weixin.qq.com/s/zVRm6HaszocZfVE4NbjSiQ
https://www.cnblogs.com/butterfly100/p/9034281.html
http://blog.itpub.net/29254281/viewspace-1819422/
https://www.infoq.cn/article/key-steps-and-likely-problems-of-split-table
待定