一、多进程和多线程

共同点:
让多个CPU同时处理请求
区别:
1.多线程中的线程在内存空间这一点上是共享的,进程与进程使用的是不同的内存空间。即创建线程不需要开辟内存空间,而创建新的进程需要为其分配新的内存空间
全局解释器锁(GIL)
在每一个进程的“出口”,是python特有的。它的作用是:做到了1个限制,什么限制呢,如果有2个线程同时被调度了,此时全局解释器锁就限制同时只能有1个穿过全局解释器锁,才能被CPU调度
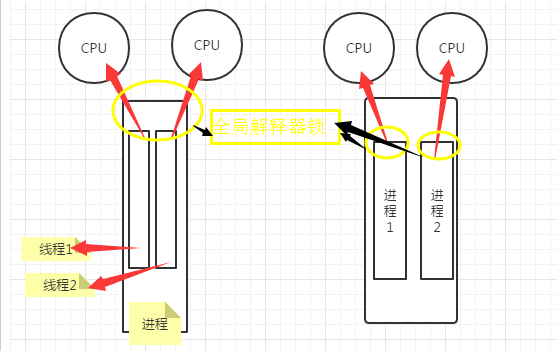
那什么时候该使用多进程,什么时候该使用多线程呢?
- I/O密集型用多线程
- 计算密集型用多进程
线程对象的其它方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon(True/False) True是设置为后台线程(默认是设置的False,即不写是设置的前台线程)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止 - join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后执行Thread类对象的run方法
一、多线程示例1
thread1.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
def show(arg):
time.sleep(1)
print 'thread'+str(arg)
for i in range(10):
#创建1个线程,执行show方法,接收1个参数
t = threading.Thread(target=show,args=(i,))
#t.setDaemon(True)#主线程执行完成之后,就关闭
#设置为前台线程,所有的线程执行完成后才关闭
t.setDaemon(False)
t.start()
print 'main thread stop'
thread2.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
def show(arg):
time.sleep(1)
print 'thread'+str(arg)
for i in range(10):
#创建1个线程,执行show方法,接收1个参数
t = threading.Thread(target=show,args=(i,))
#设置为后台线程,主线程执行完后就直接关闭
t.setDaemon(True)
t.start()
print 'main thread stop'
执行thread1.py,产生如下结果:

执行thread2.py,产生如下结果:

二、线程锁
1.为什么要使用线程锁?
python2.7默认每1个线程执行100条cpu指令。当执行多线程的时候关系到调用全局变量的时候,这时候就会因为多线程导致产生”脏数据“。那么,这时候我们就需要定义"线程锁"来避免产生脏数据,让一个线程执行完成之后,另外1个线程才能执行。即让多个线程按规则有序的执行,而不至于相互抢占着执行。下面是用和没用锁的2个例子:
no_havelock.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
gl_num = 0
def show(arg):
global gl_num
time.sleep(1)
gl_num+=1
print gl_num
for i in range(10):
t = threading.Thread(target=show,args=[i,])
t.start()
print 'main thread stop'
have_lock.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
import time
gl_num = 0
#定义全局解释器锁
lock = threading.RLock()
def show(arg):
#从这里开始锁住
lock.acquire()
global gl_num
time.sleep(1)
gl_num+=1
print gl_num
#从这里开始释放锁
lock.release()
for i in range(10):
t = threading.Thread(target=show,args=[i,])
t.start()
print 'main thread stop'
结果:
先执行 no_havelock.py,产生如下图示结果

再执行 have_lock.py,产生如下图示结果

三、事件event
python线程中的事件,主要用于主线程控制其它线程的执行,即主线程能让子线程停下来,也能让子线程继续执行。event主要提供了3个方法,分别是:set(),wait(),clear().
event实现的处理机制:
1.全局定义了一个flag,
2.如果flag = True,就让他继续执行。
3.如果flag = False,就让它停止,等待着,直到flag = True,才继续往下执行。
example.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import threading
def do(event):
print 'start'
event.wait() #判断flag,从而决定是继续执行还是挺住等待执行
print 'execute'
#定义1个事件
event_obj = threading.Event()
for i in range(10):
t = threading.Thread(target=do,args=(event_obj,))
t.start()
#即将flag设置为False,即“红灯停”
event_obj.clear()
inp = raw_input("input:")
if inp == 'true':
#将flag设置为True,即“绿灯行”
event_obj.set()

然后执行example.py,执行结果如下:

四、python的进程。创建多个进程,就可以同时利用多个CPU,创建进程的数量最好跟CPU数量相等。
1.进程简单示例
example.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from multiprocessing import Process
#import threading
import time
def foo(i):
print 'sys hello',i
for i in range(3):
p = Process(target=foo,args=(i,))
p.start()
这个实例必须在linux环境下,执行才能成功。
2.如何实现进程数据共享?
我们都知道,每个进程的内存空间资源是独立的,他默认是无法实现数据共享的,如果想要多个进程之间共享资源数据,那么该怎么处理呢?
这时候就需要一个特殊的数据结构可以实现数据共享,使用Array定义特殊的数据结构:Array('i', [11,22,33,44])
进程间数据共享定义方法1:

可以把i替换成其它的如:
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
进程间数据共享定义方法2:
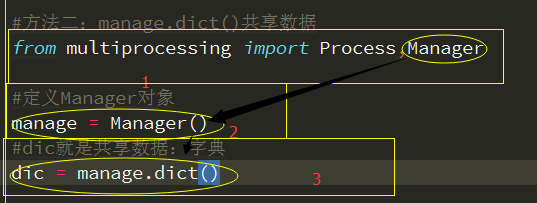
共享数据示例2:
#方法二:manage.dict()共享数据
from multiprocessing import Process,Manager
#定义Manager对象
manage = Manager()
#dic就是共享数据:字典
dic = manage.dict()
def Foo(i):
dic[i] = 100+i
print dic.values()
for i in range(2):
p = Process(target=Foo,args=(i,))
p.start()
p.join()
执行流程:

五、python中的协程
使用协程的目的:
可以理解将线程“分片”,因为线程切换比较耗时。I/O操作比较多的话,最好采用协程比较合适。可以发多个I/O请求。
简单示例1:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from greenlet import greenlet
def test1():
print 12
gr2.switch() #切换到协程2
print 34
gr2.switch() #切换到协程2
def test2():
print 56
gr1.switch() #切换到协程1
print 78
gr1 = greenlet(test1) #定义协程gr1
gr2 = greenlet(test2) #定义协程gr2
gr1.switch() #主动执行协程1
整个示例的执行流程如下:

简单示例2:
from gevent import monkey; monkey.patch_all()
import gevent
import urllib2
def f(url):
print('GET: %s' % url)
resp = urllib2.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(f, 'https://www.python.org/'),
gevent.spawn(f, 'https://www.yahoo.com/'),
gevent.spawn(f, 'https://github.com/'),
])
执行顺序图如下:
