前言
布隆过滤器的作用是判断一个元素是否存在于一个集合中。
比如有一个集合存储了全国所有人的身份证号码,那么该集合大小有十几亿的大小,此时如果判断一个身份证是否存在于该集合中,最简单也是最笨的办法就是遍历集合,挨个判断是否和校验的身份证号码相同来判断。而布隆过滤器就是通过一个提高空间和时间效率的一种算法,来快速判断一个元素是否存在于集合中。
另外还有一个问题,如果采用遍历的方式,还有一个比较大的问题就是内存的问题,假设现有一个场景,有10亿个整数,需要判断一个整数是否存在于这个整数集合中。那么首先需要创建一个int类型的数组,int类型占用4个字节也就是32位,10亿个int类型占用的空间大小就是 4*1000000000/1024/1024/1024 = 3.72G,可以算出10亿个整数存在内存中至少就需要占用3.72个G的内存,如果是20亿,就是7个G的内存,很容易就会造成内存溢出了,所以大数据的情况下,通过遍历的方式显然是不行的。此时就可以通过bitmap来实现。
一、bitmap
bitmap也叫做位图,是一种数据结构。可以理解为是一个很长的数组,每一个数组元素是一个二进制值,非0即1,也就是说bitmap本质上是一个数组,每个数组元素是一个位的值。
如果通过bitmap来存在10亿个int类型,bitmap的大小为1000000000位/8/1024/1024 = 0.12G,可以发现通过为位图来表示10亿个整数值仅仅只需要120M大小的空间就可以表示,占用的内存大小大大减少。那么接下来就了解下bitmap的结构
1.1、bitmap的结构
int类型占用4个字节,1个字节占8位,也就是一个int类型占用32位,而bitmap是一位表示一个数字,所以可以容纳的数据是int类型的32倍。因为判断是否存在于一个集合中,只需要得到一个结果:在还是不在,那么就可以通过0和1来表示在还是不在。
如下图:

上图中是一个int类型值在内存中的存储结构,一共占用了32位,每一位都对应了一个数字,对应的位置如果值为1,那么表示对应位置的值是存在的。如上图中可以分表表示 2、9、12、27、31的值是存在的,而这整个32位对应一个int类型的数字。相当于一个int类型的值可以表示32个数字是否存在。
所以可以用一个int类型的数组来表示一个bitmap,每个int值可以代表32个bit值。
1.2、bitmap保存数据
将数字100保存到bitmap中,那么首先需要知道100需要存在int数组的那个位置,通过将 100/32=3可得到结果,则100位于int数字的第3个int值上
知道了数组的那一位之后,接下来就需要设置当前数组位置上对应位的值。通过100%32=4可知位于int值的第4位,那么此时可以通过或运算进行设置 将当前位置的int值和2的4次方的值进行或运算设置结果
伪代码如下:
1 /** int数组表示bitmap */ 2 static int[] bitmap = new int[]; 3 4 /** 5 * @param value:需要保存的值 6 * */ 7 public static void putValue(int value){ 8 /** 数组的每个int值可以保存32个数字, 通过除以32得到位于那个数组的位置 */ 9 int index = value/32; 10 /** 计算偏移位置,通过对32取余数得到位于int数字的具体位置 */ 11 int offset = value % 32; 12 /** 修改数组index位置的值,将当前的值和2的offset次方进行或运算*/ 13 bitmap[index] = bitmap[index] | (1<<offset); 14 }
主要分成三步,第一步是计算数组的下标值,第二步是计算数组对应位置数字的第几位表示当前值,第三步是通过或运算修改当前数组位置上的值
如现在需要判断10000个数字的bitmap,那么就需要创建10000/32长度的int数组。
第一次向bitmap中插入数字35,那么步骤如下:
1、计算index值,35/32=1;那么对应的数值为bitmap[1]的数值,此时bitmap[1] = 0
2、计算偏移量,35%32=3;那么表示需要在bitmap[1]的数值的第3位设置为1,此时通过将当前的值和2的3次方进行或运算,如下:
0000 0000 0000 0000 0000 0000 0000 0000 | 0000 0000 0000 0000 0000 0000 0000 1000 = 8
3、此时bitmap[1]的值为8
4、再次向bitmap中插入数组40,index值为 40/32 = 1;同样对应bitmap[1]的值,此时bitmap[1] = 8
5、计算偏移量,40%32=8;那么需要将当前bitmap[1]的值和2的8次方进行或运算,如下:
0000 0000 0000 0000 0000 0000 0000 1000 | 0000 0000 0000 0000 0000 0001 0000 0000 = 0000 0000 0000 0000 0000 0001 0000 1000 = 264
6、此时bitmap[1]的值为264
同样的插入其他值的过程如出一辙。而删除的逻辑基本一致,第一步和第二步一模一样,第三步的话是通过和对应值进行取反操作并和当前值进行与运算即可,如从bitmap中删除40,过程如下:
/** 2的8次方为256,对于256进行取反操作,再和当前值进行与运算 */ bitmap[i] = bitmap[1] & (~ 256);
1.3、bitmap判断数据是否存在
判断数据是否存在的方式和存储的逻辑类似,首先第一步和第二步都是先的计算数组的下标值index和对应的位数偏移量offset
然后需要判断bitmap[index]的值对应的offset位置是否值为1即可,判断过程是将2的offset次方的值和bitmap[index]的值进行与运算,然后判断结果是否大于0,如果大于0则表示对应位的值就是1,否则就不是
如对上面的例子进行判断,首先依次插入35和40之后,分表对35和36进行判断是否存在于bitmap中,过程分别如下:
1、计算35对应的index值为1,偏移量offset值为3,那么2的3次方值为8,二进制为0000 0000 0000 0000 0000 0000 0000 1000
2、将8和当前数组对应位置的值bitmap[1],也就是264,进行与运算,如下:
0000 0000 0000 0000 0000 0001 0000 1000 & 0000 0000 0000 0000 0000 0000 0000 1000 = 0000 0000 0000 0000 0000 0000 0000 1000 = 8
3、由于最后的结果8>0,所以得出结果为35存在于bitmap中
4、计算36对应的index值为1,偏移量offset值为4,那么2的4次方值为16,二进制为0000 0000 0000 0000 0000 0000 0001 0000
5、将16和当前数组对应位置的值bitmap[1],也就是264,进行与运算,如下:
0000 0000 0000 0000 0000 0001 0000 1000 & 0000 0000 0000 0000 0000 0000 0001 0000 = 0000 0000 0000 0000 0000 0000 0000 0000 = 0
6、由于最后的结果为0,所以得出结果为37不存在于bitmap中
总结:
1、bitmap通过每一位表示一个整数来判断一个整数是否存在,所以应用场景就可以保护所有判断整数是否存在的场景。
2、bitmap同样会存在数据稀疏的问题,比如如果需要存在两个特别大的值,如存100个大于2的30次方的值,那么就需要分配相当大的存储空间,就会造成内存空间的浪费。所以bitmap仅仅适合数据量较大的情况下使用,对于集合数据量小的场景不实用
3、bitmap仅仅只能用于整数的判断,无法判断字符串是否存在
二、布隆过滤器的实现
由上一节可知bitmap可以实现从一个比较大的整数集合中判断一个数字是否存在,但是实际场景中往往还会有其他的场景,比如从10亿个身份证判断某个身份证号码是否存在,很显然采用bitmap就无法实现了,因为bitmap只能判断整数是否存在。所以如果有一种方式能够将身份证号码的字符串转换成一个整数,那么就可以使用bitmap来实现判断字符串是否存在于一个集合中的需求了。而通过字符串转换成整数的方式也很普遍,那么就是采用hash函数通过计算字符串的hashCode来转换成整数。
而布隆过滤器实际就是一系列的hash函数+bitmap实现的。
1、字符串存入bitmap中
布隆过滤器是通过bitmap实现的,只不过在bitmap之上添加了多个hash函数来对传入的数据转换正常整数类型。如下图示
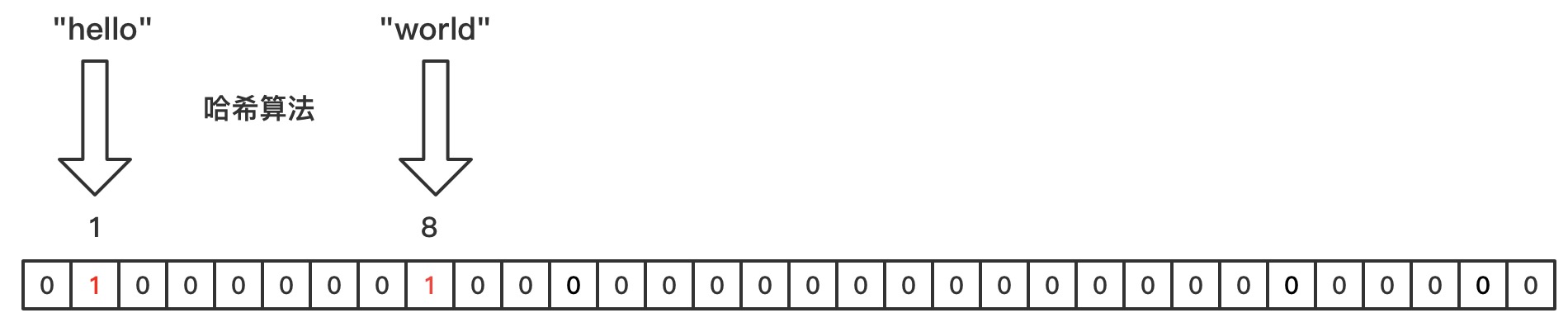
字符串hello和字符串world,通过hash计算之后分别hashCode值为1和8,那么就可以通过bitmap的功能将1和8分别存入bitmap中,就相当于hello和world两个字符串存入了bitmap中。判断字符串是否存在时就可以通过计算hashCode的方式,判断对应的hash值是否存在于bitmap中即可可以判断字符串是否存在于bitmap中了
2、hash碰撞问题
虽然通过字符串计算hash值存入bitmap中表面上没有什么问题,但是hash函数是存在一定的碰撞概率的,也就是多个字符串计算出来的hash值是一样的,此时就会出现误判的情况。
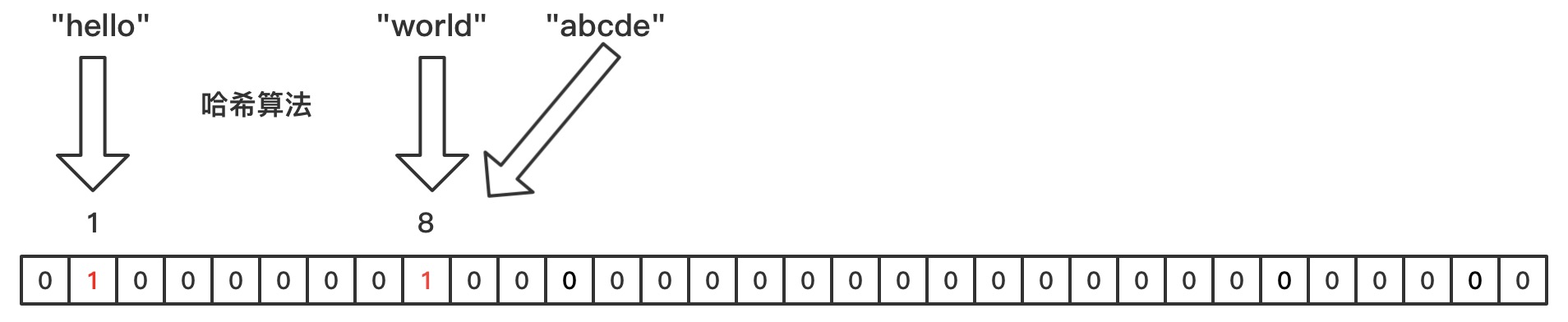
如上图,判断字符串abcde是否存在,就需要先计算hashCode值,结果为8,此时判断结果为hashCode为8已经存在于bitmap中的,此时就会得到错误的判断是字符串abcde已经存在了,但是实际是并不存在的,而是出现了hashCode碰撞的情况。但是如果对应的hashCode在bitmap中不存在,那么就可以确认当前字符串不存在。而hashCode存在的情况下,只能说明当前字符串是可能存在。
所以你通过布隆过滤器只能实现的功能为:能够确认一个字符串不存在于集合中,但是无法确认一个字符串存在于集合中。
3、hash碰撞问题的优化
由于hash函数会存在hash碰撞的情况,就导致布隆过滤器的功能会出现比较大的误差,那么既然一个hash函数存在hash碰撞,就可以采用多个hash函数来降低hash碰撞的概率。比较不同的字符串通过多个不同的hash函数还碰撞的概率会大大降低。如下图:
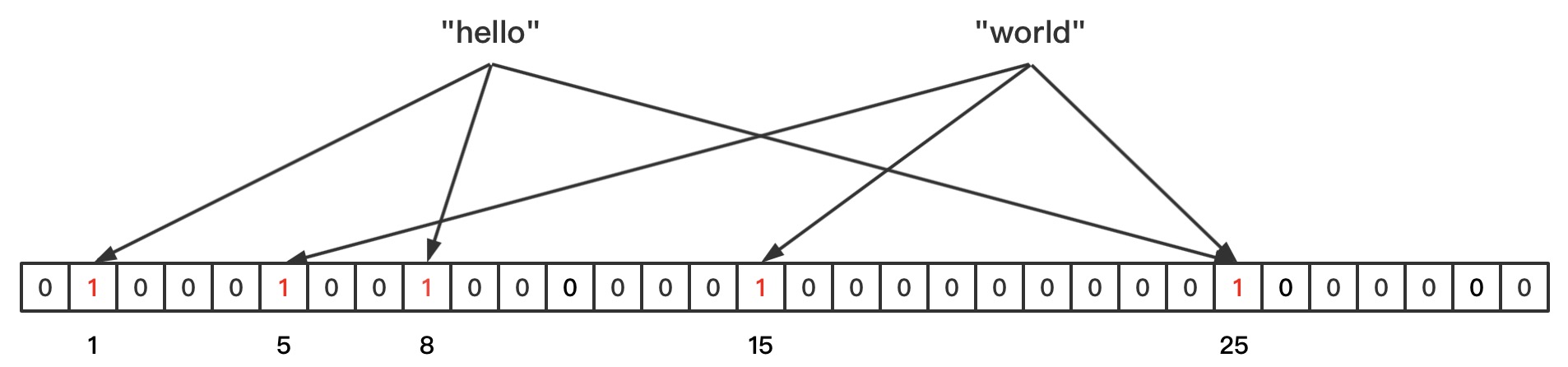
字符串hello通过三个hash函数分别计算出来的hash值为1、8、25;字符串world通过三个hash函数计算出来的hash值为5、15、25,虽然hash值为25发生了hash碰撞的情况,但是两位两个hash值均没有发生hash碰撞,只有当通过三个hash函数计算出来的hash值都存在时才能够判断一个字符串可能存在,如果某个字符串通过三个hash函数计算出来的hash值只有部分存在,那么就是存在hash碰撞,且给字符串肯定不存在。
虽然通过多个hash函数可以对于误判的情况进行优化,但是并没有本质上解决误判的情况,因为毕竟从理论上还是可能会存在多个hash值发生了hash碰撞的情况的。比如一个字符串通过三个hash函数计算的值分别为1、5、15,那么虽然和上面两个字符串都不是全部冲突了,但是1和hello发生了冲突,5和15和world发生了冲突,如果hello和world都存在,那么就会导致hash值为1、5、15的字符串产生误判的情况。
4、布隆过滤器删除元素
bitmap是支持删除元素的,因为bitmap不存在冲突的情况,每一个数字只会对应一个元素,而布隆过滤器的每一个元素都有可能会对应多个元素,所以不能通过删除的方式删除元素,因为这样可能会导致其他元素查询的结果不正确。
比如上图的例子,如果将world字符串删除,那么就需要将5、15、25三个位置的值置为0,此时再判断hello是否存在结果25的位置为0,那么就导致判断结果为hello字符串不存在了。
可以通过对每一位数字计算的方式判断每一位被hash冲突了多少次来实现删除元素的方式,但是每一位增加计算就会大大增加存储的空间。
总结:
布隆过滤器的本质是一个很长的位数组和一系列随机映射哈希函数
布隆过滤器判断存在的数据可能存在,布隆过滤器判断不存在的数据肯定不存在;
实际存在的数据布隆过滤器肯定判断存在,实际不存在的数据布隆过滤器可能会判断存在。
三、布隆过滤器的Java实现
google的guava包中提供了布隆过滤器的Java实现,对应的类为BloomFilter。使用案例如下:
1 public static void main(String[] args){ 2 int capacity = 100000; 3 /** 初始化容量为10万大小的字符串布隆过滤器,默认误差率为0.03 4 * 布隆过滤器容量为10万并非指bitmap的长度就是10万,因为需要考虑到存在hash冲突的情况,所以bitmap的实际长度要比10万要大很多 5 * bitmap长度比需要存在的数据量大小越大,误差率会越低 6 * */ 7 BloomFilter bloomFilter =BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), capacity); 8 9 Set<String> sets = new HashSet<>(); 10 List<String> lists = new ArrayList<>(); 11 12 for (int i =0;i< capacity; i++){ 13 String str = UUID.randomUUID().toString(); 14 bloomFilter.put(str); 15 sets.add(str); 16 lists.add(str); 17 } 18 19 int existsCount = 0; 20 int mightExistsCount = 0; 21 22 for(int i=0;i<10000;i++){ 23 //如果i为100倍数,取实际的值;否则就随机一个字符串 24 String data = i%100==0?lists.get(i/100):UUID.randomUUID().toString(); 25 /** 通过布隆过滤器判断字符串是否存在*/ 26 if(bloomFilter.mightContain(data)){ 27 /** 如果布隆过滤器认为存在,则表示可能存在的数量mightExistsCount自增1*/ 28 mightExistsCount++; 29 /** 如果set中存在则existsCount自增1*/ 30 if(sets.contains(data)){ 31 existsCount++; 32 } 33 } 34 } 35 36 //测试总次数 37 BigDecimal total = new BigDecimal(10000); 38 //错误总次数 39 BigDecimal error = new BigDecimal(mightExistsCount - existsCount); 40 //误差率 41 BigDecimal rate = error.divide(total, 2, BigDecimal.ROUND_HALF_UP); 42 43 System.out.println("初始化10万条数据,判断100个真实数据,9900个不存在数据"); 44 System.out.println("实际存在的字符串个数为:" + existsCount); 45 System.out.println("布隆过滤器认为存在的个数为:" + mightExistsCount); 46 System.out.println("误差率为:" + rate.doubleValue()); 47 }
测试两次结果分别如下:
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:441 4 误差率为:0.03
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:406 4 误差率为:0.03
在案例中通过BloomFilter类的静态方法create方法创建一个布隆过滤器,并初始化了需要存储数据的类型和数量,如案例中是存放String类型,并且容量为10万条数据。虽然容量是10万但是bitmap的实际长度远不止10万的长度,因为bitmap长度越大,hash碰撞导致的误差率就会越低。BloomFilter默认的误差率为0.03,也就是3%,可以通过初始化BloomFilter指定误差率。
案例中将10万条数据存入布隆过滤器,然后挑选100条真实存在的数据和9900条不存在的数据判断是否存在,结果显示为真实存在的100条,而布隆过滤器认为存在的数据条数为441条,也就是误差率为(441-100)/10000 = 0.03
同样误差率是可以调整的,但是不能调整为0,因为误差率为0从理论上是不可能的,只能通过扩大bitmap来尽量降低误差率。如上述案例设置误差率为0.01,那么初始化方法如下:
1 /** 指定误差率为0.01 */ 2 BloomFilter bloomFilter =BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), capacity, 0.01);
继续测试上述案例,测试两次结果如下:
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:186 4 误差率为:0.01
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:208 4 误差率为:0.01
可以看出虽然每次误差的数量不同,但是误差率都始终保持在了设定的范围之内。同样可以继续缩小误差率,比如将误差率分别设置为0.005和0.001,测试结果分别如下:
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:150 4 误差率为:0.005
1 初始化10万条数据,判断100个真实数据,9900个不存在数据 2 实际存在的字符串个数为:100 3 布隆过滤器认为存在的个数为:111 4 误差率为:0.001
所以可以看出布隆过滤器只能控制误差率,但是永远也做不到没有误差,只能通过设置误差率尽量降低误差,但是永远不能设置为0,如果初始化设置为0那么会直接抛异常。另外误差率必须是小于1的值
四、布隆过滤器的源码简析
1、首先需要初始化布隆过滤器,通过BloomFilter的静态方法create方法创建,源码如下:
1 /** 2 * @param funnel:存入元素的类型 3 * @param expectedInsertions:期望保存元素的个数 4 * */ 5 public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) { 6 //调用重载函数 7 return create(funnel, (long) expectedInsertions); 8 } 9 10 public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) { 11 /** 默认误差率为0.03 */ 12 return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions 13 } 14 15 /** 16 * @param fpp : 误差率 17 * */ 18 public static <T> BloomFilter<T> create( 19 Funnel<? super T> funnel, long expectedInsertions, double fpp) { 20 return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64); 21 } 22 23 /** 24 * @param strategy : 哈希函数的策略 25 * */ 26 static <T> BloomFilter<T> create( 27 Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) { 28 //参数校验,误差率必须为大于0且小于1 29 checkNotNull(funnel); 30 checkArgument( 31 expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions); 32 checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp); 33 checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp); 34 checkNotNull(strategy); 35 36 /** 期待容量不可为0*/ 37 if (expectedInsertions == 0) { 38 expectedInsertions = 1; 39 } 40 41 /** 根据期待容量和误差率,计算bitmap的位数 */ 42 long numBits = optimalNumOfBits(expectedInsertions, fpp); 43 /** 根据期待容量和bitmap的位数,计算需要的hash函数的数量 */ 44 int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits); 45 try { 46 /** 创建BloomFilter对象 */ 47 return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy); 48 } catch (IllegalArgumentException e) { 49 throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e); 50 } 51 }
create方法重载比较多,主要都是在初始化参数,核心参数为需要保存元素的个数、误差率。然后通过容量和误差率计算bitmap需要的位数,并且计算需要经历多少次hash函数。
2、向布隆过滤器中插入元素
BloomFilter插入元素调用了BloomFilter内部类Strategy的实现类的put方法,源码如下:
1 public <T> boolean put( 2 T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) { 3 /** bitmap长度 */ 4 long bitSize = bits.bitSize(); 5 long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong(); 6 int hash1 = (int) hash64; 7 int hash2 = (int) (hash64 >>> 32); 8 9 boolean bitsChanged = false; 10 /** 遍历每个哈希函数 */ 11 for (int i = 1; i <= numHashFunctions; i++) { 12 int combinedHash = hash1 + (i * hash2); 13 // Flip all the bits if it's negative (guaranteed positive number) 14 if (combinedHash < 0) { 15 combinedHash = ~combinedHash; 16 } 17 /** 修改对应hash值上面的值 */ 18 bitsChanged |= bits.set(combinedHash % bitSize); 19 } 20 return bitsChanged; 21 }
逻辑不复杂,就是通过计算出来的hash函数的个数,遍历执行多少次hash函数,修改bitmap上对应位置的值
3、查询布隆过滤器是否存在元素
1 /** 判断元素是否可能存在,false则肯定不存在,true则表示可能存在 */ 2 public boolean mightContain(T object) { 3 return strategy.mightContain(object, funnel, numHashFunctions, bits); 4 } 5 6 public <T> boolean mightContain(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.LockFreeBitArray bits) { 7 long bitSize = bits.bitSize(); 8 long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong(); 9 int hash1 = (int)hash64; 10 int hash2 = (int)(hash64 >>> 32); 11 /** 遍历执行多次hash函数 */ 12 for(int i = 1; i <= numHashFunctions; ++i) { 13 int combinedHash = hash1 + i * hash2; 14 if (combinedHash < 0) { 15 combinedHash = ~combinedHash; 16 } 17 /** 如果存在hash函数位不存在,直接返回false*/ 18 if (!bits.get((long)combinedHash % bitSize)) { 19 return false; 20 } 21 } 22 /** 如果所有hash函数都命中,则返回true*/ 23 return true; 24 }
五、布隆过滤器的应用
1、redis缓存穿透问题的解决,先将需要查询的数据存入布隆过滤器,如果布隆过滤器不存在则直接返回;如果布隆过滤器存在则再从redis查询(此时只会有少数误差数据);如果redis中还不存在则查询数据库(此时的访问很小了),并在查询数据库可以通过并发加锁处理,保证只有一个线程可以查询该数据并写入缓存,从而避免了缓存穿透的问题
2、爬给定网址的时候对已经爬取过的URL去重
3、邮箱的垃圾邮件过滤、黑名单等
4、经典面试题:一个10G大小的文件,存储内容为自然数,一行一个乱序排放,需要对其进行排序操作,但是机器的内存只有2G。
此时就可以通过布隆过滤器进行操作。首先将10G大小文件通过工具分隔成多个小文件,然后依次读取数据将数据存入bitmap中,10G的大小的自然数差不多可以存储27亿个左右的整数。
27亿个整数存入bitmap需要占用的空间为 2700000000/8/1024/1024 = 320M左右,所以内存是足够的。然后从1到最大值进行遍历判断是否存在于bitmap中从而达到排序的效果。