Elasticsearch 搜索引擎内置了很多种分词器,但是对中文分词不友好,所以我们需要借助第三方中文分词工具包。
悟空哥专门研究了下 ik 中文分词工具包该怎么玩,希望对大家有所帮助。
本文主要内容如下:

1 ES 中的分词的原理
1.1 ES 的分词器概念
ES 的一个分词器 ( tokenizer ) 接收一个字符流,将其分割为独立的词元 ( tokens ) ,然后输出词元流。
ES 提供了很多内置的分词器,可以用来构建自定义分词器 ( custom ananlyzers )
1.2 标准分词器原理
比如 stadard tokenizer 标准分词器,遇到空格进行分词。该分词器还负责记录各个词条 ( term ) 的顺序或 position 位置 ( 用于 phrase 短语和 word proximity 词近邻查询 ) 。每个单词的字符偏移量 ( 用于高亮显示搜索的内容 ) 。
1.3 英文和标点符号分词示例
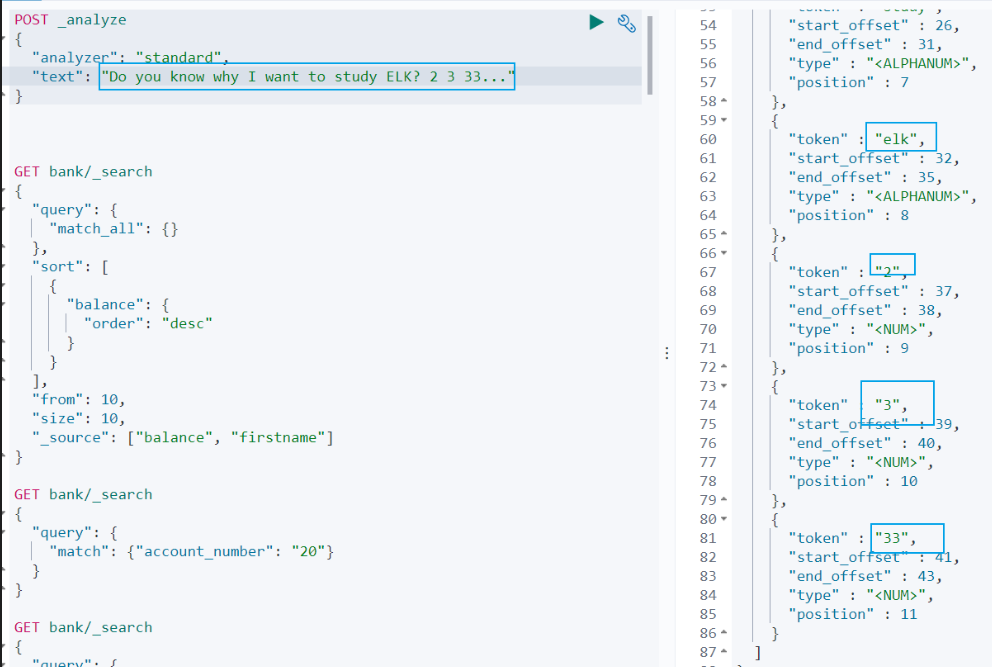
查询示例如下:
POST _analyze
{
"analyzer": "standard",
"text": "Do you know why I want to study ELK? 2 3 33..."
}
查询结果:
do, you, know, why, i, want, to, study, elk, 2,3,33
从查询结果可以看到:
(1)标点符号没有分词。
(2)数字会进行分词。
1.4 中文分词示例
但是这种分词器对中文的分词支持不友好,会将词语分词为单独的汉字。比如下面的示例会将 悟空聊架构 分词为 悟,空,聊,架,构,期望分词为 悟空,聊,架构。
POST _analyze
{
"analyzer": "standard",
"text": "悟空聊架构"
}
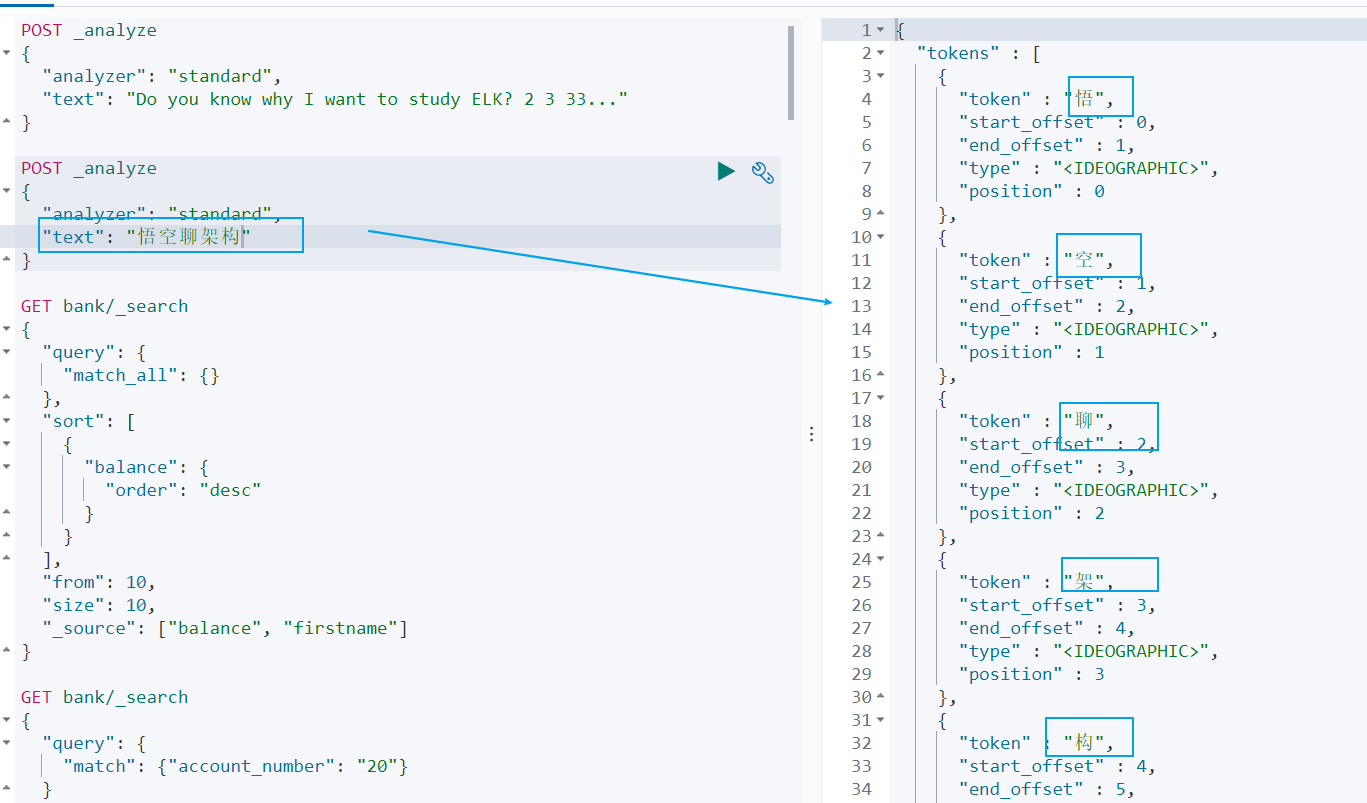
我们可以安装 ik 分词器来更加友好的支持中文分词。
2 安装 ik 分词器
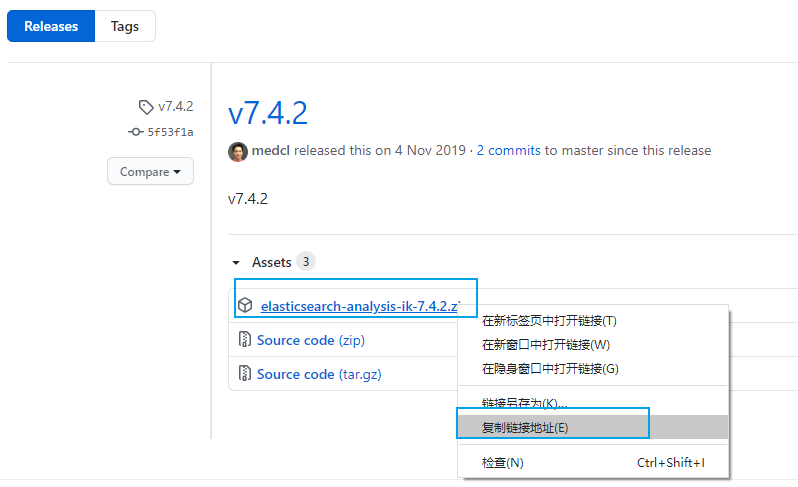
2.1 ik 分词器地址
ik 分词器地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
先检查 ES 版本,我安装的版本是 7.4.2,所以我们安装 ik 分词器的版本也选择 7.4.2
http://192.168.56.10:9200/
{
"name" : "8448ec5f3312",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "xC72O3nKSjWavYZ-EPt9Gw",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2.2 安装 ik 分词器的方式
2.2.1 方式一:容器内安装 ik 分词器
- 进入 es 容器内部 plugins 目录
docker exec -it <容器 id> /bin/bash
- 获取 ik 分词器压缩包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 解压缩 ik 压缩包
unzip 压缩包
- 删除下载的压缩包
rm -rf *.zip
2.2.2 方式二:映射文件安装 ik 分词器
进入到映射文件夹
cd /mydata/elasticsearch/plugins
下载安装包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 解压缩 ik 压缩包
unzip 压缩包
- 删除下载的压缩包
rm -rf *.zip
2.2.3 方式三:Xftp 上传压缩包到映射目录
先用 XShell 工具连接虚拟机 ( 操作步骤可以参考之前写的文章 02. 快速搭建 Linux 环境-运维必备) ,然后用 Xftp 将下载好的安装包复制到虚拟机。
3 解压 ik 分词器到容器中
- 如果没有安装 unzip 解压工具,则安装 unzip 解压工具。
apt install unzip
- 解压 ik 分词器到当前目录的 ik 文件夹下。
命令格式:unzip <ik 分词器压缩包>
实例:
unzip ELK-IKv7.4.2.zip -d ./ik

- 修改文件夹权限为可读可写。
chmod -R 777 ik/
- 删除 ik 分词器压缩包
rm ELK-IKv7.4.2.zip
4 检查 ik 分词器安装
- 进入到容器中
docker exec -it <容器 id> /bin/bash
- 查看 Elasticsearch 的插件
elasticsearch-plugin list
结果如下,说明 ik 分词器安装好了。是不是很简单。
ik

然后退出 Elasticsearch 容器,并重启 Elasticsearch 容器
exit
docker restart elasticsearch
5 使用 ik 中文分词器
ik 分词器有两种模式
-
智能分词模式 ( ik_smart )
-
最大组合分词模式 ( ik_max_word )
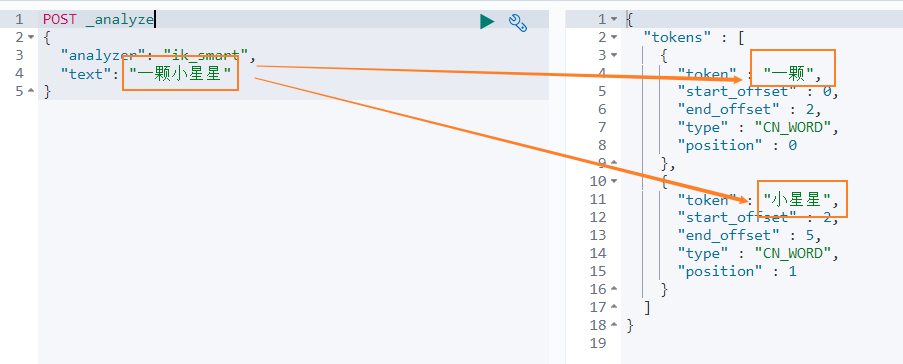
我们先看下 智能分词 模式的效果。比如对于 一颗小星星 进行中文分词,得到的两个词语:一颗、小星星
我们在 Dev Tools Console 输入如下查询
POST _analyze
{
"analyzer": "ik_smart",
"text": "一颗小星星"
}
得到如下结果,被分词为 一颗和小星星。
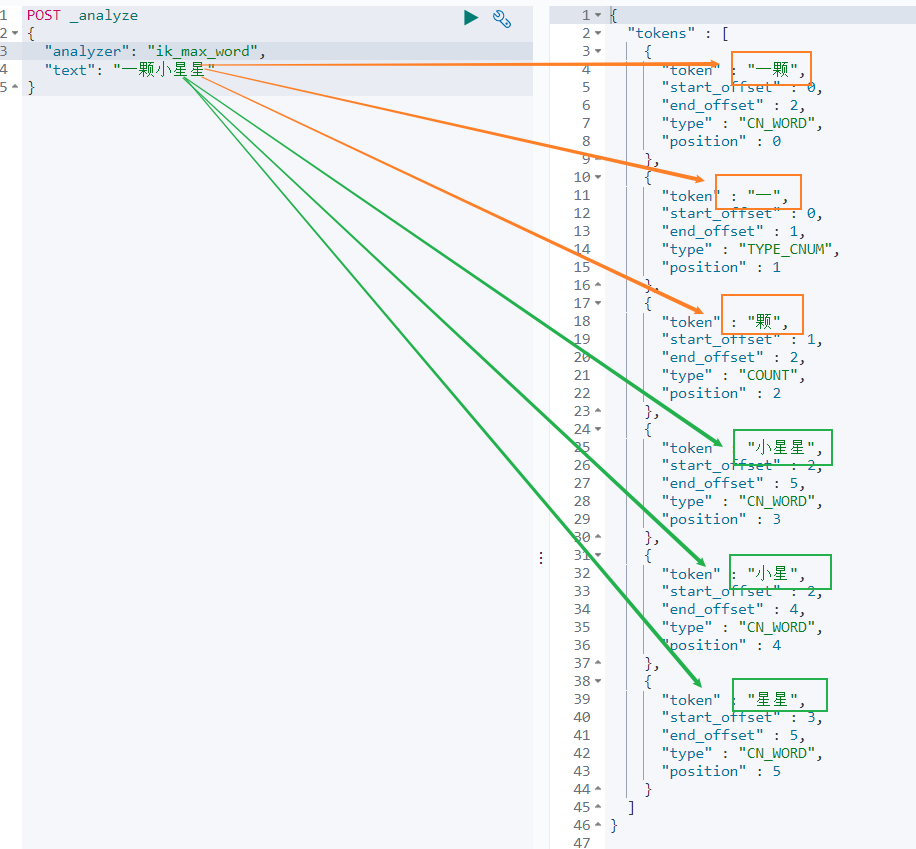
再来看下 最大组合分词模式。输入如下查询语句。
POST _analyze
{
"analyzer": "ik_max_word",
"text": "一颗小星星"
}
一颗小星星 被分成了 6 个词语:一颗、一、颗、小星星、小星、星星。
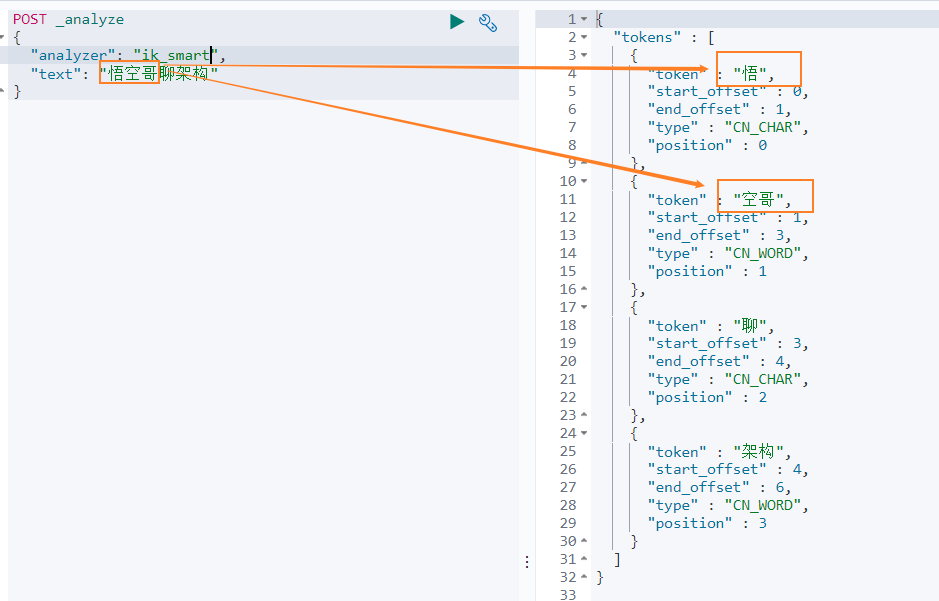
我们再来看下另外一个中文分词。比如搜索悟空哥聊架构,期望结果:悟空哥、聊、架构三个词语。
实际结果:悟、空哥、聊、架构四个词语。ik 分词器将悟空哥分词了,认为 空哥 是一个词语。所以需要让 ik 分词器知道 悟空哥 是一个词语,不需要拆分。那怎么办做呢?
6 自定义分词词库
6.1 自定义词库的方案
-
方案
新建一个词库文件,然后在 ik 分词器的配置文件中指定分词词库文件的路径。可以指定本地路径,也可以指定远程服务器文件路径。这里我们使用远程服务器文件的方案,因为这种方案可以支持热更新 ( 更新服务器文件,ik 分词词库也会重新加载 ) 。
-
修改配置文件
ik 分词器的配置文件在容器中的路径:
/usr/share/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml。
修改这个文件可以通过修改映射文件,文件路径:
/mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
编辑配置文件:
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
配置文件内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
修改配置 remote_ext_dict 的属性值,指定一个 远程网站文件的路径,比如 http://www.aaa.aaa/ikwords.text。
这里我们可以自己搭建一套 nginx 环境,然后把 ikwords.text 放到 nginx 根目录。
6.2 搭建 nginx 环境
方案:首先获取 nginx 镜像,然后启动一个 nginx 容器,然后将 nginx 的配置文件拷贝到根目录,再删除原 nginx 容器,再用映射文件夹的方式来重新启动 nginx 容器。
- 通过 docker 容器安装 nginx 环境。
docker run -p 80:80 --name nginx -d nginx:1.10
- 拷贝 nginx 容器的配置文件到 mydata 目录的 conf 文件夹
cd /mydata
docker container cp nginx:/etc/nginx ./conf
- mydata 目录 里面创建 nginx 目录
mkdir nginx
- 移动 conf 文件夹到 nginx 映射文件夹
mv conf nginx/
- 终止并删除原 nginx 容器
docker stop nginx
docker rm <容器 id>
- 启动新的容器
docker run -p 80:80 --name nginx
-v /mydata/nginx/html:/usr/share/nginx/html
-v /mydata/nginx/logs:/var/log/nginx
-v /mydata/nginx/conf:/etc/nginx
-d nginx:1.10
- 访问 nginx 服务
192.168.56.10
报 403 Forbidden, nginx/1.10.3 则表示 nginx 服务正常启动。403 异常的原因是 nginx 服务下没有文件。
- nginx 目录新建一个 html 文件
cd /mydata/nginx/html
vim index.html
hello passjava
-
再次访问 nginx 服务
浏览器打印 hello passjava。说明访问 nginx 服务的页面没有问题。
-
创建 ik 分词词库文件
cd /mydata/nginx/html
mkdir ik
cd ik
vim ik.txt
填写 悟空哥,并保存文件。
- 访问词库文件
http://192.168.56.10/ik/ik.txt
浏览器会输出一串乱码,可以先忽略乱码问题。说明词库文件可以访问到。
- 修改 ik 分词器配置
cd /mydata/elasticsearch/plugins/ik/config
vim IKAnalyzer.cfg.xml
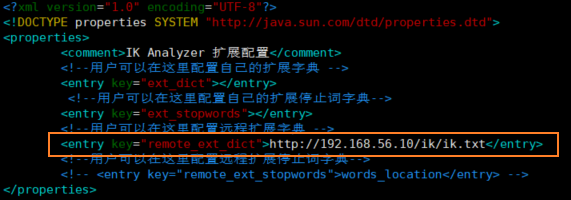
- 重启 elasticsearch 容器并设置每次重启机器后都启动 elasticsearch 容器。
docker restart elasticsearch
docker update elasticsearch --restart=always
- 再次查询分词结果
可以看到 悟空哥聊架构 被拆分为 悟空哥、聊、架构 三个词语,说明自定义词库中的 悟空哥 有作用。

写了两本 PDF,回复 分布式 或 PDF 下载。
我的 JVM 专栏已上架,回复 JVM 领取。
个人网站:www.passjava.cn

