像Mybatis、Hibernate这样的ORM框架,封装了JDBC的大部分操作,极大的简化了我们对数据库的操作。
在实际项目中,我们发现在一个事务中查询同样的语句两次的时候,第二次没有进行数据库查询,直接返回了结果,实际这种情况我们就可以称为缓存。
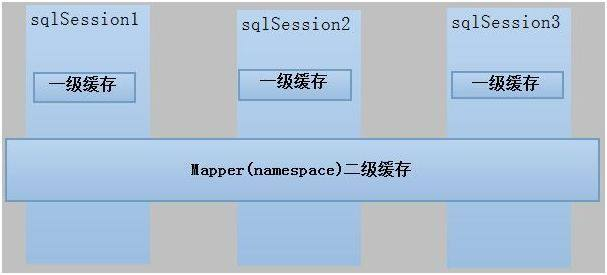
Mybatis的缓存级别
一级缓存
- MyBatis的一级查询缓存(也叫作本地缓存)是基于org.apache.ibatis.cache.impl.PerpetualCache 类的 HashMap本地缓存,其作用域是SqlSession,myBatis 默认一级查询缓存是开启状态,且不能关闭。
- 在同一个SqlSession中两次执行相同的 sql查询语句,第一次执行完毕后,会将查询结果写入到缓存中,第二次会从缓存中直接获取数据,而不再到数据库中进行查询,这样就减少了数据库的访问,从而提高查询效率。
- 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Session,PerpetualCache 对象是在SqlSession中的Executor的localcache属性当中存放,当 Session flush 或 close 之后,该Session中的所有 Cache 就将清空。
二级缓存
- 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap存储,不同在于其存储作用域为 Mapper(Namespace),每个Mapper中有一个Cache对象,存放在Configration中,并且将其放进当前Mapper的所有MappedStatement当中,并且可自定义存储源,如 Ehcache。
- Mapper级别缓存,定义在Mapper文件的<cache>标签并需要开启此缓存
用下面这张图描述一级缓存和二级缓存的关系。
CacheKey
在 MyBatis 中,引入缓存的目的是为提高查询效率,降低数据库压力。既然 MyBatis 引入了缓存,那么大家思考过缓存中的 key 和 value 的值分别是什么吗?大家可能很容易能回答出 value 的内容,不就是 SQL 的查询结果吗。那 key 是什么呢?是字符串,还是其他什么对象?如果是字符串的话,那么大家首先能想到的是用 SQL 语句作为 key。但这是不对的,比如:
SELECT * FROM user where id > ?
id > 1 和 id > 10 查出来的结果可能是不同的,所以我们不能简单的使用 SQL 语句作为 key。从这里可以看出来,运行时参数将会影响查询结果,因此我们的 key 应该涵盖运行时参数。除此之外呢,如果进行分页查询也会导致查询结果不同,因此 key 也应该涵盖分页参数。综上,我们不能使用简单的 SQL 语句作为 key。应该考虑使用一种复合对象,能涵盖可影响查询结果的因子。在 MyBatis 中,这种复合对象就是 CacheKey。下面来看一下它的定义。
public class CacheKey implements Cloneable, Serializable { private static final int DEFAULT_MULTIPLYER = 37; private static final int DEFAULT_HASHCODE = 17; // 乘子,默认为37 private final int multiplier; // CacheKey 的 hashCode,综合了各种影响因子 private int hashcode; // 校验和 private long checksum; // 影响因子个数 private int count; // 影响因子集合 private List<Object> updateList; public CacheKey() { this.hashcode = DEFAULT_HASHCODE; this.multiplier = DEFAULT_MULTIPLYER; this.count = 0; this.updateList = new ArrayList<Object>(); } /** 每当执行更新操作时,表示有新的影响因子参与计算 * 当不断有新的影响因子参与计算时,hashcode 和 checksum 将会变得愈发复杂和随机。这样可降低冲突率,使 CacheKey 可在缓存中更均匀的分布。 */ public void update(Object object) { int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object); // 自增 count count++; // 计算校验和 checksum += baseHashCode; // 更新 baseHashCode baseHashCode *= count; // 计算 hashCode hashcode = multiplier * hashcode + baseHashCode; // 保存影响因子 updateList.add(object); } /** * CacheKey 最终要作为键存入 HashMap,因此它需要覆盖 equals 和 hashCode 方法 */ public boolean equals(Object object) { // 检测是否为同一个对象 if (this == object) { return true; } // 检测 object 是否为 CacheKey if (!(object instanceof CacheKey)) { return false; } final CacheKey cacheKey = (CacheKey) object; // 检测 hashCode 是否相等 if (hashcode != cacheKey.hashcode) { return false; } // 检测校验和是否相同 if (checksum != cacheKey.checksum) { return false; } // 检测 coutn 是否相同 if (count != cacheKey.count) { return false; } // 如果上面的检测都通过了,下面分别对每个影响因子进行比较 for (int i = 0; i < updateList.size(); i++) { Object thisObject = updateList.get(i); Object thatObject = cacheKey.updateList.get(i); if (!ArrayUtil.equals(thisObject, thatObject)) { return false; } } return true; } public int hashCode() { // 返回 hashcode 变量 return hashcode; } }
当不断有新的影响因子参与计算时,hashcode 和 checksum 将会变得愈发复杂和随机。这样可降低冲突率,使 CacheKey 可在缓存中更均匀的分布。CacheKey 最终要作为键存入 HashMap,因此它需要覆盖 equals 和 hashCode 方法。
一级缓存源码解析
一级缓存的测试
同一个session查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",1); Blog blog2 = (Blog)session.selectOne("queryById",1); } finally { session.close(); } }
结论:只有一个DB查询
两个session分别查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); SqlSession session1 = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",17); Blog blog2 = (Blog)session1.selectOne("queryById",17); } finally { session.close(); } }
结论:进行了两次DB查询
同一个session,进行update之后再次查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",17); blog.setName("llll"); session.update("updateBlog",blog); Blog blog2 = (Blog)session.selectOne("queryById",17); } finally { session.close(); } }
结论:进行了两次DB查询
总结:在一级缓存中,同一个SqlSession下,查询语句相同的SQL会被缓存,如果执行增删改操作之后,该缓存就会被删除
创建缓存对象PerpetualCache
我们来回顾一下创建SqlSession的过程
SqlSession session = sessionFactory.openSession(); public SqlSession openSession() { return this.openSessionFromDataSource(this.configuration.getDefaultExecutorType(), (TransactionIsolationLevel)null, false); } private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; DefaultSqlSession var8; try { Environment environment = this.configuration.getEnvironment(); TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); //创建SQL执行器 Executor executor = this.configuration.newExecutor(tx, execType); var8 = new DefaultSqlSession(this.configuration, executor, autoCommit); } catch (Exception var12) { this.closeTransaction(tx); throw ExceptionFactory.wrapException("Error opening session. Cause: " + var12, var12); } finally { ErrorContext.instance().reset(); } return var8; } public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? this.defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Object executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { //默认创建SimpleExecutor executor = new SimpleExecutor(this, transaction); } if (this.cacheEnabled) { //开启二级缓存就会用CachingExecutor装饰SimpleExecutor executor = new CachingExecutor((Executor)executor); } Executor executor = (Executor)this.interceptorChain.pluginAll(executor); return executor; } public SimpleExecutor(Configuration configuration, Transaction transaction) { super(configuration, transaction); } protected BaseExecutor(Configuration configuration, Transaction transaction) { this.transaction = transaction; this.deferredLoads = new ConcurrentLinkedQueue(); //创建一个缓存对象,PerpetualCache并不是线程安全的 //但SqlSession和Executor对象在通常情况下只能有一个线程访问,而且访问完成之后马上销毁。也就是session.close(); this.localCache = new PerpetualCache("LocalCache"); this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache"); this.closed = false; this.configuration = configuration; this.wrapper = this; }
我只是简单的贴了代码,大家可以看我之前的博客,我们可以看到DefaultSqlSession中有SimpleExecutor对象,SimpleExecutor对象中有一个PerpetualCache,一级缓存的数据就是存储在PerpetualCache对象中,SqlSession关闭的时候会清空PerpetualCache
一级缓存实现
再来看BaseExecutor中的query方法是怎么实现一级缓存的,executor默认实现为CachingExecutor
CachingExecutor
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); //利用sql和执行的参数生成一个key,如果同一sql不同的执行参数的话,将会生成不同的key CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql); } @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 这里是二级缓存的查询,我们暂且不看 Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } // 直接来到这里 // 实现为BaseExecutor.query() return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
如上,在访问一级缓存之前,MyBatis 首先会调用 createCacheKey 方法创建 CacheKey。下面我们来看一下 createCacheKey 方法的逻辑:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) { if (closed) { throw new ExecutorException("Executor was closed."); } // 创建 CacheKey 对象 CacheKey cacheKey = new CacheKey(); // 将 MappedStatement 的 id 作为影响因子进行计算 cacheKey.update(ms.getId()); // RowBounds 用于分页查询,下面将它的两个字段作为影响因子进行计算 cacheKey.update(rowBounds.getOffset()); cacheKey.update(rowBounds.getLimit()); // 获取 sql 语句,并进行计算 cacheKey.update(boundSql.getSql()); List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry(); for (ParameterMapping parameterMapping : parameterMappings) { if (parameterMapping.getMode() != ParameterMode.OUT) { // 运行时参数 Object value; // 当前大段代码用于获取 SQL 中的占位符 #{xxx} 对应的运行时参数, // 前文有类似分析,这里忽略了 String propertyName = parameterMapping.getProperty(); if (boundSql.hasAdditionalParameter(propertyName)) { value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == null) { value = null; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } // 让运行时参数参与计算 cacheKey.update(value); } } if (configuration.getEnvironment() != null) { // 获取 Environment id 遍历,并让其参与计算 cacheKey.update(configuration.getEnvironment().getId()); } return cacheKey; }
如上,在计算 CacheKey 的过程中,有很多影响因子参与了计算。比如 MappedStatement 的 id 字段,SQL 语句,分页参数,运行时变量,Environment 的 id 字段等。通过让这些影响因子参与计算,可以很好的区分不同查询请求。所以,我们可以简单的把 CacheKey 看做是一个查询请求的 id。有了 CacheKey,我们就可以使用它读写缓存了。
SimpleExecutor(BaseExecutor)
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 看这里,先从localCache中获取对应CacheKey的结果值
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 如果缓存中没有值,则从DB中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
BaseExecutor.queryFromDatabase()
我们先来看下这种缓存中没有值的情况,看一下查询后的结果是如何被放置到缓存中的
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { // 1.执行查询,获取list list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } // 2.将查询后的结果放置到localCache中,key就是我们刚才封装的CacheKey,value就是从DB中查询到的list localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
我们来看看 localCache.putObject(key, list);
PerpetualCache
PerpetualCache 是一级缓存使用的缓存类,内部使用了 HashMap 实现缓存功能。它的源码如下:
public class PerpetualCache implements Cache { private final String id; private Map<Object, Object> cache = new HashMap<Object, Object>(); public PerpetualCache(String id) { this.id = id; } @Override public String getId() { return id; } @Override public int getSize() { return cache.size(); } @Override public void putObject(Object key, Object value) { // 存储键值对到 HashMap cache.put(key, value); } @Override public Object getObject(Object key) { // 查找缓存项 return cache.get(key); } @Override public Object removeObject(Object key) { // 移除缓存项 return cache.remove(key); } @Override public void clear() { cache.clear(); } // 省略部分代码 }
总结:可以看到localCache本质上就是一个Map,key为我们的CacheKey,value为我们的结果值,是不是很简单,只是封装了一个Map而已。
清除缓存
SqlSession.update()
当我们进行更新操作时,会执行如下代码
@Override public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } //每次执行update/insert/delete语句时都会清除一级缓存。 clearLocalCache(); // 然后再进行更新操作 return doUpdate(ms, parameter); } @Override public void clearLocalCache() { if (!closed) { // 直接将Map清空 localCache.clear(); localOutputParameterCache.clear(); } }
session.close();
//DefaultSqlSession public void close() { try { this.executor.close(this.isCommitOrRollbackRequired(false)); this.closeCursors(); this.dirty = false; } finally { ErrorContext.instance().reset(); } } //BaseExecutor public void close(boolean forceRollback) { try { try { this.rollback(forceRollback); } finally { if (this.transaction != null) { this.transaction.close(); } } } catch (SQLException var11) { log.warn("Unexpected exception on closing transaction. Cause: " + var11); } finally { this.transaction = null; this.deferredLoads = null; this.localCache = null; this.localOutputParameterCache = null; this.closed = true; } } public void rollback(boolean required) throws SQLException { if (!this.closed) { try { this.clearLocalCache(); this.flushStatements(true); } finally { if (required) { this.transaction.rollback(); } } } } public void clearLocalCache() { if (!this.closed) { // 直接将Map清空 this.localCache.clear(); this.localOutputParameterCache.clear(); } }
当关闭SqlSession时,也会清楚SqlSession中的一级缓存
总结
- 一级缓存只在同一个SqlSession中共享数据
- 在同一个SqlSession对象执行相同的sql并参数也要相同,缓存才有效。
- 如果在SqlSession中执行update/insert/detete语句或者session.close();的话,SqlSession中的executor对象会将一级缓存清空。
二级缓存源码解析
二级缓存构建在一级缓存之上,在收到查询请求时,MyBatis 首先会查询二级缓存。若二级缓存未命中,再去查询一级缓存。与一级缓存不同,二级缓存和具体的命名空间绑定,一个Mapper中有一个Cache,相同Mapper中的MappedStatement公用一个Cache,一级缓存则是和 SqlSession 绑定。一级缓存不存在并发问题二级缓存可在多个命名空间间共享,这种情况下,会存在并发问题,比喻多个不同的SqlSession 会同时执行相同的SQL语句,参数也相同,那么CacheKey是相同的,就会造成多个线程并发访问相同CacheKey的值,下面首先来看一下访问二级缓存的逻辑。
二级缓存的测试
二级缓存需要在Mapper.xml中配置<cache/>标签
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.BlogMapper">
<select id="queryById" parameterType="int" resultType="jdbc.Blog">
select * from blog where id = #{id}
</select>
<update id="updateBlog" parameterType="jdbc.Blog">
update Blog set name = #{name},url = #{url} where id=#{id}
</update>
<!-- 开启BlogMapper二级缓存 -->
<cache/>
</mapper>
不同的session进行相同的查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); SqlSession session1 = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",17); Blog blog2 = (Blog)session1.selectOne("queryById",17); } finally { session.close(); } }
结论:执行两次DB查询
第一个session查询完成之后,手动提交,在执行第二个session查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); SqlSession session1 = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",17); session.commit(); Blog blog2 = (Blog)session1.selectOne("queryById",17); } finally { session.close(); } }
结论:执行一次DB查询
第一个session查询完成之后,手动关闭,在执行第二个session查询
public static void main(String[] args) { SqlSession session = sqlSessionFactory.openSession(); SqlSession session1 = sqlSessionFactory.openSession(); try { Blog blog = (Blog)session.selectOne("queryById",17); session.close(); Blog blog2 = (Blog)session1.selectOne("queryById",17); } finally { session.close(); } }
结论:执行一次DB查询
总结:二级缓存的生效必须在session提交或关闭之后才会生效
标签<cache/>的解析
按照之前的对Mybatis的分析,对blog.xml的解析工作主要交给XMLConfigBuilder.parse()方法来实现的


1 // XMLConfigBuilder.parse() 2 public Configuration parse() { 3 if (parsed) { 4 throw new BuilderException("Each XMLConfigBuilder can only be used once."); 5 } 6 parsed = true; 7 parseConfiguration(parser.evalNode("/configuration"));// 在这里 8 return configuration; 9 } 10 11 // parseConfiguration() 12 // 既然是在blog.xml中添加的,那么我们就直接看关于mappers标签的解析 13 private void parseConfiguration(XNode root) { 14 try { 15 Properties settings = settingsAsPropertiess(root.evalNode("settings")); 16 propertiesElement(root.evalNode("properties")); 17 loadCustomVfs(settings); 18 typeAliasesElement(root.evalNode("typeAliases")); 19 pluginElement(root.evalNode("plugins")); 20 objectFactoryElement(root.evalNode("objectFactory")); 21 objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); 22 reflectionFactoryElement(root.evalNode("reflectionFactory")); 23 settingsElement(settings); 24 // read it after objectFactory and objectWrapperFactory issue #631 25 environmentsElement(root.evalNode("environments")); 26 databaseIdProviderElement(root.evalNode("databaseIdProvider")); 27 typeHandlerElement(root.evalNode("typeHandlers")); 28 // 就是这里 29 mapperElement(root.evalNode("mappers")); 30 } catch (Exception e) { 31 throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); 32 } 33 } 34 35 36 // mapperElement() 37 private void mapperElement(XNode parent) throws Exception { 38 if (parent != null) { 39 for (XNode child : parent.getChildren()) { 40 if ("package".equals(child.getName())) { 41 String mapperPackage = child.getStringAttribute("name"); 42 configuration.addMappers(mapperPackage); 43 } else { 44 String resource = child.getStringAttribute("resource"); 45 String url = child.getStringAttribute("url"); 46 String mapperClass = child.getStringAttribute("class"); 47 // 按照我们本例的配置,则直接走该if判断 48 if (resource != null && url == null && mapperClass == null) { 49 ErrorContext.instance().resource(resource); 50 InputStream inputStream = Resources.getResourceAsStream(resource); 51 XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); 52 // 生成XMLMapperBuilder,并执行其parse方法 53 mapperParser.parse(); 54 } else if (resource == null && url != null && mapperClass == null) { 55 ErrorContext.instance().resource(url); 56 InputStream inputStream = Resources.getUrlAsStream(url); 57 XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments()); 58 mapperParser.parse(); 59 } else if (resource == null && url == null && mapperClass != null) { 60 Class<?> mapperInterface = Resources.classForName(mapperClass); 61 configuration.addMapper(mapperInterface); 62 } else { 63 throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one."); 64 } 65 } 66 } 67 } 68 }
我们来看看解析Mapper.xml
// XMLMapperBuilder.parse() public void parse() { if (!configuration.isResourceLoaded(resource)) { // 解析mapper属性 configurationElement(parser.evalNode("/mapper")); configuration.addLoadedResource(resource); bindMapperForNamespace(); } parsePendingResultMaps(); parsePendingChacheRefs(); parsePendingStatements(); } // configurationElement() private void configurationElement(XNode context) { try { String namespace = context.getStringAttribute("namespace"); if (namespace == null || namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } builderAssistant.setCurrentNamespace(namespace); cacheRefElement(context.evalNode("cache-ref")); // 最终在这里看到了关于cache属性的处理 cacheElement(context.evalNode("cache")); parameterMapElement(context.evalNodes("/mapper/parameterMap")); resultMapElements(context.evalNodes("/mapper/resultMap")); sqlElement(context.evalNodes("/mapper/sql")); // 这里会将生成的Cache包装到对应的MappedStatement buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e); } } // cacheElement() private void cacheElement(XNode context) throws Exception { if (context != null) { //解析<cache/>标签的type属性,这里我们可以自定义cache的实现类,比如redisCache,如果没有自定义,这里使用和一级缓存相同的PERPETUAL String type = context.getStringAttribute("type", "PERPETUAL"); Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type); String eviction = context.getStringAttribute("eviction", "LRU"); Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction); Long flushInterval = context.getLongAttribute("flushInterval"); Integer size = context.getIntAttribute("size"); boolean readWrite = !context.getBooleanAttribute("readOnly", false); boolean blocking = context.getBooleanAttribute("blocking", false); Properties props = context.getChildrenAsProperties(); // 构建Cache对象 builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props); } }
先来看看是如何构建Cache对象的
MapperBuilderAssistant.useNewCache()
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval, Integer size, boolean readWrite, boolean blocking, Properties props) { // 1.生成Cache对象 Cache cache = new CacheBuilder(currentNamespace) //这里如果我们定义了<cache/>中的type,就使用自定义的Cache,否则使用和一级缓存相同的PerpetualCache .implementation(valueOrDefault(typeClass, PerpetualCache.class)) .addDecorator(valueOrDefault(evictionClass, LruCache.class)) .clearInterval(flushInterval) .size(size) .readWrite(readWrite) .blocking(blocking) .properties(props) .build(); // 2.添加到Configuration中 configuration.addCache(cache); // 3.并将cache赋值给MapperBuilderAssistant.currentCache currentCache = cache; return cache; }
我们看到一个Mapper.xml只会解析一次<cache/>标签,也就是只创建一次Cache对象,放进configuration中,并将cache赋值给MapperBuilderAssistant.currentCache
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));将Cache包装到MappedStatement
// buildStatementFromContext() private void buildStatementFromContext(List<XNode> list) { if (configuration.getDatabaseId() != null) { buildStatementFromContext(list, configuration.getDatabaseId()); } buildStatementFromContext(list, null); } //buildStatementFromContext() private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) { for (XNode context : list) { final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); try { // 每一条执行语句转换成一个MappedStatement statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } } // XMLStatementBuilder.parseStatementNode(); public void parseStatementNode() { String id = context.getStringAttribute("id"); String databaseId = context.getStringAttribute("databaseId"); ... Integer fetchSize = context.getIntAttribute("fetchSize"); Integer timeout = context.getIntAttribute("timeout"); String parameterMap = context.getStringAttribute("parameterMap"); String parameterType = context.getStringAttribute("parameterType"); Class<?> parameterTypeClass = resolveClass(parameterType); String resultMap = context.getStringAttribute("resultMap"); String resultType = context.getStringAttribute("resultType"); String lang = context.getStringAttribute("lang"); LanguageDriver langDriver = getLanguageDriver(lang); ... // 创建MappedStatement对象 builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); } // builderAssistant.addMappedStatement() public MappedStatement addMappedStatement( String id, ...) { if (unresolvedCacheRef) { throw new IncompleteElementException("Cache-ref not yet resolved"); } id = applyCurrentNamespace(id, false); boolean isSelect = sqlCommandType == SqlCommandType.SELECT; //创建MappedStatement对象 MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType) ... .flushCacheRequired(valueOrDefault(flushCache, !isSelect)) .useCache(valueOrDefault(useCache, isSelect)) .cache(currentCache);// 在这里将之前生成的Cache封装到MappedStatement ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id); if (statementParameterMap != null) { statementBuilder.parameterMap(statementParameterMap); } MappedStatement statement = statementBuilder.build(); configuration.addMappedStatement(statement); return statement; }
我们看到将Mapper中创建的Cache对象,加入到了每个MappedStatement对象中,也就是同一个Mapper中所有的MappedStatement 中的cache属性引用是同一个
有关于<cache/>标签的解析就到这了。
查询源码分析
CachingExecutor
// CachingExecutor public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameterObject); // 创建 CacheKey CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 从 MappedStatement 中获取 Cache,注意这里的 Cache 是从MappedStatement中获取的 // 也就是我们上面解析Mapper中<cache/>标签中创建的,它保存在Configration中 // 我们在上面解析blog.xml时分析过每一个MappedStatement都有一个Cache对象,就是这里 Cache cache = ms.getCache(); // 如果配置文件中没有配置 <cache>,则 cache 为空 if (cache != null) { //如果需要刷新缓存的话就刷新:flushCache="true" flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); // 访问二级缓存 List<E> list = (List<E>) tcm.getObject(cache, key); // 缓存未命中 if (list == null) { // 如果没有值,则执行查询,这个查询实际也是先走一级缓存查询,一级缓存也没有的话,则进行DB查询 list = delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); // 缓存查询结果 tcm.putObject(cache, key, list); } return list; } } return delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
如果设置了flushCache="true",则每次查询都会刷新缓存
<!-- 执行此语句清空缓存 --> <select id="getAll" resultType="entity.TDemo" useCache="true" flushCache="true" > select * from t_demo </select>
如上,注意二级缓存是从 MappedStatement 中获取的。由于 MappedStatement 存在于全局配置中,可以多个 CachingExecutor 获取到,这样就会出现线程安全问题。除此之外,若不加以控制,多个事务共用一个缓存实例,会导致脏读问题。至于脏读问题,需要借助其他类来处理,也就是上面代码中 tcm 变量对应的类型。下面分析一下。
TransactionalCacheManager
/** 事务缓存管理器 */ public class TransactionalCacheManager { // Cache 与 TransactionalCache 的映射关系表 private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>(); public void clear(Cache cache) { // 获取 TransactionalCache 对象,并调用该对象的 clear 方法,下同 getTransactionalCache(cache).clear(); } public Object getObject(Cache cache, CacheKey key) { // 直接从TransactionalCache中获取缓存 return getTransactionalCache(cache).getObject(key); } public void putObject(Cache cache, CacheKey key, Object value) { // 直接存入TransactionalCache的缓存中 getTransactionalCache(cache).putObject(key, value); } public void commit() { for (TransactionalCache txCache : transactionalCaches.values()) { txCache.commit(); } } public void rollback() { for (TransactionalCache txCache : transactionalCaches.values()) { txCache.rollback(); } } private TransactionalCache getTransactionalCache(Cache cache) { // 从映射表中获取 TransactionalCache TransactionalCache txCache = transactionalCaches.get(cache); if (txCache == null) { // TransactionalCache 也是一种装饰类,为 Cache 增加事务功能 // 创建一个新的TransactionalCache,并将真正的Cache对象存进去 txCache = new TransactionalCache(cache); transactionalCaches.put(cache, txCache); } return txCache; } }
TransactionalCacheManager 内部维护了 Cache 实例与 TransactionalCache 实例间的映射关系,该类也仅负责维护两者的映射关系,真正做事的还是 TransactionalCache。TransactionalCache 是一种缓存装饰器,可以为 Cache 实例增加事务功能。我在之前提到的脏读问题正是由该类进行处理的。下面分析一下该类的逻辑。
TransactionalCache
public class TransactionalCache implements Cache { //真正的缓存对象,和上面的Map<Cache, TransactionalCache>中的Cache是同一个 private final Cache delegate; private boolean clearOnCommit; // 在事务被提交前,所有从数据库中查询的结果将缓存在此集合中 private final Map<Object, Object> entriesToAddOnCommit; // 在事务被提交前,当缓存未命中时,CacheKey 将会被存储在此集合中 private final Set<Object> entriesMissedInCache; @Override public Object getObject(Object key) { // 查询的时候是直接从delegate中去查询的,也就是从真正的缓存对象中查询 Object object = delegate.getObject(key); if (object == null) { // 缓存未命中,则将 key 存入到 entriesMissedInCache 中 entriesMissedInCache.add(key); } if (clearOnCommit) { return null; } else { return object; } } @Override public void putObject(Object key, Object object) { // 将键值对存入到 entriesToAddOnCommit 这个Map中中,而非真实的缓存对象 delegate 中 entriesToAddOnCommit.put(key, object); } @Override public Object removeObject(Object key) { return null; } @Override public void clear() { clearOnCommit = true; // 清空 entriesToAddOnCommit,但不清空 delegate 缓存 entriesToAddOnCommit.clear(); } public void commit() { // 根据 clearOnCommit 的值决定是否清空 delegate if (clearOnCommit) { delegate.clear(); } // 刷新未缓存的结果到 delegate 缓存中 flushPendingEntries(); // 重置 entriesToAddOnCommit 和 entriesMissedInCache reset(); } public void rollback() { unlockMissedEntries(); reset(); } private void reset() { clearOnCommit = false; // 清空集合 entriesToAddOnCommit.clear(); entriesMissedInCache.clear(); } private void flushPendingEntries() { for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) { // 将 entriesToAddOnCommit 中的内容转存到 delegate 中 delegate.putObject(entry.getKey(), entry.getValue()); } for (Object entry : entriesMissedInCache) { if (!entriesToAddOnCommit.containsKey(entry)) { // 存入空值 delegate.putObject(entry, null); } } } private void unlockMissedEntries() { for (Object entry : entriesMissedInCache) { try { // 调用 removeObject 进行解锁 delegate.removeObject(entry); } catch (Exception e) { log.warn("..."); } } } }
存储二级缓存对象的时候是放到了TransactionalCache.entriesToAddOnCommit这个map中,但是每次查询的时候是直接从TransactionalCache.delegate中去查询的,所以这个二级缓存查询数据库后,设置缓存值是没有立刻生效的,主要是因为直接存到 delegate 会导致脏数据问题。
为何只有SqlSession提交或关闭之后二级缓存才会生效?
那我们来看下SqlSession.commit()方法做了什么
SqlSession
@Override public void commit(boolean force) { try { // 主要是这句 executor.commit(isCommitOrRollbackRequired(force)); dirty = false; } catch (Exception e) { throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } // CachingExecutor.commit() @Override public void commit(boolean required) throws SQLException { delegate.commit(required); tcm.commit();// 在这里 } // TransactionalCacheManager.commit() public void commit() { for (TransactionalCache txCache : transactionalCaches.values()) { txCache.commit();// 在这里 } } // TransactionalCache.commit() public void commit() { if (clearOnCommit) { delegate.clear(); } flushPendingEntries();//这一句 reset(); } // TransactionalCache.flushPendingEntries() private void flushPendingEntries() { for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) { // 在这里真正的将entriesToAddOnCommit的对象逐个添加到delegate中,只有这时,二级缓存才真正的生效 delegate.putObject(entry.getKey(), entry.getValue()); } for (Object entry : entriesMissedInCache) { if (!entriesToAddOnCommit.containsKey(entry)) { delegate.putObject(entry, null); } } }
如果从数据库查询到的数据直接存到 delegate 会导致脏数据问题。下面通过一张图演示一下脏数据问题发生的过程,假设两个线程开启两个不同的事务,它们的执行过程如下:

如上图,时刻2,事务 A 对记录 A 进行了更新。时刻3,事务 A 从数据库查询记录 A,并将记录 A 写入缓存中。时刻4,事务 B 查询记录 A,由于缓存中存在记录 A,事务 B 直接从缓存中取数据。这个时候,脏数据问题就发生了。事务 B 在事务 A 未提交情况下,读取到了事务 A 所修改的记录。为了解决这个问题,我们可以为每个事务引入一个独立的缓存。查询数据时,仍从 delegate 缓存(以下统称为共享缓存)中查询。若缓存未命中,则查询数据库。存储查询结果时,并不直接存储查询结果到共享缓存中,而是先存储到事务缓存中,也就是 entriesToAddOnCommit 集合。当事务提交时,再将事务缓存中的缓存项转存到共享缓存中。这样,事务 B 只能在事务 A 提交后,才能读取到事务 A 所做的修改,解决了脏读问题。
二级缓存的刷新
我们来看看SqlSession的更新操作
public int update(String statement, Object parameter) { int var4; try { this.dirty = true; MappedStatement ms = this.configuration.getMappedStatement(statement); var4 = this.executor.update(ms, this.wrapCollection(parameter)); } catch (Exception var8) { throw ExceptionFactory.wrapException("Error updating database. Cause: " + var8, var8); } finally { ErrorContext.instance().reset(); } return var4; } public int update(MappedStatement ms, Object parameterObject) throws SQLException { this.flushCacheIfRequired(ms); return this.delegate.update(ms, parameterObject); } private void flushCacheIfRequired(MappedStatement ms) { //获取MappedStatement对应的Cache,进行清空 Cache cache = ms.getCache(); //SQL需设置flushCache="true" 才会执行清空 if (cache != null && ms.isFlushCacheRequired()) { this.tcm.clear(cache); } }
MyBatis二级缓存只适用于不常进行增、删、改的数据,比如国家行政区省市区街道数据。一但数据变更,MyBatis会清空缓存。因此二级缓存不适用于经常进行更新的数据。
使用redis存储二级缓存
通过上面代码分析,我们知道二级缓存默认和一级缓存都是使用的PerpetualCache存储结果,一级缓存只要SQLSession关闭就会清空,其内部使用HashMap实现,所以二级缓存无法实现分布式,并且服务器重启后就没有缓存了。此时就需要引入第三方缓存中间件,将缓存的值存到外部,如redis和ehcache
修改mapper.xml中的配置。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.tyb.saas.common.dal.dao.AreaDefaultMapper">
<!--
flushInterval(清空缓存的时间间隔): 单位毫秒,可以被设置为任意的正整数。
默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目): 可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读):属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。
因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
eviction(回收策略): 默认的是 LRU:
1.LRU – 最近最少使用的:移除最长时间不被使用的对象。
2.FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3.SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
4.WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
blocking(是否使用阻塞缓存): 默认为false,当指定为true时将采用BlockingCache进行封装,blocking,阻塞的意思,
使用BlockingCache会在查询缓存时锁住对应的Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,
这样可以阻止并发情况下多个线程同时查询数据,详情可参考BlockingCache的源码。
type(缓存类):可指定使用的缓存类,mybatis默认使用HashMap进行缓存,这里引用第三方中间件进行缓存
-->
<cache type="org.mybatis.caches.redis.RedisCache" blocking="false"
flushInterval="0" readOnly="true" size="1024" eviction="FIFO"/>
<!--
useCache(是否使用缓存):默认true使用缓存
-->
<select id="find" parameterType="map" resultType="com.chenhao.model.User" useCache="true">
SELECT * FROM user
</select>
</mapper>
依然很简单, RedisCache 在保存缓存数据和获取缓存数据时,使用了Java的序列化和反序列化,因此需要保证被缓存的对象必须实现Serializable接口。
也可以自己实现cache
实现自己的cache
package com.chenhao.mybatis.cache; import org.apache.ibatis.cache.Cache; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.ValueOperations; import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; /** * @author chenhao * @date 2019/10/31. */ public class RedisCache implements Cache { private final String id; private static ValueOperations<String, Object> valueOs; private static RedisTemplate<String, String> template; public static void setValueOs(ValueOperations<String, Object> valueOs) { RedisCache.valueOs = valueOs; } public static void setTemplate(RedisTemplate<String, String> template) { RedisCache.template = template; } private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); public RedisCache(String id) { if (id == null) { throw new IllegalArgumentException("Cache instances require an ID"); } this.id = id; } @Override public String getId() { return this.id; } @Override public void putObject(Object key, Object value) { valueOs.set(key.toString(), value, 10, TimeUnit.MINUTES); } @Override public Object getObject(Object key) { return valueOs.get(key.toString()); } @Override public Object removeObject(Object key) { valueOs.set(key.toString(), "", 0, TimeUnit.MINUTES); return key; } @Override public void clear() { template.getConnectionFactory().getConnection().flushDb(); } @Override public int getSize() { return template.getConnectionFactory().getConnection().dbSize().intValue(); } @Override public ReadWriteLock getReadWriteLock() { return this.readWriteLock; } }
Mapper中配置自己实现的Cache
<cache type="com.chenhao.mybatis.cache.RedisCache"/>