数据格式:
cmt_id: 影评ID编号, 主键
cmt_cont: 未切割影评数据(原始影评数据)
cmt_star: 评分(星数)
cmt_time: 发布时间
cmt_user: 发布者url
cmt_thumbs: 评论点赞数
评论星数
评论星数在html网页dom结构中对应的标签:<span class="allstar20 rating" title="较差"></span>
星数的映射关系为:
1颗星:很差
2颗星:较差
3颗星:还行
4颗星:推荐
5颗星:力荐
抽取过程中,将以数字代表星数,不记录文字表述
项目构建步骤
一、 利用virtualenv创建虚拟沙盒
mkdir DouBanMovieProVenv
virtualenv —distribute DouBanMovieProVenv/
cd DouBanMovieProVenv/
# 启动虚拟环境
source bin/activate
二、安装依赖包
pip install scrapy
pip install pymongo
pip install beautifulsoup4
三、创建scrapy项目
创建scrapy项目, 用来实现影评数据的抓取
scrapy start project JediEscapePro
四 、撸代码啦
scrapy爬虫构建过程:
scrapy项目过程分为四个模块, 即分别定义item, spider, pipeline, settings
1、定义item
item项对应影评数据结构,基本就是你要从抓取的网页中提取的元数据, 实际上就是一个comment对象
item :
--- cmt_id
--- cmt_cont
--- cmt_star
--- cmt_time
--- cmt_user
--- cmt_thumbs
2、抓取网页,提取item元数据
通过对影评html网页的分析,发现每条影评对应一个div[@class="comment-item"]标签,该标签中包含了我们需要提取的各个item项,对应关系如下:
--- cmt_id: 对应div标签的data-cid属性值
--- cmt_cont:div标签的子标签p的text值
--- cmt_star:span[@class='comment-info']的子标签span的title属性值
--- cmt_time:span[@class='comment-info']的子标签span的text值,直接用正则匹配re("d{4}-d{2}-d{2}")[0]
--- cmt_user:span[@class='comment-info']的子标签a的href属性值
--- cmt_thumbs:span[@class='comment-vote']的子标签span的文本值
得出各个item项对应的标签元素,利用xpath进行索引,获取元素信息。xpath的内容请参考:http://www.w3school.com.cn/xpath/
3、定义pipeline
本项目使用面向文档的mongoDB数据库,方便以后影评数据字段的动态扩充。此处主要定义一些基本的增删改查操作,需要注意的是:
在抓取过程中,将通过已有记录实现重复记录的过滤,避免重复抓取。为了应对反爬虫,将对抓取频率进行限制,并可能多次抓取,在此过程中评论的点赞数
是可能更新的,因此将对cmt_thumbs实现实时更新。
4、settings设置
// 设置5秒内的随机延迟
DOWNLOAD_DELAY = 5
RANDOMIZE_DOWNLOAD_DELAY = True
// 多个用户代理,随机切换
USER_AGENT_LIST =[...]
// 多个cookie,随机切换
COOKIES = [...]
5、反反爬虫策略
豆瓣影评数据未登陆状态下,只能抓取200条左右,因此探索过程中,采取了模拟表单登陆
1)表单提交登陆
form_data = {
'source': 'movie',
'redir': "https://movie.douban.com/subject/24529353/comments?start=20",
'form_email': 'your email',
'form_password': 'your password',
'remember': "on",
'login': "登录".decode("utf-8")
}
return [FormRequest.from_response(response,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
formdata=form_data,
callback=self.after_login,
dont_filter=True)]
表单登陆能够成功,仅限于未出现验证码的情况,有验证码后,尝试过假如验证码信息,但未成功,也尝试过识别验证码,效果不佳。
2) 带cookie请求,模拟登陆
因此,选择了带cookie请求的方式:首先,利用firefox从浏览器端正常登陆豆瓣,登陆成功后获取到当前cookie信息,拷贝到settings中的COOKIES。
在请求网页时,采用如下方式,带上cookie信息,就可以正常请求了:
for url in response.xpath("//a[@class='next']/@href").extract():
yield Request('https://movie.douban.com/subject/24529353/comments'+url,
callback=self.parse, cookies=random.choice(COOKIES))
response.xpath(...)提取的下一页的链接。
6、评论者信息抓取
对于评论者信息的抓取,简单采用urlli2模块即可,url来源于cmt_user。抓取过程中,同样带上cookie信息。抓取的数据项包括:
url: 用户主页链接(已有)
area: 用户所属地区,如“江苏南京”
join_time: 用户注册时间
nick_name: 用户昵称
7、数据简单分析
对所获取的影评数据从评星数,相关星级点赞数两个方面进行统计分析,如下:

可以看出,该片整体市场反应一般,评分不高
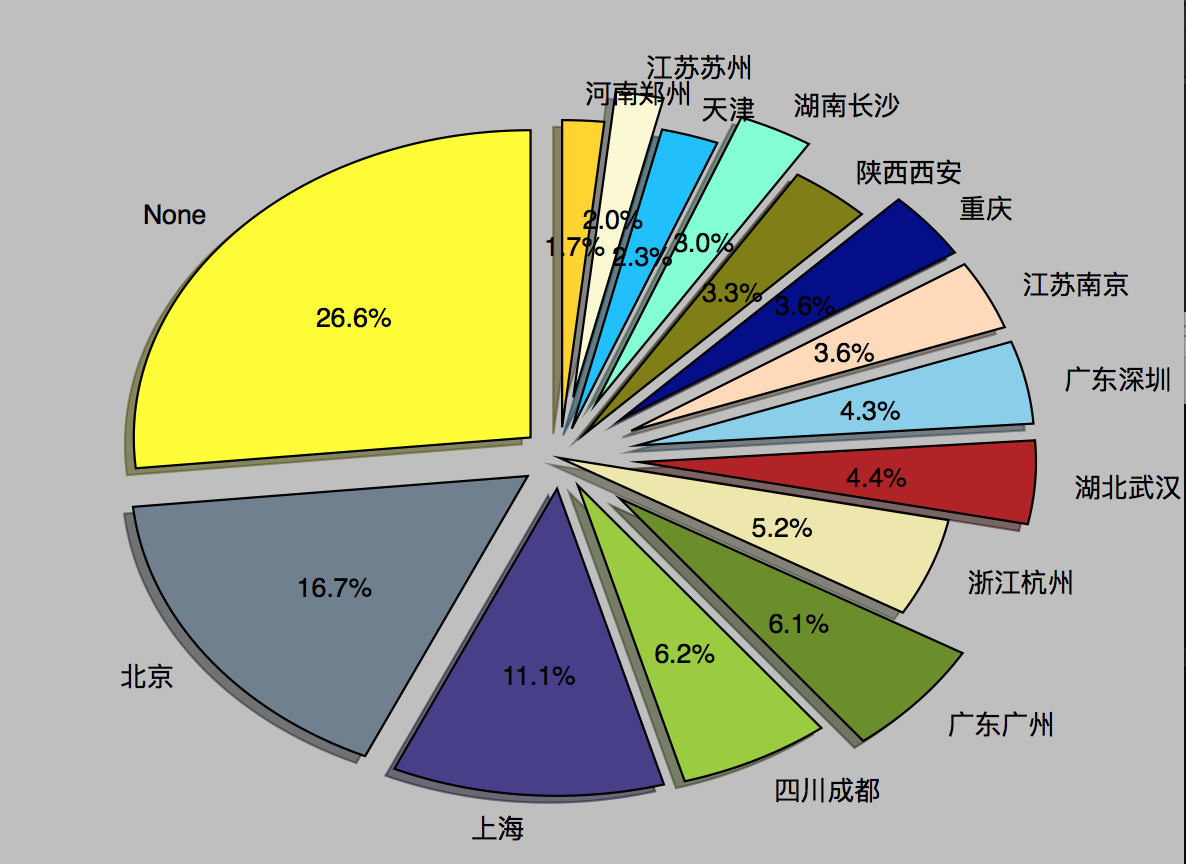
对抓取得到的一万多个用户数据进行分析,得出这些用户共来自于国内外的520的区域,占有率较高的前15个区域人数和占比如下:
用户相关:
total area is: 520
area -> counts: None, 2111 // 用户注册未登录区域信息可能
area -> counts: 北京, 1323
area -> counts: 上海, 878
area -> counts: 四川成都, 490
area -> counts: 广东广州, 483
area -> counts: 浙江杭州, 409
area -> counts: 湖北武汉, 347
area -> counts: 广东深圳, 345
area -> counts: 江苏南京, 289
area -> counts: 重庆, 283
area -> counts: 陕西西安, 262
area -> counts: 湖南长沙, 241
area -> counts: 天津, 184
area -> counts: 江苏苏州, 155
area -> counts: 河南郑州, 135
8、词云展现
对所有影评数据做分词、去停用词处理,去掉词长为1的词,获取词频统计信息后,得出的词云如下:

五、解决的问题
1、 403错误
定义UserAgent, request带cookie
cookie的获取:
首先,用自己的账号登陆,利用google chrome 或者 firefox 得到cookie信息, 将 cookie拷贝到本地,防置在request中, 如下:
for url in response.xpath("//a[@class='next']/@href").extract():
yield Request('https://movie.douban.com/subject/24529353/comments'+url, callback=self.parse, cookies=cookie)
2、 未登录抓取有限
模拟cookie登录
3、 模拟表单提交登录
表单提交登陆,在有验证码时登陆未成功,不知道什么问题
form_data = {
'source': 'movie',
'redir': "https://movie.douban.com/subject/24529353/comments?start=20",
'form_email': 'your email',
'form_password': 'your password',
'remember': "on",
'login': "登录".decode("utf-8")
}
return [FormRequest.from_response(response,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
formdata=form_data,
callback=self.after_login,
dont_filter=True)]
4、解决验证码问题
ocr验证码识别,但未成功
5、wordcloud词云显示中文乱码
wc = WordCloud(background_color="white", max_words=2000, mask=alice_coloring, max_font_size=40,
random_state=42, font_path="/Library/Fonts/Kaiti.ttc")
加入font_path,指向本地系统的楷体字体路径(mac os)