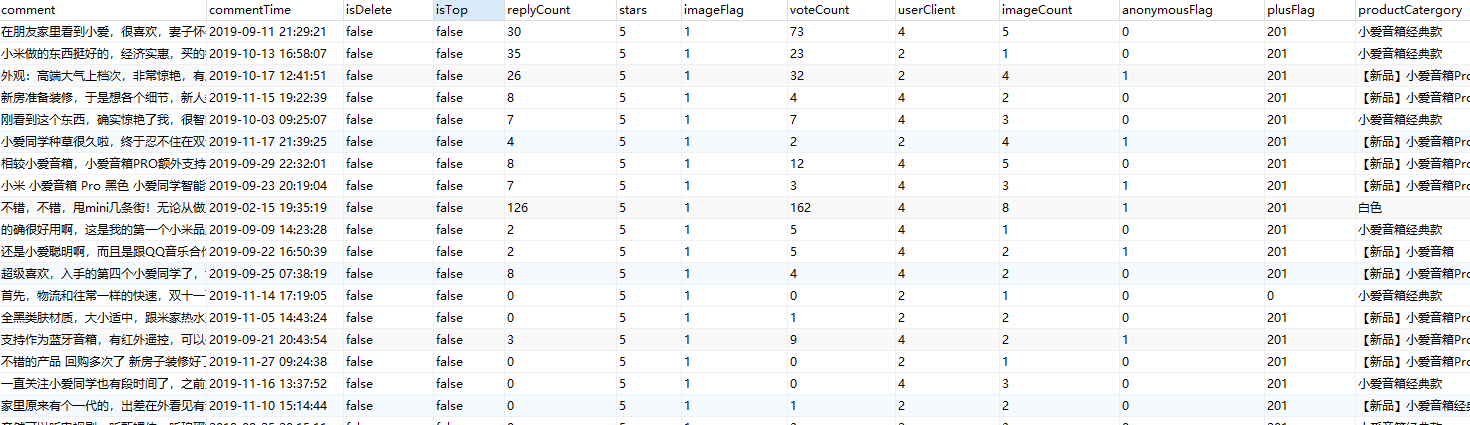
import requests from bs4 import BeautifulSoup as bs import re import pandas as pd from sqlalchemy import create_engine from pandas.io.sql import to_sql as pd_sql import pymysql import random import time # 定义pandas存入mysql函数 def pandas_to_mysql(df_data, table_name, **kwargs): engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset={}'.format(kwargs['user'],kwargs['password'],kwargs['host'],kwargs['port'],kwargs['db'],kwargs['charset'])) pd_sql(df_data, table_name, engine, index=False, if_exists='append', chunksize=10000) # if_exists: 'replace', 'append' engine.dispose() db_local_hwdata = {'user':'root', 'password':'8888', 'port': 3306, 'host':'localhost', 'db': 'hwdata', 'charset': 'utf8mb4'} # 设置代理池 proxies = { 'http':'http://120.83.110.65:9999', 'http':'http://183.146.156.209:9999', 'http':'http://123.169.34.94:9999', 'http':'http://117.57.90.141:9999', 'http':'http://117.69.201.19:9999', 'http':'http://117.95.192.240:9999', 'http':'http://117.95.192.240:9999', 'http':'http://163.204.244.161:9999', 'http':'http://163.204.246.168:9999', 'http':'http://171.35.160.62:9999', 'http':'http://36.22.77.186:9999', 'http':'http://120.83.107.184:9999', } url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv33766&productId=5239477&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1' # 商品链接 headers = { 'Referer': 'https://item.jd.com/5239477.html', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'} result = requests.get(url, headers=headers, proxies=proxies) result_text = result.text result_text = result_text.replace('\n', '') comment_number = re.search('"commentCount":([d]+),', result_text, re.S).group(1) # 所有评论的数量,用于分页,每页评论数量为10 # 遍历,10个评论一页 for page_i in range(0, int(int(comment_number)/10)): time.sleep(random.uniform(0.6, 4)) url = f'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv33766&productId=5239477&score=0&sortType=5&page={page_i}&pageSize=10&isShadowSku=0&fold=1' result = requests.get(url, headers=headers, proxies=proxies) result_text = result.text result_text = result_text.replace('\n', '') analyse_result = re.findall('"guid":"(.*?)",.*?"content":"(.*?)",.*?"creationTime":"(.*?)".*?"isDelete":(.*?),.*?"isTop":(.*?),.*?"replyCount":(.*?),.*?"score":(.*?),.*?"imageStatus":(.*?),.*?"usefulVoteCount":(.*?),.*?"userClient":(.*?),.*?"imageCount":(.*?),.*?"anonymousFlag":(.*?),.*?"plusAvailable":(.*?),.*?"productColor":"(.*?)".*?"imageIntegral".*?,(.*?)"status".*?,"referenceTime":"(.*?)".*?nickname":"(.*?)".*?"days":(.*?),.*?"afterDays":(.*?)}', result_text, re.S) final_data = [] for rt in analyse_result: person_data = [] for ch_i, character in enumerate(rt): if ch_i == 14 and (character != ''): try: character = re.search('"content":"(.*?)",', character, re.S).group(1) except: character = '' if ch_i == 18 and (int(character)< int(rt[-2])): character = '' person_data.append(character) final_data.append(person_data) dfanalyse_result = pd.DataFrame(final_data, columns=['commentUrl', 'comment', 'commentTime', 'isDelete', 'isTop', 'replyCount', 'stars', 'imageFlag', 'voteCount', 'userClient', 'imageCount', 'anonymousFlag', 'plusFlag', 'productCatergory', 'afterComment', 'purchaseTime', 'userName', 'commentAfterBuyingTime', 'afterCommentAfterBuyingTime']) # 将数据转换为DataFrame格式 pandas_to_mysql(dfanalyse_result, 'w20191212jingdong_comments', **db_local_hwdata) # 存入mysql print(f'page_i{page_i} finished!')