from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
对比决策树和随机森林
# 红酒数据集
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)
# 构建模型,用决策树和随机森林进行对比
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(X_train, y_train)
rfc = rfc.fit(X_train, y_train)
score_d = clf.score(X_test, y_test)
score_r = rfc.score(X_test, y_test)
print(score_d, score_r)
0.9074074074074074 0.9814814814814815
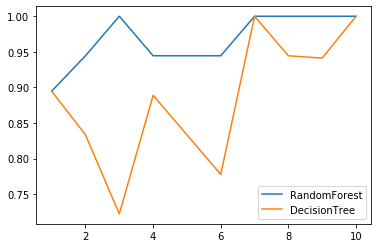
#### 交叉验证下对比
```python
import matplotlib.pyplot as plt
## 1 次交叉验证的结果
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10)
plt.plot(range(1, 11), rfc_s, label='RandomForest')
plt.plot(range(1, 11), clf_s, label='DecisionTree')
plt.legend()
plt.show()
# 从图中可以看出,随机森林的效果比 决策树的效果好
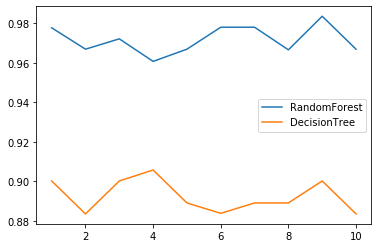
# 10 次交叉验证后,取均值查看效果
rfc_slist = []
clf_slist = []
for i in range(1, 11):
rfc = RandomForestClassifier(n_estimators=25)
clf = DecisionTreeClassifier()
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()
rfc_slist.append(rfc_s)
clf_slist.append(clf_s)
plt.plot(range(1, 11), rfc_slist, label='RandomForest')
plt.plot(range(1, 11), clf_slist, label='DecisionTree')
plt.legend()
plt.show()
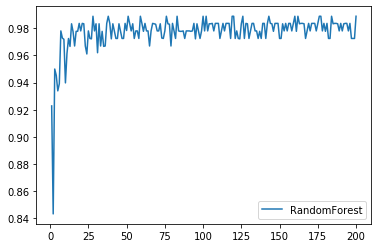
# n_estimator的学习曲线
# 此代码运行时间较长,大约3min
estimator_list = []
for i in range(1, 201):
rfc = RandomForestClassifier(n_estimators=i)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
estimator_list.append(rfc_s)
plt.plot(range(1, 201), estimator_list, label='RandomForest')
plt.legend()
plt.show()
# 可以看出,在迭代到25次时候,随机森林的数据已趋近于一个值的
## 查看随机森林中决策树的参数
rfc = RandomForestClassifier(n_estimators=25)
rfc.fit(X_train, y_train)
rfc.estimators_ # 查看每一棵树的参数,可以看到每一棵树的随机种子不一样
[DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=1242025449, splitter='best'),
... ... 共25个决策树
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=392066908, splitter='best')]
随机森林的袋外数据
- 在有放回的抽样中,有一部分数据会被反复抽到,可能有一部分数据一直没有被抽到,这部分数据就叫做袋外数据
- 袋外数据的比例大约是 37%, 通过 1- ( 1 - 1/ n) ^ n ,无穷大时候收敛于 1 - (1/e) 来得到
- 袋外数据可以用于做测试集,且在实例化随机森林时候,oob_score=True,默认是False状态
- 袋外数据使用时候,就不用划分测试集 和 训练集
- 袋外数据适用于数据量较大的情况,如果数据量较小,就可能出现没有袋外数据的情况
rfc = RandomForestClassifier(n_estimators=25, oob_score=True)
# 此时不用划分训练集和测试集
rfc = rfc.fit(wine.data, wine.target)
# 查看属性
rfc.oob_score_
0.9662921348314607
rfc.estimators_
[DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=425839601, splitter='best'),
... ...
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=720743806, splitter='best')]
重要接口
rfc.feature_importances_
array([0.18197243, 0.03502596, 0.01272023, 0.03099205, 0.03664106,
0.0383327 , 0.13369377, 0.0025354 , 0.01213011, 0.10785671,
0.05097174, 0.19950555, 0.15762229])
rfc.apply(X_test)
array([[ 6, 5, 8, ..., 3, 2, 10],
[ 6, 5, 8, ..., 3, 2, 10],
[17, 18, 18, ..., 22, 10, 20],
...,
[17, 18, 18, ..., 22, 10, 20],
[ 6, 5, 15, ..., 3, 2, 10],
[23, 18, 18, ..., 25, 10, 20]], dtype=int64)
rfc.predict(X_test)
array([1, 1, 0, 2, 1, 1, 1, 0, 0, 2, 1, 1, 1, 1, 2, 0, 0, 2, 2, 1, 1, 1,
2, 1, 0, 2, 2, 0, 0, 2, 1, 2, 0, 1, 2, 1, 1, 2, 0, 1, 0, 0, 2, 2,
0, 0, 2, 0, 2, 0, 1, 0, 1, 0])
# 一行是一个样本在不同类别中的概率
rfc.predict_proba(X_test)
array([[0. , 1. , 0. ],
[0. , 1. , 0. ],
[1. , 0. , 0. ],
[0. , 0. , 1. ],
... ... 有多少个样本,就又多少个概率数据
[0. , 0. , 1. ],
[1. , 0. , 0. ],
[0.04, 0.96, 0. ],
[0.96, 0.04, 0. ],
[0. , 1. , 0. ],
[0.96, 0.04, 0. ]])
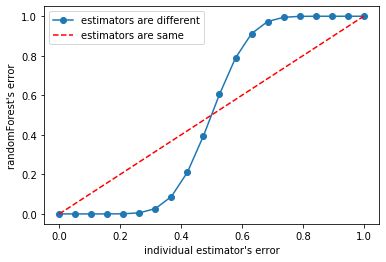
from scipy.special import comb
import numpy as np
x = np.linspace(0, 1, 20)
y = []
# 随机生成 0~1 之间的小数,看不同概率的 数据对随机森林 和 单一决策树的影响
for epsilon in np.linspace(0, 1, 20):
E = np.array([comb(25, i)*(epsilon**i)*((1-epsilon)**(25-i)) for i in range(13, 26)]).sum()
y.append(E)
plt.plot(x, y, 'o-', label='estimators are different')
plt.plot(x, x, '--', color='red', label='estimators are same')
plt.xlabel("individual estimator's error")
plt.ylabel("randomForest's error")
plt.legend()
plt.show()
# 下图中,红色表示 决策树 预测准确率
# 蓝色表示 决策树 的准确率 对应的 随机森林的准确率
# 可以看到,如果单棵决策树的准确率小于50%了,就不要使用此随机森林建模了,误差会更大