QtSpim使用记录
垃圾QtSpim,输入中文会死机
MIPS的中文资料奇缺,如果有问题建议google参考英文资料,许多外国大学的网站上有对MIPS各方面的详细介绍

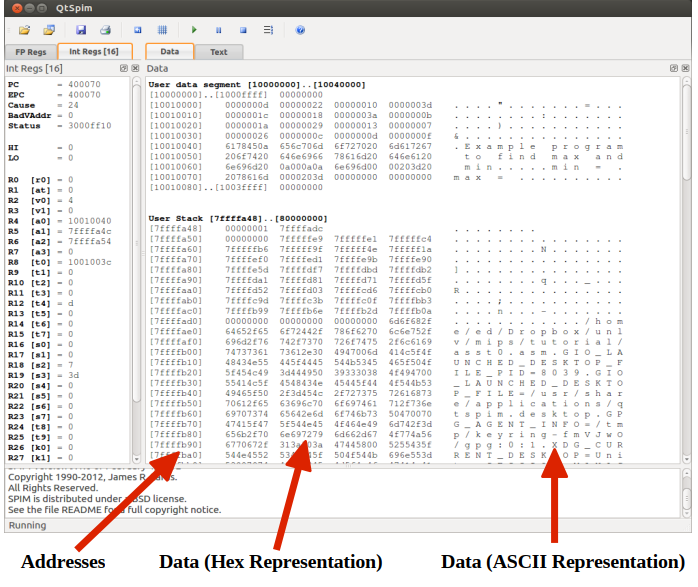
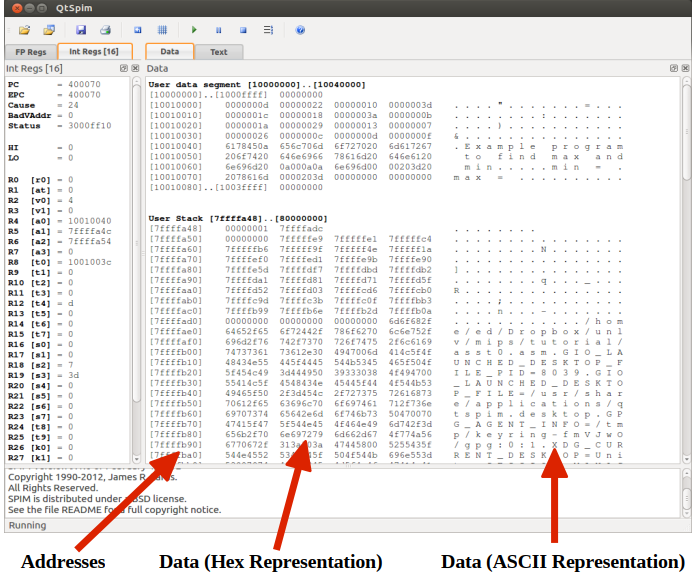
QtSpim是MIPS处理器的模拟器,它的编辑环境并不是太好,一般另外找编辑器进行编辑。
Data标签下存放数据段的数据,Text标签下存放代码段代码,
The assembly process occurs as the file is being loaded. As such, any assembly syntax
errors (i.e., misspelled instructions, undefined variables, etc.) are caught at this point.
An appropriate error message is provided with a reference to the line number that
caused the error.
When the file load is completed with no errors, the program is ready to run, but has not
yet been executed. The screen will appear something like the following image.
其实当文件载入的时候语法分析就已经完成了,如果有语法错误会报错,没报错就是通过语法分析了。
The code is placed in Text Window. The first column of hex values (in the []'s) is the
address of that line of code. The next hex value is the OpCode or hex value of the 1's
and 0's that the CPU understands to be that instruction.MIPS includes pseudo-instructions. That is an instruction that the CPU does not
execute, but the programmer is allowed to use. The assembler, QtSpim here, accepts the
instruction and inserts the real or bare instruction as appropriate
上述两个引用都来自于:http://www.egr.unlv.edu/~ed/MIPStextSMv11.pdf
text下第四栏是我们写的MIPS伪指令,而第三列是伪指令翻译成的真实的CPU指令,第二列是这些指令在内存中的储存结果,第一列是内存地址(指的是第一个字节位,从低到高)
你说这对于programmer有什么用?2333对于初学者而已好像确实没什么用,但是起码人家把最底层的盖子完完整整地掀开了。
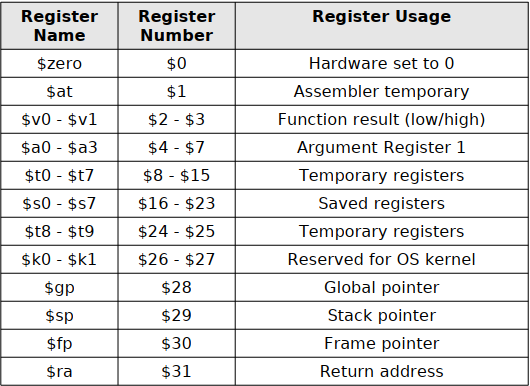
Data项用一个图就能说明:
各个寄存器的作用:


MIPS各段的含义:
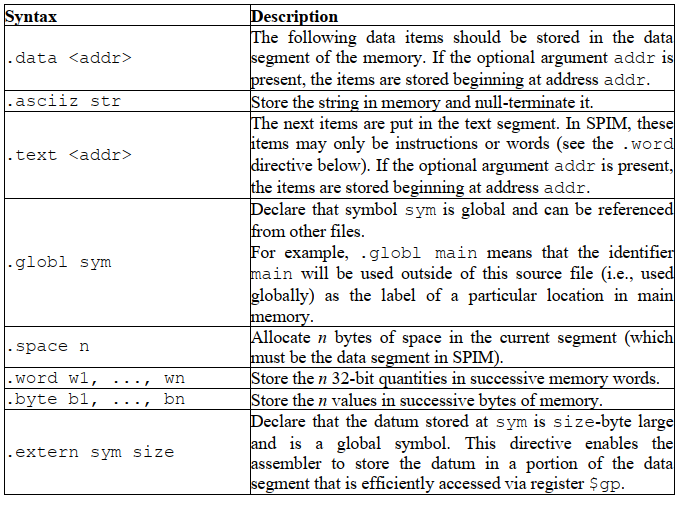
注意这里不是global,而是globl,少了一个a2333
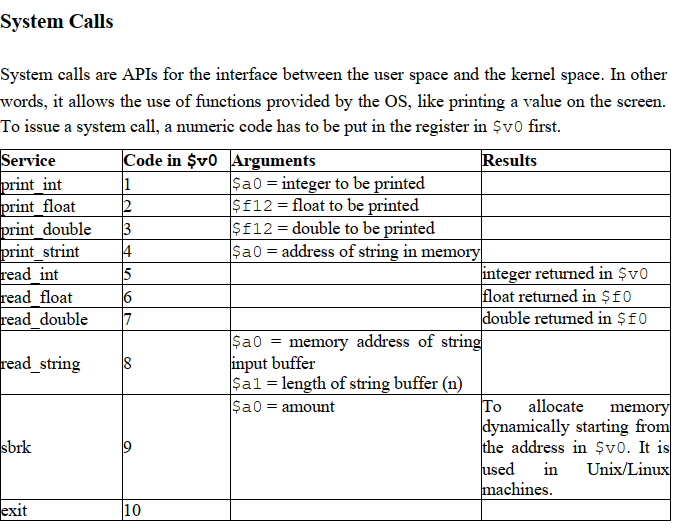
注意,System calls的操作数都必须放在$v0中,数据往往放置在a0中(也有例外,例如表中的print_float和print_double)
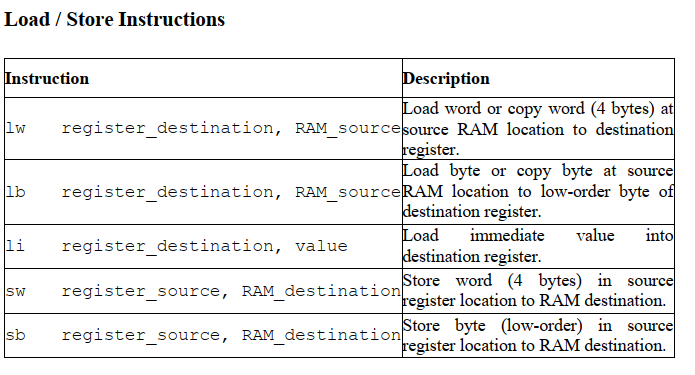
l开头的是从内存加载到寄存器,s开头的是从寄存器写入到内存
还有一个这里没有提到,就是la:load address,对于string(当然这里string是用asciiz表示的)常常是这样操作
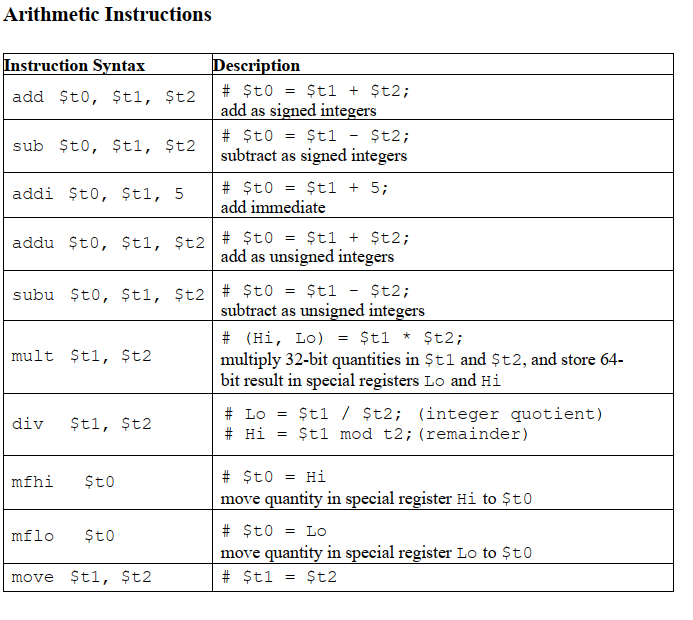
第一个寄存器是结果储存位置,之后的是计算所需的

指令备忘
SLT:
R1起到了flag的作用
BEQ:

j:

如何在MIPS中写if else语句?

if else框架:
高级语言描述
if(a<b)
c=1;
else
c=2;
MISP描述:
a,b,c分别存放在$v2$v3$v4中,$0中存放0(这个是固定的)
slt $5,$2,$3//如果$2<$3,$5中为1
beg $5,$0,Else//通向else
li $v4,1
j Endif
Else:
li $v4,2
Endif:
如何退出程序?
li $v0 10 # 退出
syscall

如何写函数?
.text
main:
li $t0, 1
jal procedure # call procedure
li $v0, 10
syscall
procedure:
li $t0, 3
jr $ra # return
如何声明数组?
Code Implementations Dealing with Arrays
Here are several examples, to promote understanding of how assembly language implements code that deals with arrays.
1-Dimensional Arrays
Declarations
One way to declare an array of 13 characters:
my_chars: .byte 0:13What was the initial value of each of these declared array elements? Answer: The null character (
'�'in C).An alternative way to declare the array of 13 characters:
my_chars: .space 13What is the difference between these two declarations? Answer: The first way initializes this declared memory space before the program begins execution. The second way (with the
.spacedirective) does not initialize memory. It allocates the 13 bytes, but does not change their contents before the program begins its execution.And if we wanted to declare the array of 13 characters, but initialize each character to the value
'A'?:my_As: .byte 'A':13Alternatively:
my_As: .byte 65:13This second way works fine, but may be less clear to a programmer looking at the code. This second way initializes each byte of the array to contain the 8-bit, two's complement representation for the decimal value 65. Since that is the ASCII character encoding for
'A', it works equally well.To declare an array of integer-sized elements, recall that on the MIPS architecture, each integer requires 4 bytes (or 32 bits). Also, each word on the MIPS architecture is 4 bytes. Therefore, we may use the
.worddirective to declare an array of integers:int_array: .word 0:36This declaration allocates 36 words (integer-sized memory chunks), which are all (nicely) located at word-aligned addresses. The initial value of each array element is 0.
If, instead, we wanted an array of 36 integers, where each element is initialized to the value 2, we may use:
all_twos: .word 2:36The
.spacedirective might be used to declare an array of integer-sized elements, but can be problematic. Consider the declaration:array: .space 10025 integer-sized elements are allocated as desired, but there is no guarantee that each of the elements are at word-aligned addresses. Therefore, this declaration plus code that does
la $8, array lw $9, 12($8) # load the 4th element of the arraymay result in an unaligned address exception when the program executes.
A related declaration issue that is beyond the scope of this class is the alignment of data within an array, when each element contains more than a single field. An example from the C is an array of structures, where each structure has more than one field. The difficulty of the allocation may be seen with the sample structure:
struct fivebytes { int oneint; char onechar; } fivebytes array[10];Code to work with elements of this array makes it difficult to load/store the integer-sized, and non-word aligned
oneintCode
Assembly language code (high level language code, too!) that does array access may be generally classified as doing either regular accesses or random accesses. A regular access is one that might be stated such as "for each element of the array, do something." Or, "for every 3rd element of the array, do something." A random access is more of an isolated element access similar to the C code:
int array[12]; /* declare an array of 12 integers */ int x; x = 4; array[x] = -23;The code that does a random array element access tends to follow a fixed pattern (a series of steps), as generated by a compiler.
- Get the base address of the array.
- Calculate an offset by multiplying the array index by the size of each element (in bytes on the MIPS architecture, which is byte addressible).
- Add the base address to the offset, to form the address of the desired array element.
- Load or store to the desired element using the calculated address.
Here is a MIPS assembly language implementation of the C code fragment for the isolated (random) element access:
.data array: .word 0:12 # array of 12 integers .text li $8, 4 # $8 is the index, and variable x la $9, array # $9 is the base address of the array mul $10, $8, 4 # $10 is the offset add $11, $10, $9 # $11 is the address of array[4] li $12, -23 # $12 is the value -23, to be put in array[4] sw $12, ($11)A regular access will be done within a structured loop. Once the address of the initial element is calculated, further array element addresses are calculated relative to the known one. Only the address changes. This reduces the amount of code necessary within the loop, which results in fewer instructions executed and (therefore) faster code.
Consider the implementation of a code example that is to re-initialize each element of an array of 100 integers to be the value 18. A less efficient implementation places the isolated element access code into a loop. This implementation tries to use the same registers for clarity of the example.
.data array: .word 0:100 # array of 100 integers .text li $8, 0 # $8 is the index, and loop induction variable li $13, 100 # $13 is the sentinel value for the loop for: bge $8, $13, end_for la $9, array # $9 is the base address of the array mul $10, $8, 4 # $10 is the offset add $11, $10, $9 # $11 is the address of desired element li $12, 18 # $12 is the value 18, to be put in desired element sw $12, ($11) add $8, $8, 1 # increment loop induction variable b for end_for:More efficient code to do the same thing increments only the address of the desired element within the loop. As many instructions as possible are removed from within the loop.
.data array: .word 0:100 # array of 100 integers .text li $8, 0 # $8 is the loop induction variable li $13, 100 # $13 is the sentinal value for the loop la $9, array # $9 starts as the base address of the array # and is the address of each element li $12, 18 # $12 is the value 18, to be put in desired element for: bge $8, $13, end_for sw $12, ($9) add $9, $9, 4 # get address of next array element add $8, $8, 1 # increment loop induction variable b for end_for:This code might be made even more efficient by eliminating the loop induction variable ($8), instead calculating the address of the last element and using it to decide when to exit the loop. Note that this eliminates a single instruction from within the body of the loop.
2-Dimensional Arrays
There is little formal syntax (in assembly language) to declare or use a 2-dimensional array. Therefore, implementations vary. Here are some MIPS examples to suggest 2-dimensional array implementations.
Declarations
Without a formalized syntax, a declaration of a 2-dimensional array reduces to the allocation of the correct amount of contiguous memory. The base address identifies the first element of the first row within the first column.
Consider the declaration of an example 2 by 3 array of characters. Each character requires one byte.
chars: .space 6 # 2 by 3 = 6 bytes of allocated spaceThis is not a satisifying declaration for the abstract thinker, as this declaration might represent a 3 by 2 array, or a 1-dimensional array of 6 characters. The burden is on the programmer to declare the necessary memory space, and then use that space in a consistent manner.
An alternative in MIPS assembly language code allocates a set of arrays. For example, consider a 4 by 6 array of integers, where each element is initialized to the value 18.
arr: .word 18:6 .word 18:6 .word 18:6 .word 18:6This declaration conveys the notion of an array of arrays.
Code
Issues with code that operates on a 2-dimensional array are the same as those with 1-dimensional arrays, with the added point of storage order. A 2-dimensional array may be stored in either row major order or column major order.
If 2-dimensional array is thought of as an array of 1-dimensional arrays, then operating on one row of a row major ordered array is fairly simple. Likewise, operating on one column of a column major ordered array is fairly simple.
附上两个非常有帮助的网站: