一.介绍
1.什么是redis
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
2.为什么用redis
1)异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
2)支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。
3)操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
4)MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
3.redis有什么缺点如何解决
1)缓存和数据库双写一致性问题
数据库和缓存双写必然会存在不一致的问题,如果对数据有强一致性要求,不能放缓存。
我们所做的只能保证最终一致性,可以采取正确的更新策略,先更新数据库再删缓存,其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
2)缓存雪崩问题
缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(1)给缓存的失效时间,加上一个随机值,避免集体失效。
(2)使用互斥锁,但是该方案吞吐量明显下降了。
(3)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
-
I 从缓存A读数据库,有则直接返回
-
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
-
III 更新线程同时更新缓存A和缓存B。
3)缓存击穿问题
即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(1)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(2)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。
需要做缓存预热(项目启动前,先加载缓存)操作。
(3)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。
迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
4)缓存的并发竞争问题
同时有多个子系统去set一个key
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
二.使用
1.连接redis(两种方式)
import redis r = redis.Redis(host='localhost', port=6379) r.set('foo', 'Bar') print r.get('foo') ################### #连接池 import redis pool = redis.ConnectionPool(host='localhost', port=6379) r = redis.Redis(connection_pool=pool) r.set('foo', 'Bar') print r.get('foo')
2.字符串类型 Stirng
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
mset(*args, **kwargs)
批量设置值 如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})
3.列表类型 list
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
lpush(name,values)# 在name对应的list中添加元素,每个新的元素都添加 #到列表的最左边 rpush(name, values) # 表示从右向左操作 lpushx(name,value) #在name对应的list中添加元素,只有name已经存 #在时,值添加到列表的最左边 rpushx(name, value) # 表示从右向左操作 llen(name) # name对应的list元素的个数 linsert(name, where, refvalue, value)) # 在name对应的列表的某一个值 #前或后插入一个新值 r.lset(name, index, value) # 对name对应的list中的某一个索引位置重新 #赋值 r.lrem(name, value, num) # 在name对应的list中删除指定的值 lpop(name) # 在name对应的列表的左侧获取第一个元素并在列表中移除, #返回值则是第一个元素 lindex(name, index) #在name对应的列表中根据索引获取列表元素
4.哈希类型 hash
Hash操作,redis中Hash在内存中的存储格式如下图:
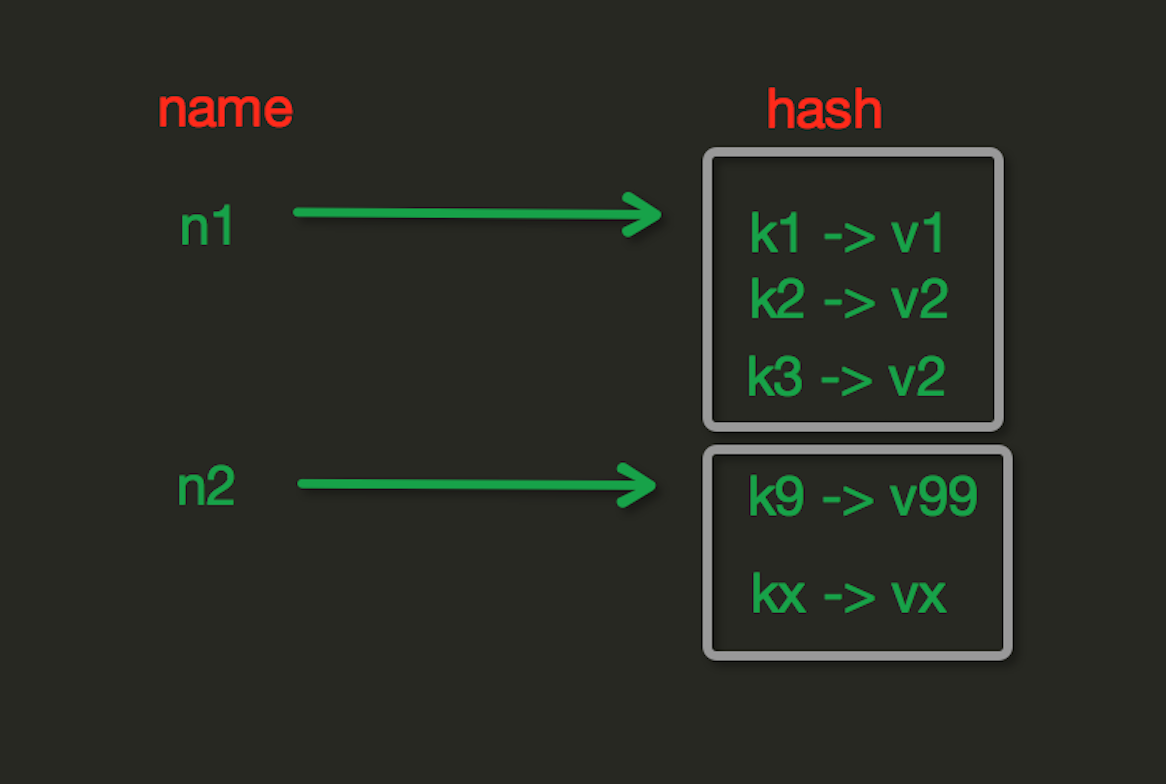
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
5.集合类型 set
Set集合就是不允许重复的列表
sadd(name,values) #name对应的集合中添加元素 scard(name) #获取name对应的集合中元素个数 sdiff(keys, *args) #在第一个name对应的集合中且不在其他name对应的集 #合的元素集合 sdiffstore(dest, keys, *args) # 获取第一个name对应的集合中且不在其他 #name对应的集合,再将其新加入到dest对应的集合中 sinter(keys, *args) #获取多一个name对应集合的并集 sinterstore(dest, keys, *args) # 获取多一个name对应集合的并集,再讲 #其加入到dest对应的集合中 sismember(name, value) #检查value是否是name对应的集合的成员 smembers(name) #获取name对应的集合的所有成员 smove(src, dst, value)# 将某个成员从一个集合中移动到另外一个集合 spop(name)# 从集合的右侧(尾部)移除一个成员,并将其返回 srandmember(name, numbers)# 从name对应的集合中随机获number个 元素 srem(name, values)# 在name对应的集合中删除某些值 sunion(keys, *args)# 获取多一个name对应的集合的并集 sunionstore(dest,keys, *args)# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中 sscan(name, cursor=0, match=None, count=None) sscan_iter(name, match=None, count=None)# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
6.有序集合
在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs) # 在name对应的有序集合中添加元素 zcard(name)# 获取name对应的有序集合元素的数量 zcount(name, min, max)# 获取name对应的有序集合中分数 [min,max之 间的个数 zincrby(name, value, amount)# 自增name对应的有序集合的 name 对应 的分数 r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float) # 按照索引范围获取name对应的有序集合的元素 # 参数: # name,redis的name # start,有序集合索引起始位置(非分数) # end,有序集合索引结束位置(非分数) # desc,排序规则,默认按照分数从小到大排序 # withscores,是否获取元素的分数,默认只获取元素的值 # score_cast_func,对分数进行数据转换的函数 # 更多: # 从大到小排序 # zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) # 从大到小排序 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
6.管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) pipe.multi() pipe.set('name', 'anne') pipe.set('role', 'rose') pipe.execute()


#!/usr/bin/env python # -*- coding:utf-8 -*- import redis conn = redis.Redis(host='192.168.1.41',port=6379) conn.set('count',1000) with conn.pipeline() as pipe: # 先监视,自己的值没有被修改过 conn.watch('count') # 事务开始 pipe.multi() old_count = conn.get('count') count = int(old_count) if count > 0: # 有库存 pipe.set('count', count - 1) # 执行,把所有命令一次性推送过去 pipe.execute()
7.发布订阅
订阅者:
#!/usr/bin/env python # -*- coding:utf-8 -*- from monitor.RedisHelper import RedisHelper obj = RedisHelper() redis_sub = obj.subscribe() while True: msg= redis_sub.parse_response() print msg
发布者:
#!/usr/bin/env python # -*- coding:utf-8 -*- from monitor.RedisHelper import RedisHelper obj = RedisHelper() obj.public('hello')