Buffer的定义:
概念上,缓冲区是包在一个对象内的基本数据元素数组。Buffer类相比一个简单数组的优点是它将关于数据的数据内容和信息包含在一个单一的对象中。Buffer类以及它专有的子类定义了一个用于处理数据缓冲区的API。
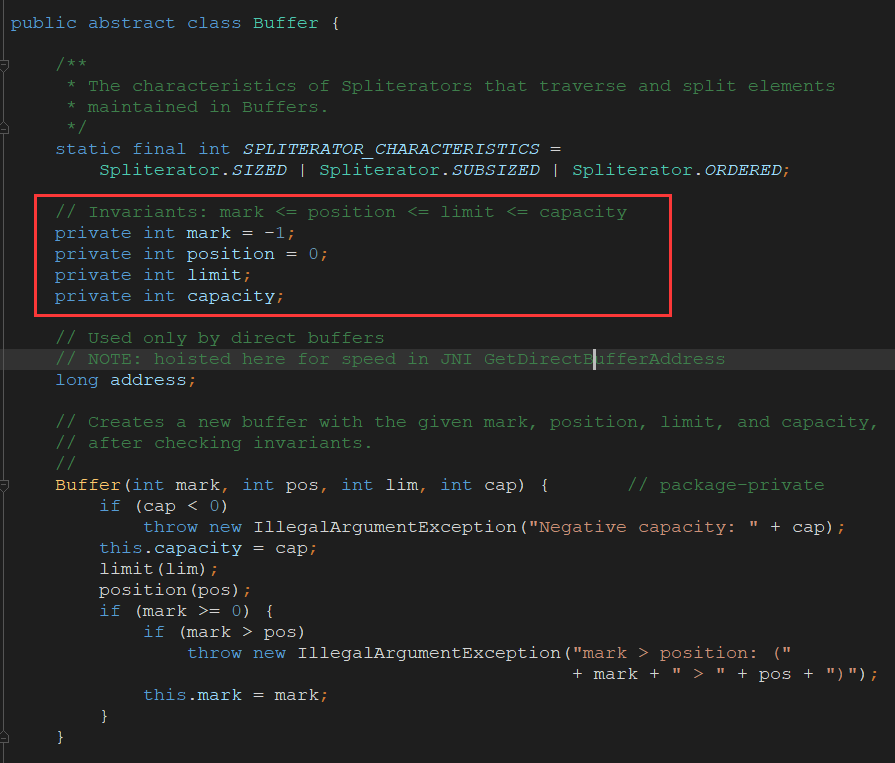
Buffer类的有以下的几个最关键的属性
容量(Capacity) 缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变。
上界(Limit) 缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
位置(Position) 下一个要被读或写的元素的索引。位置会自动由相应的get( )和put( )函数更新。
标记(Mark) 一个备忘位置。调用mark( )来设定mark = postion。调用reset( )设定position = mark。标记在设定前是未定义的(undefined)。
这四个属性之间总是遵循以下关系: mark <= position <= limit <= capacity
以下是Buffer类的源代码:
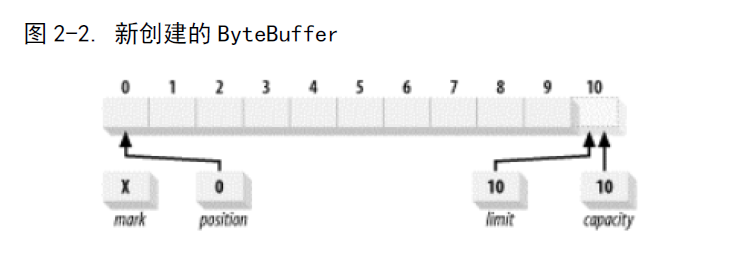
新创建的缓冲区: 此时,mark和position都为0 ,limit和capacity都为缓冲区的长度,我们可以往缓冲区里边写入数据
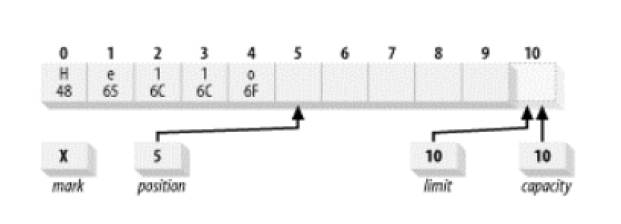
将缓冲区内写入一些数据:此时,只有position的位置变了,它指向我们下一个可写的元素位置
既然我们已经在buffer中存放了一些数据,如果我们想在不丢失位置的情况下进行一些更改该怎么办呢?put()的绝对方案可以达到这样的目的。假设我们想将缓冲区中的内容从“Hello”的ASCII码更改为“Mellow”。我们可以这样实现:
buffer.put(0,(byte)'M').put((byte)'w');
这里通过进行一次绝对方案的put将0位置的字节代替为十六进制数值0x4d,将0x77放入当前位置(当前位置不会受到绝对put()的影响)的字节,并将位置属性加一。结果下所示:
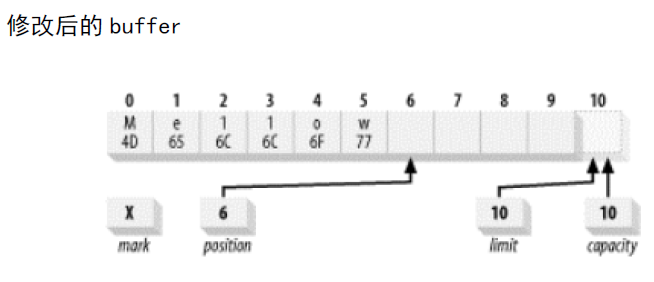
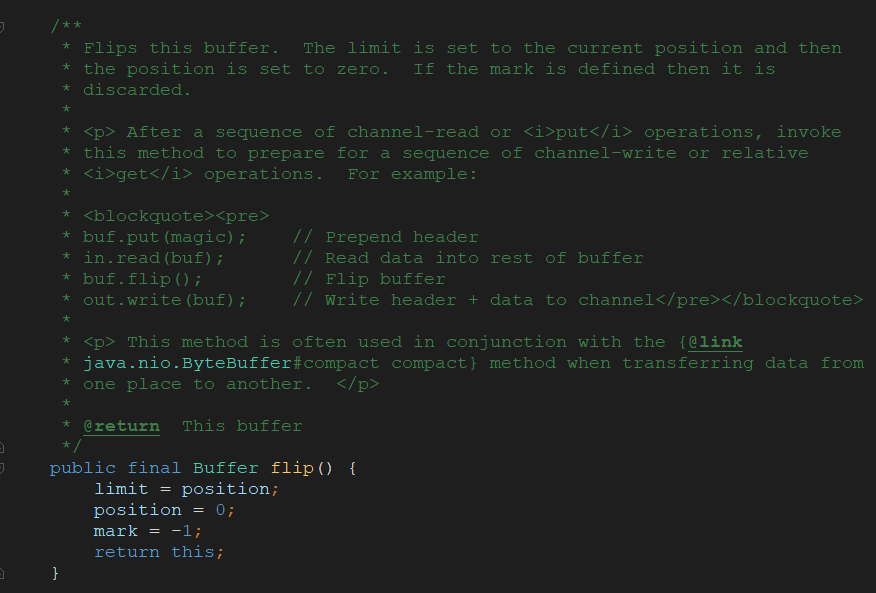
将缓冲区翻转:
缓冲区的读取和写入都是从postion开始的,直到limit结束.当我们把缓冲区写了一些数据之后,想读取这些数据,我们可以调整limit和position的位置,让limit指向原先的position,让position指向0 ,这样就可以读到原先写书的数据了,JDK为我们提供了一个简单的方法:
buffer.flip();
翻转之后的缓冲区:
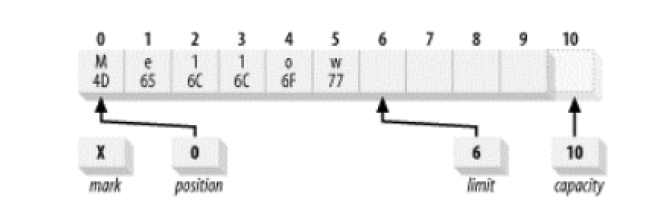
flip()方法的内部也是通过改写limit和position的位置来实现的: