OpenPower服务器性能监控操作流程
1. 前言
最近看了很多prometheus以及influxdb进行性能监控的帖子,简单学习了下influxdb是一个单纯的时序数据库,prometheus是一个比较全面的性能监控平台. 前几天使用 influxdb还有esxi的部分配置进行了vcenter的性能监控,但是公司这边凭条技术部是prometheus为主进行性能监控的, 所以今天趁着早上没有人, 我就进行了一下OpenPower机器上面的性能监控的设置, 发现还是比较简单的, 为了备忘, 简单记录一下搭建流程.
2. 搭建思路
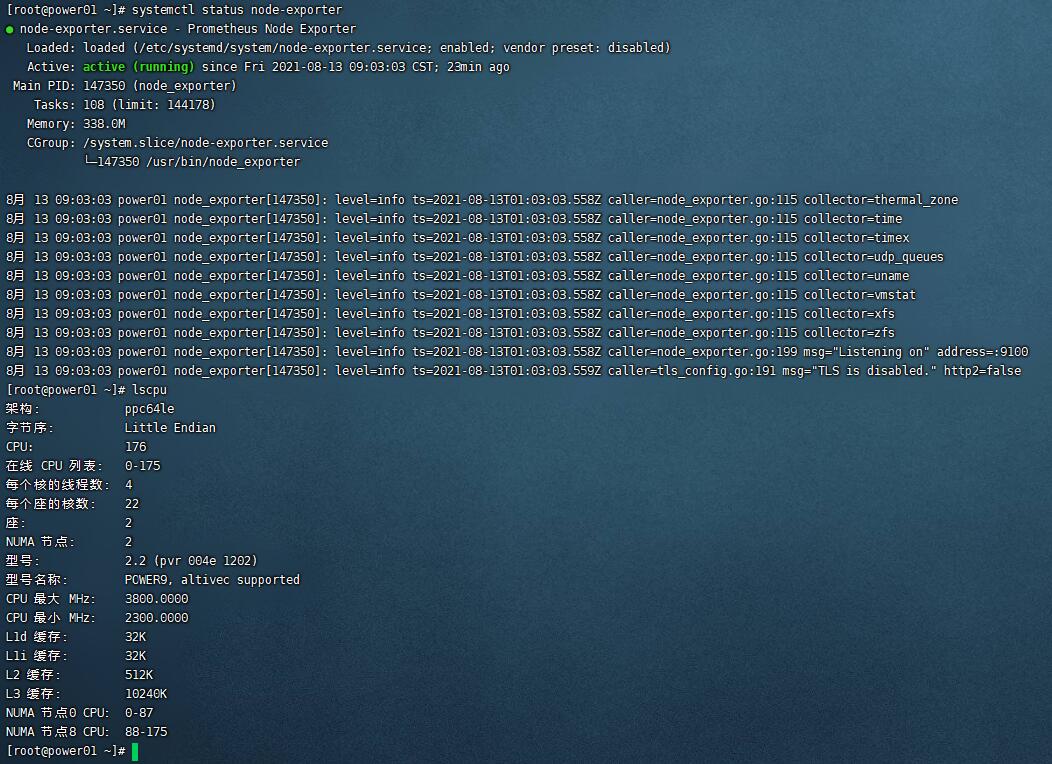
- node-exporter 使用二进制本地运行
下载相关二进制,二进制的方式避免不同平台拉取镜像比较麻烦
最新的下载地址为:
https://github.com/prometheus/node_exporter/releases/tag/v1.2.2
注意可以选择想对应的平台进行下载 我这边下载的是 ppc64le 的linux的tar包.
下载后 将文件解压缩并且放到 /usr/bin 目录下备用
两种方式可以设置开机启动, 一种是crontab 方式 一种是systemd的方式. 我这边为了简单起见使用systemd
创建一个文件为:
vim /etc/systemd/system/node-exporter.service
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/usr/bin/node_exporter
User=root
[Install]
WantedBy=multi-user.target
然后 systemctl enable node-exporter && systemctl restart node-exporter
即可
- prometheus和grafana 使用docker方式运行.
- 需要注意的是这个地方尽量拉取最新的镜像, 避免出现很多chart 组件展示不出来的情况.
prometheus 的搭建
1. 拉取镜像:
sudo docker pull prom/prometheus
sudo docker pull grafana/grafana
# 我2021.8 拉取到的grafana的镜像版本是 8.1 左右, 已经比较新了.
2. 创建prometheus的配置文件目录
mkdir /prometheus && cd /prometheus
vim prometheus.yml
# 添加内容为
# Prometheus全局配置项
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中
monitor: 'codelab_monitor'
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "alertmanager_rules.yml"
- "prometheus_rules.yml"
# scape配置
scrape_configs:
- job_name: 'OpenPowerAPP244' # job_name默认写入timeseries的labels中,可以用于查询使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['10.24.xx.xx:9100'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'OpenPowerDB243' # job_name默认写入timeseries的labels中,可以用于查使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['10.24.xx.xx:9100'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'example-random' #个人测试用接口
static_configs:
- targets: ['localhost:8080']
# 有文档还会处理两个文件主要如下:
vim alertmanager_rules.yml
groups:
- name: test-rules
rules:
- alert: InstanceDown # 告警名称
expr: up == 0 # 告警的判定条件,参考Prometheus高级查询来设定
for: 2m # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
team: node
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
value: {{$value}}
以及
vim prometheus_rules.yml
groups:
- name: example #报警规则的名字
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown #检测job的状态,持续1分钟metrices不能访问会发给altermanager进行报警
expr: up == 0
for: 1m #持续时间
labels:
serverity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: "it's has problem" #报警的名字
expr: "test_tomcat{exported_instance="uat",exported_job="uat-app-status",host="test",instance="uat",job="uat-apps-status"} - test_tomcat{exported_instance="uat",exported_job="uat-app-status",host="test",instance="uat",job="uat-apps-status"} offset 1w > 5" # 这个意思是监控该表达式查询出来的值与一周前的值进行比较,大于5且持续10m钟就发送给altermanager进行报警
for: 1m #持续时间
labels:
serverity: warning
annotations:
summary: "{{ $labels.type }}趋势增高"
description: "机器:{{ $labels.host }} tomcat_id:{{ $labels.id }} 类型:{{ $labels.type }} 与一周前的差值大于5,当前的差值为:{{ $value }}" #自定义的报警内容
运行容器:
sudo docker run -d -p 9091:9090 --name prometheus -v /prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
# 注意 我机器上面 9100 被其他进程占用了 所以我换了一个端口.
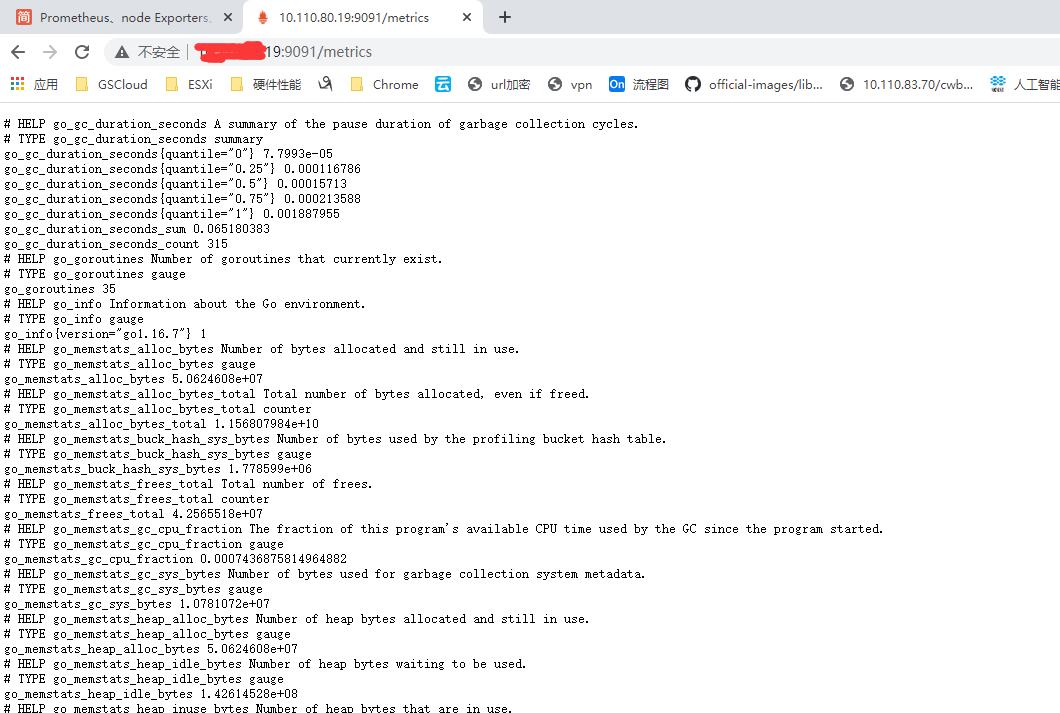
然后使用域名 http://yourip:9091/metrics
能够看到如下内容就说明可以监控到数据了.
# 注意 我的node_exporter已经创建好的情况下才有.
- grafana 也是使用容器化搭建方式也比较简单
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
# 注意一定要持久化, 不然机器重启或者是容器重启就没有了. 注意启动之后需要设置密码 不要用默认密码 admin/admin
容易出现安全问题.
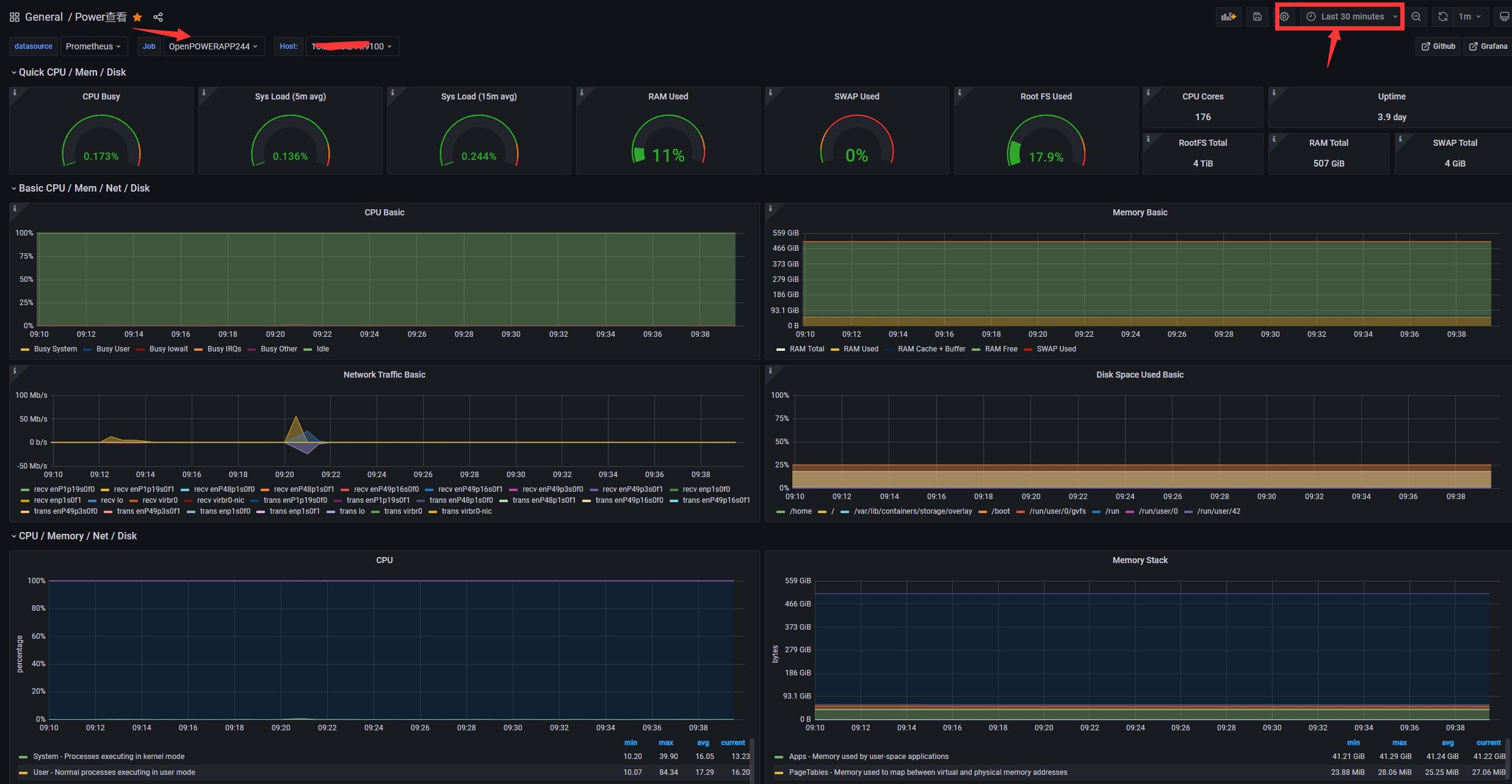
3. grafana 展示结果
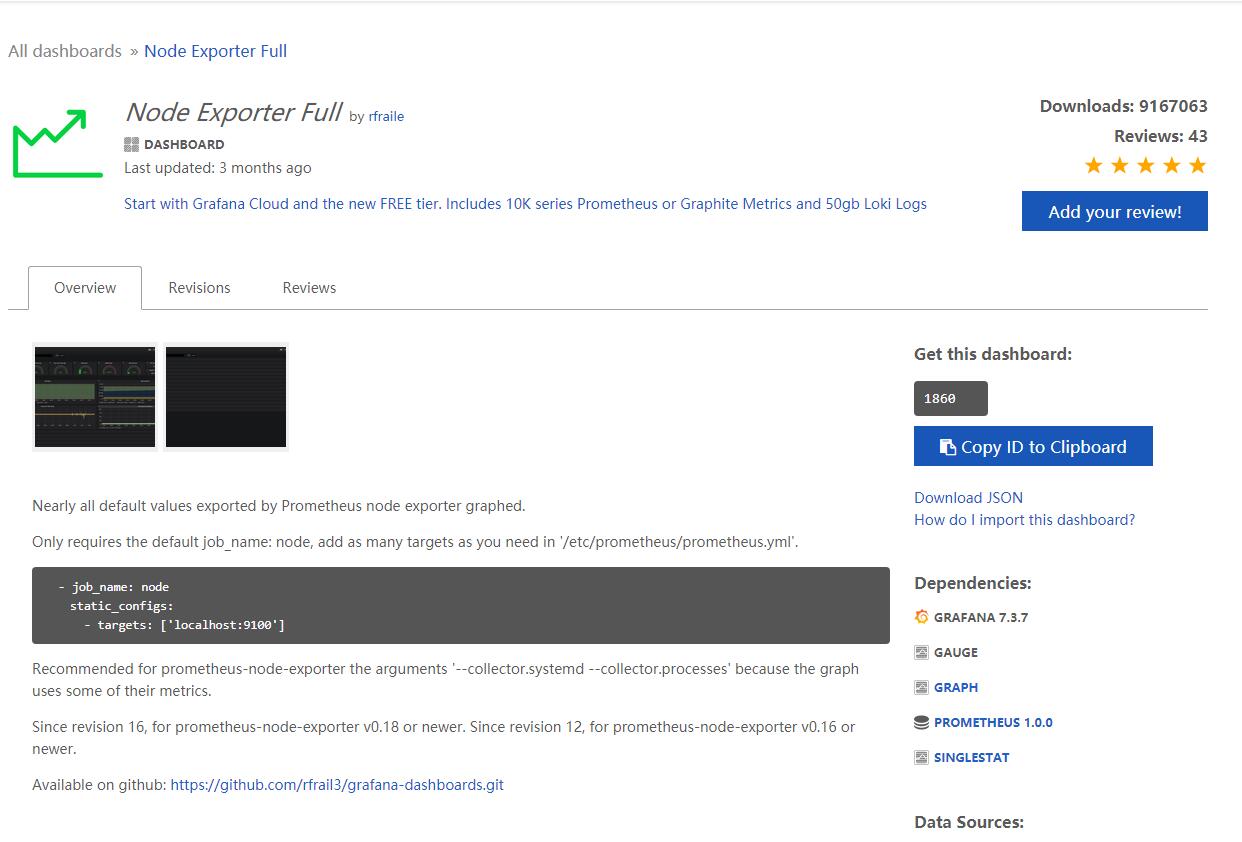
- 3.1 先去官网下载响应的json文件.
- 公司连grafana的官网都不让上.还得用流量赖上,电话费报销还这么低. diss一下.
- 选择如下这一个就可以
下载路径为:
https://grafana.com/grafana/dashboards?dataSource=influxdb&direction=desc&orderBy=downloads&search=vmware&collector=Telegraf
-
下载好json
-
打开grafana
-
3.2 添加数据源
方式比较简单 见图即可 -
3.2.1 打开数据源管理
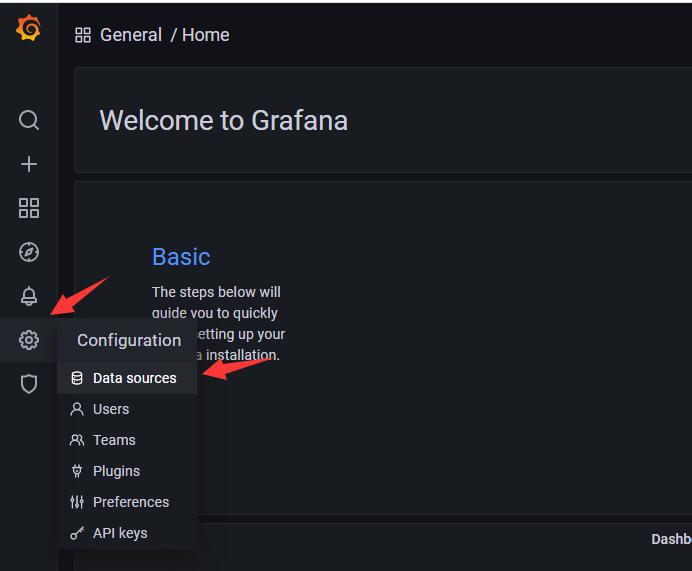
-
3.2.2 添加数据源
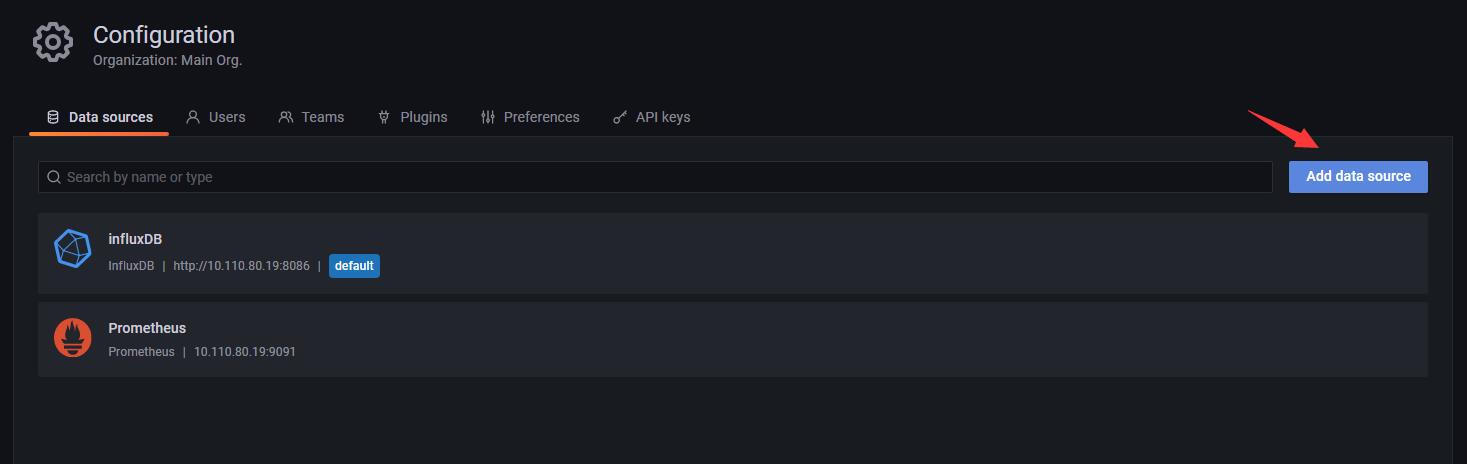
-
3.2.3 选择prometheus
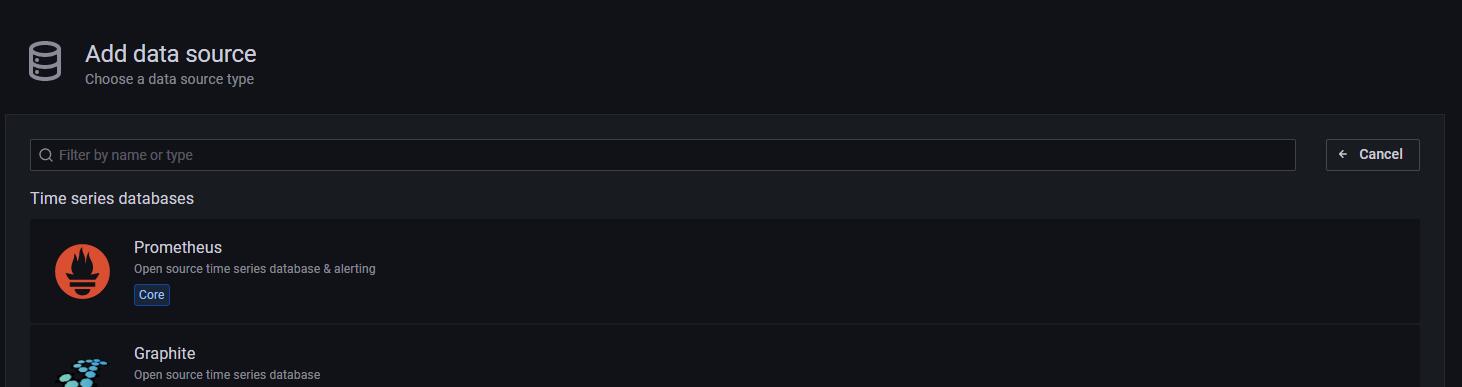
-
3.2.4 输入自己的服务器的信息, 注意端口号需要跟自己运行的端口号匹配起来
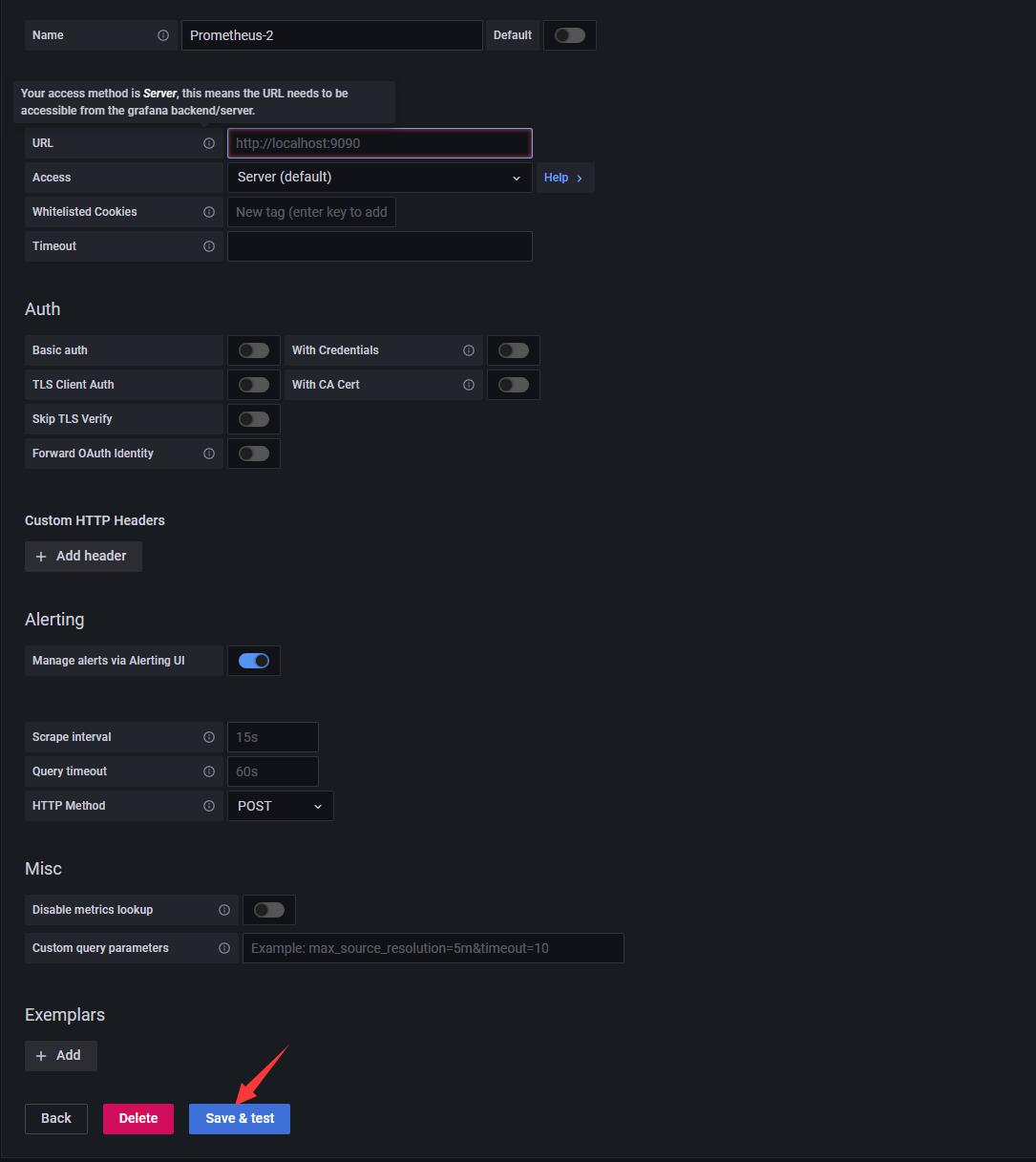
-
3.2.5 save and test 提示成功可以运行即可.
-
3.3.1 导入josn文件, 非常简单,如图示即可
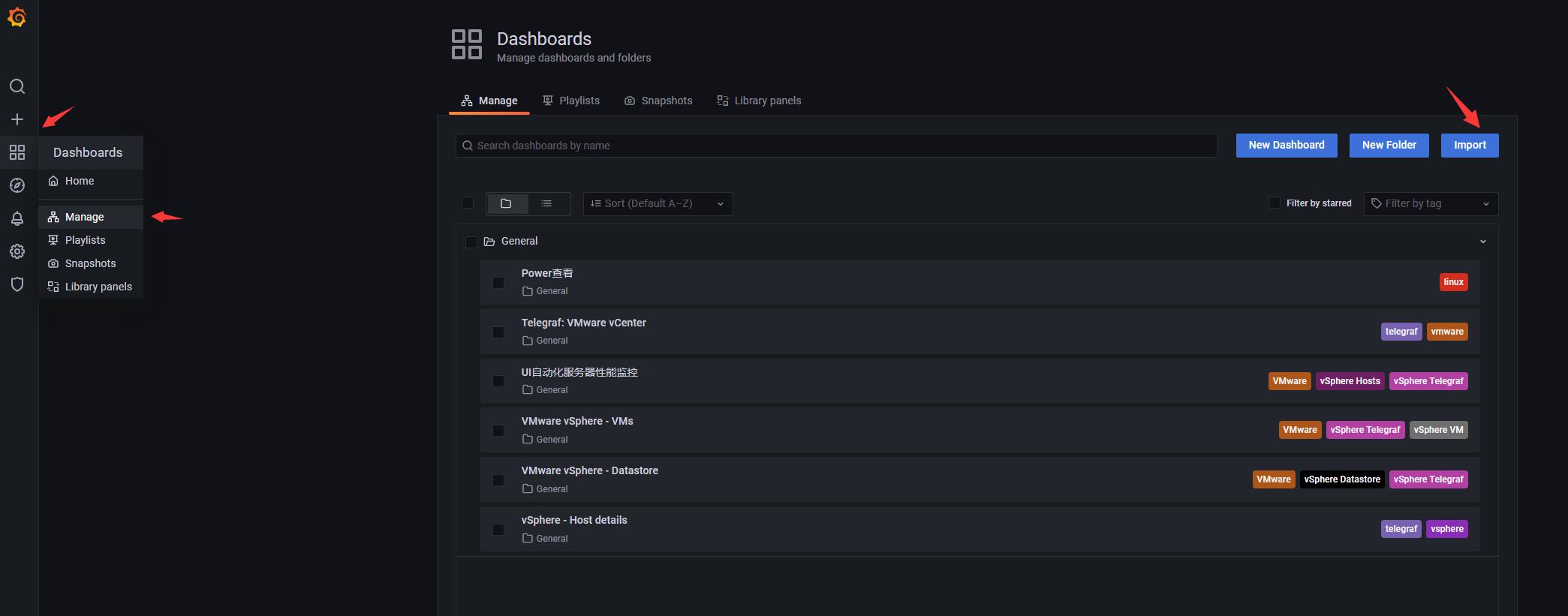
-
3.4 查看展示结果
注意 需要等一段时间来收集数据
注意 可以缩短时间来进行查看内容