激活函数 ReLU、LReLU、PReLU、CReLU、ELU、SELU 的定义和区别
ReLU

tensorflow中:tf.nn.relu(features, name=None)
LReLU
(Leaky-ReLU)
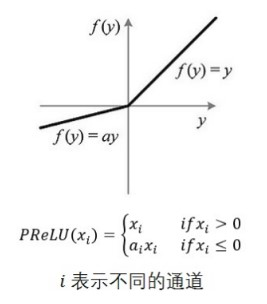
其中ai是固定的。i表示不同的通道对应不同的ai.
tensorflow中:tf.nn.leaky_relu(features, alpha=0.2, name=None)
PReLU
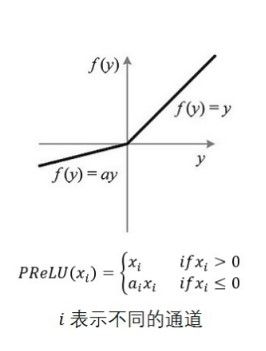
其中ai是可以学习的的。如果ai=0,那么 PReLU 退化为ReLU;如果 aiai是一个很小的固定值(如ai=0.01),则 PReLU 退化为 Leaky ReLU(LReLU)。
PReLU 只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同 channels 使用相同的ai时,参数就更少了。BP 更新ai时,采用的是带动量的更新方式(momentum)。
tensorflow中:没找到啊!
CReLU
(Concatenated Rectified Linear Units)
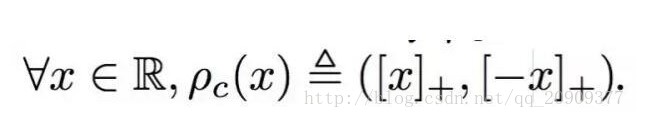
tensorflow中:tf.nn.crelu(features, name=None)
ELU
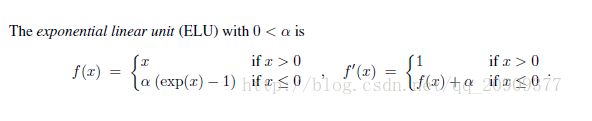
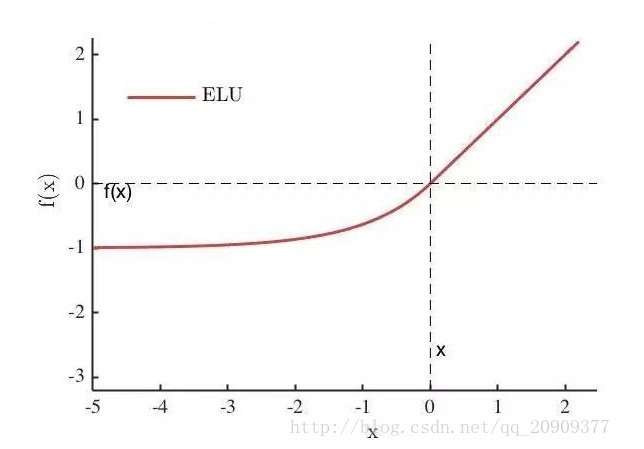
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快
tensorflow中:tf.nn.elu(features, name=None)
SELU

经过该激活函数后使得样本分布自动归一化到0均值和单位方差(自归一化,保证训练过程中梯度不会爆炸或消失,效果比Batch Normalization 要好)
其实就是ELU乘了个lambda,关键在于这个lambda是大于1的。以前relu,prelu,elu这些激活函数,都是在负半轴坡度平缓,这样在activation的方差过大的时候可以让它减小,防止了梯度爆炸,但是正半轴坡度简单的设成了1。而selu的正半轴大于1,在方差过小的的时候可以让它增大,同时防止了梯度消失。这样激活函数就有一个不动点,网络深了以后每一层的输出都是均值为0方差为1。
tensorflow中:tf.nn.selu(features, name=None)

PS:
Activation Function Cheetsheet
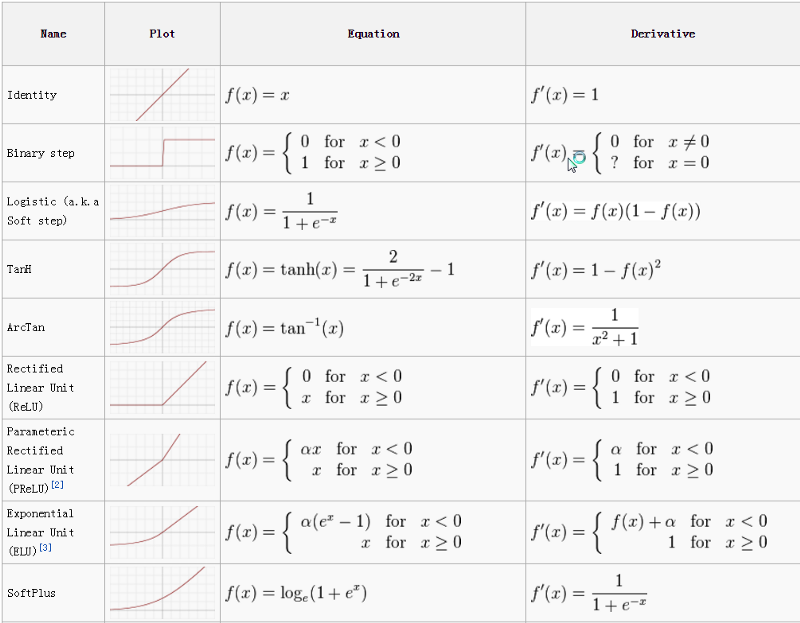
来源: