atomic
原子(atomic)本意是"不能被进一步分割的最小粒子",而原子操作(atomic operation)意为"不可被中断的一个或一系列操作"。在多处理器上实现原子操作就变得有点复杂。让我们一起来聊一聊在Intel处理器和Java里是如何实现原子操作的。
1.术语定义
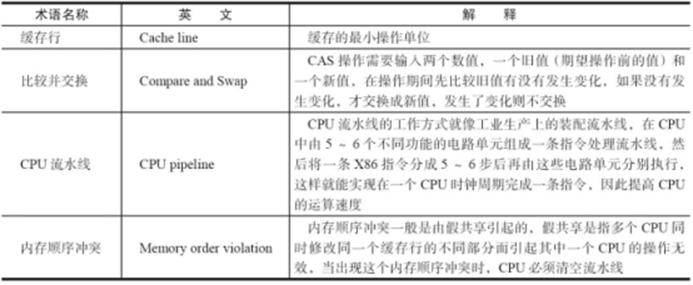
在了解原子操作的实现原理前,先要了解一下相关的术语,如表2-7所示。
表2-7 CPU术语定义
2.处理器如何实现原子操作
32位IA-32处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium 6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器是不能自动保证其原子性的,比如跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
1)使用总线锁保证原子性
第一个机制是通过总线锁保证原子性。如果多个处理器同时对共享变量进行读改写操作(i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行两次i++操作,我们期望的结果是3,但是有可能结果是2,如图2-3所示。
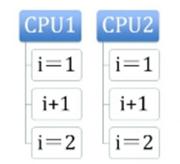
图2-3 结果对比
原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
(2)使用缓存锁保证原子性
3.Java如何实现原子操作
在Java中可以通过锁和循环CAS的方式来实现原子操作。(1)使用循环CAS实现原子操作
JVM中的CAS操作正是利用了处理器提供的CMPXCHG指令实现的。自旋CAS实现的基本思路就是循环进行CAS操作直到成功为止,以下代码实现了一个基于CAS线程安全的计数器方法safeCount和一个非线程安全的计数器count。
缺点
1)ABA问题,1 2 1 以为没有变化
2)循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
3)只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
CAS的实现Atomic类库
这个包里面提供了一组原子变量类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。可以对基本数据、数组中的基本数据、对类中的基本数据进行操作。原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。
java.util.concurrent.atomic中的类可以分成4组:
标量类(Scalar):AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
数组类:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
更新器类:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
复合变量类:AtomicMarkableReference,AtomicStampedReference
标量类
第一组AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference这四种基本类型用来处理布尔,整数,长整数,对象四种数据,其内部实现不是简单的使用synchronized,而是一个更为高效的方式CAS (compare and swap) + volatile和native方法,从而避免了synchronized的高开销,执行效率大为提升。
他们的实现都是依靠 真正的值为volatile 类型,通过Unsafe 包中的原子操作实现。最基础就是CAS,他是一切的基础。如下 。其中offset是 在内存中 value相对于基地址的偏移量。(它的获得也由Unsafe 本地代码获得)。关于加锁的原理见附录。
核心代码如下,其他都是在compareAndSet基础上构建的。
1. private static final Unsafe unsafe = Unsafe.getUnsafe();
2. private volatile int value;
3. public final int get() {
4. return value;
5. }
6. public final void set(int newValue) {
7. value = newValue;
8. }
9. public final boolean compareAndSet(int expect, int update) {
10. return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
11.}
void set()和void lazySet():set设置为给定值,直接修改原始值;lazySet延时设置变量值,这个等价于set()方法,但是由于字段是volatile类型的,因此次字段的修改会比普通字段(非volatile字段)有稍微的性能延时(尽管可以忽略),所以如果不是想立即读取设置的新值,允许在"后台"修改值,那么此方法就很有用。
getAndSet( )方法,利用compareAndSet循环自旋实现。
原子的将变量设定为新数据,同时返回先前的旧数据。
其本质是get( )操作,然后做set( )操作。尽管这2个操作都是atomic,但是他们合并在一起的时候,就不是atomic。在Java的源程序的级别上,如果不依赖synchronized的机制来完成这个工作,是不可能的。只有依靠native方法才可以。
Java代码
1. public final int getAndSet(int newValue) {
2. for (;;) {
3. int current = get();
4. if (compareAndSet(current, newValue))
5. return current;
6. }
7. }
对于 AtomicInteger、AtomicLong还提供了一些特别的方法。贴别是如,
getAndAdd( ):以原子方式将给定值与当前值相加, 相当于线程安全的t=i;i+=delta;return t;操作。
以实现一些加法,减法原子操作。(注意 --i、++i不是原子操作,其中包含有3个操作步骤:第一步,读取i;第二步,加1或减1;第三步:写回内存)
数组类
第二组AtomicIntegerArray,AtomicLongArray还有AtomicReferenceArray类进一步扩展了原子操作,对这些类型的数组提供了支持。这些类在为其数组元素提供 volatile 访问语义方面也引人注目,这对于普通数组来说是不受支持的。
他们内部并不是像AtomicInteger一样维持一个valatile变量,而是全部由native方法实现,如下
AtomicIntegerArray的实现片断:
Java代码
1. private static final Unsafe unsafe = Unsafe.getUnsafe();
2. private static final int base = unsafe.arrayBaseOffset(int[].class); //数组基地址
3. private static final int scale = unsafe.arrayIndexScale(int[].class); //数组元素占的大小精度
4. private final int[] array;
5. public final int get(int i) {
6. return unsafe.getIntVolatile(array, rawIndex(i));
7. }
8. public final void set(int i, int newValue) {
9. unsafe.putIntVolatile(array, rawIndex(i), newValue);
10. }
11.
12. private longrawIndex(int i) {//获取具体某个元素的偏移量
13. if (i <0 || i >= array.length)
14. thrownew IndexOutOfBoundsException("index " + i);
15. return base+ (long) i * scale;
16. }
更新器类
第三组AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater基于反射的实用工具,可以对指定类的指定 volatile 字段进行原子更新。API非常简单,但是也是有一些约束:
(1)字段必须是volatile类型的
(2)字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。也就是说 调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
(3)只能是实例变量,不能是类变量,也就是说不能加static关键字。
(4)只能是可修改变量,不能使final变量,因为final的语义就是不可修改。实际上final的语义和volatile是有冲突的,这两个关键字不能同时存在。
(5)对于AtomicIntegerFieldUpdater 和AtomicLongFieldUpdater 只能修改int/long类型的字段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用AtomicReferenceFieldUpdater 。
复合变量类
防止ABA问题出现而构造的类。如什么是ABA问题呢,当某些流程在处理过程中是顺向的,也就是不允许重复处理的情况下,在某些情况下导致一个数据由A变成B,再中间可能经过0-N个环节后变成了A,此时A不允许再变成B了,因为此时的状态已经发生了改变,他们都是对atomicReference的进一步包装,AtomicMarkableReference和AtomicStampedReference功能差不多,有点区别的是:它描述更加简单的是与否的关系,通常ABA问题只有两种状态,而AtomicStampedReference是多种状态,那么为什么还要有AtomicMarkableReference呢,因为它在处理是与否上面更加具有可读性。