DOM中基础选择器的整理
注意:DOM中选择器返回是数组类型的都是伪数组,只能拥有数组的索引以及length,数组的其他方法是不可以使用的!
一:DOM中的选择器
1.getElementById(id) //获取指定元素的ID元素 2.getElementsByTagName() //获取相同元素的节点列表,通过标签名选择元素,返回值是一个数组 3.getElementsByName() //通过name值获取元素,返回值是数组,通常用来获取有name的input的值 4.getElementsByClassName() //通过class名获取元素,返回值(HTML集合)是数组n
tip:这是四个基础的选择器,后面在其基础上在拓展
二:ES5选择器:就两个,但功能强大(都是对象的方法)
注意:兼容性自行测试
1:document.querySelector(); //可以获取所有类型的选择器,但是只能获取一个,返回的值是单个元素
拓展:querySelector返回dom的子元素中第一个符合selectors选择器字符串的元素,无匹配项则返回null,在获取时, 可以直接在括号内使用css选择器的样式,比如:obox = document.querySelector("#box>h2");
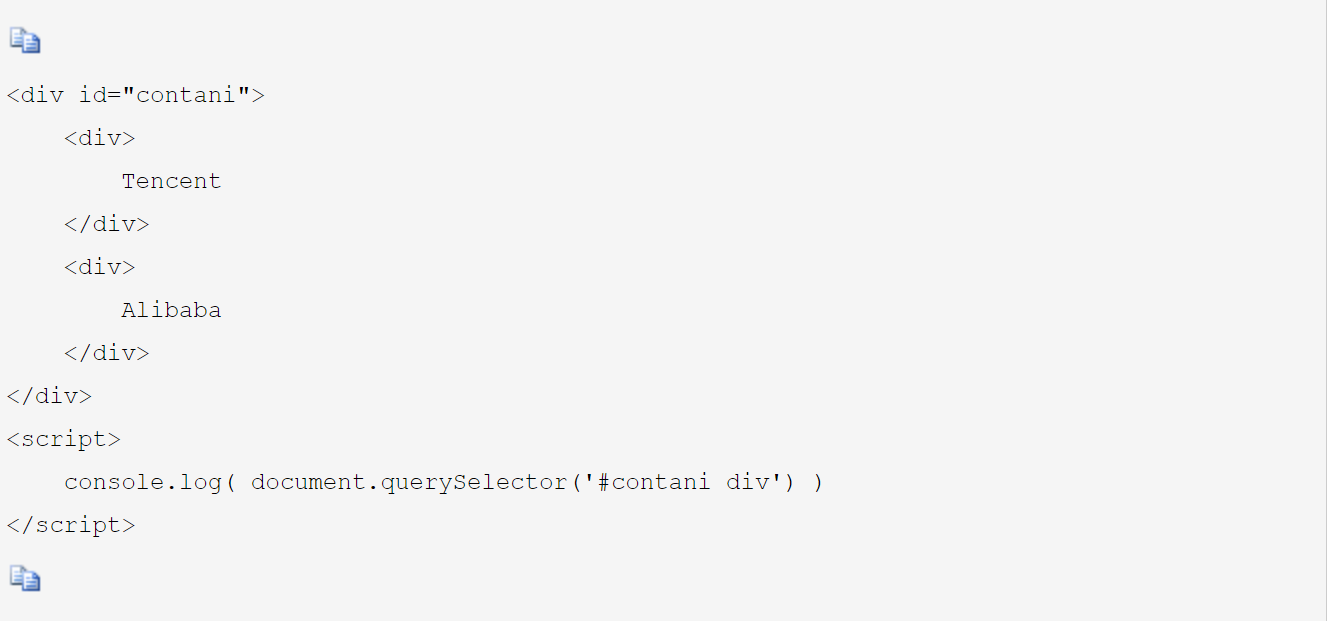

2:document.quertSelectorAll(); //可以获取所有类型的选择器,返回的是伪数组
拓展:和上面一样,不同的是它返回的是匹配的所有元素列表,是一个nodeList集合,而且是non-live的(理解为不会实时更新)
这个获取是比较重要的,需要深入理解一下。
console.log( document.querySelectorAll('#contani div') )
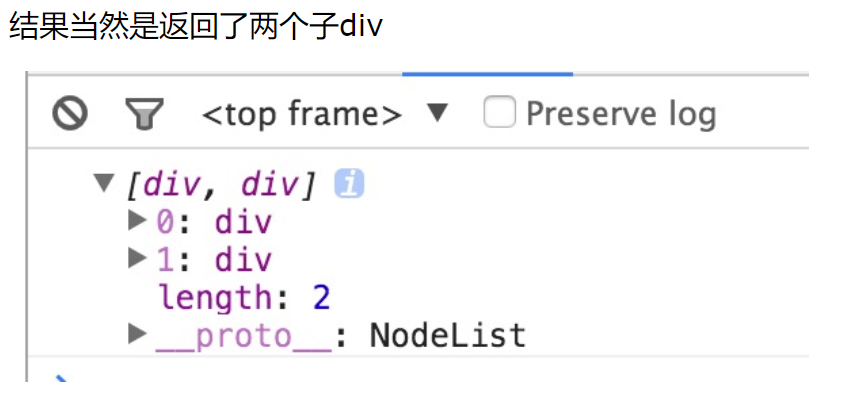
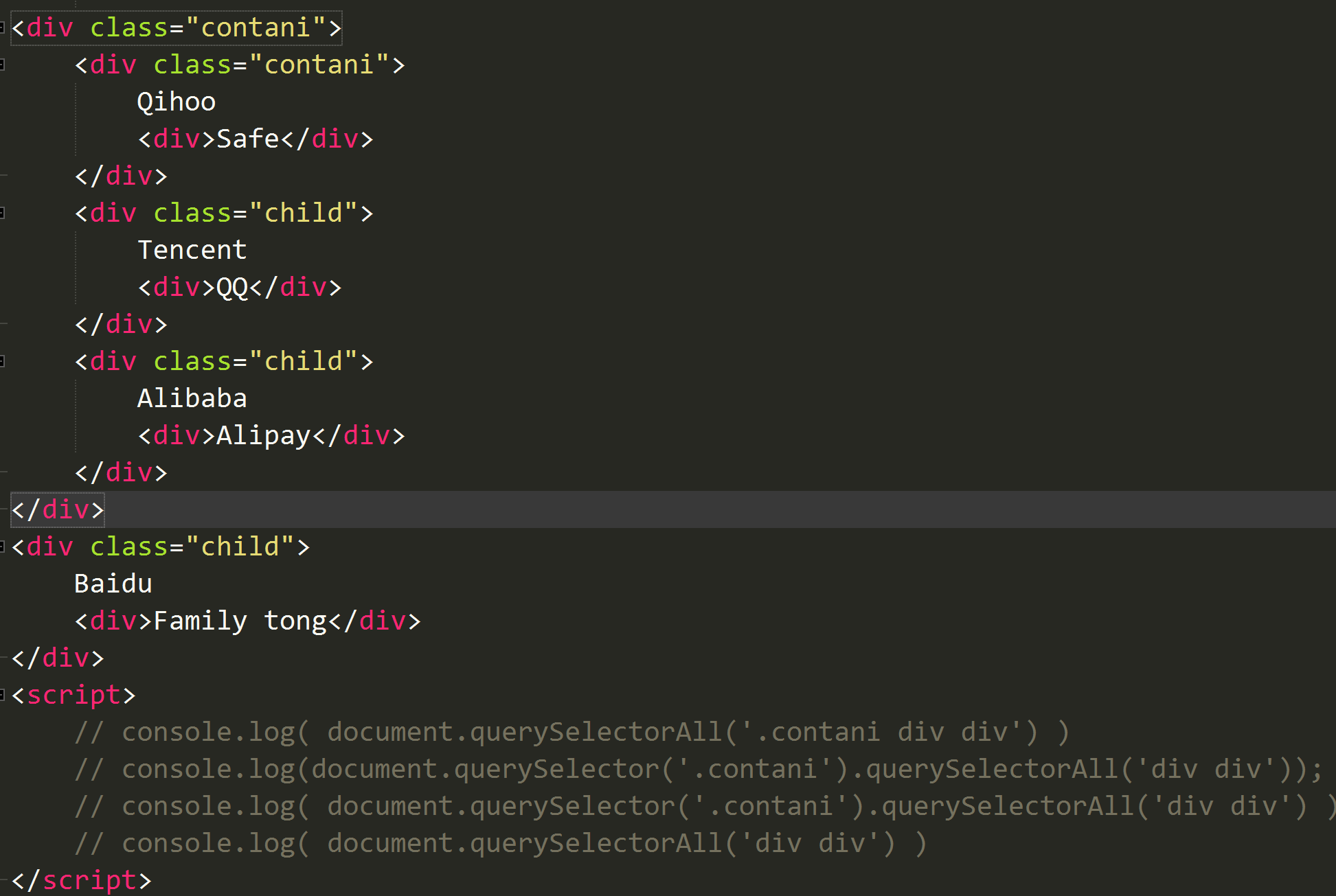
用querySelectorAll去获取后代的后代选择器,返回时多少,类似于('div div div')
注意:关于querySelectorAll另外要注意的一点是:当且仅当querySelectorAll的选择器字符串是‘div div’时(如:dom.querySelectorAll(‘div div’)),它匹配的元素包括了dom,也就是说如果该dom元素和它的子元素构成了div div这种父子结构时,该dom也会被匹配到。
eg:dom.querySelectorAll(div div div); dom.querySelector(contani).querySelectorAll(div div); //当构成了div div父子结构,前者的div认为是匹配到了dom元素,此时的dom.querySelector(contani).querySelectorAll(div div); 等同于dom.querySelector(contani).querySelectorAll(div);都是选择contani的后代div元素
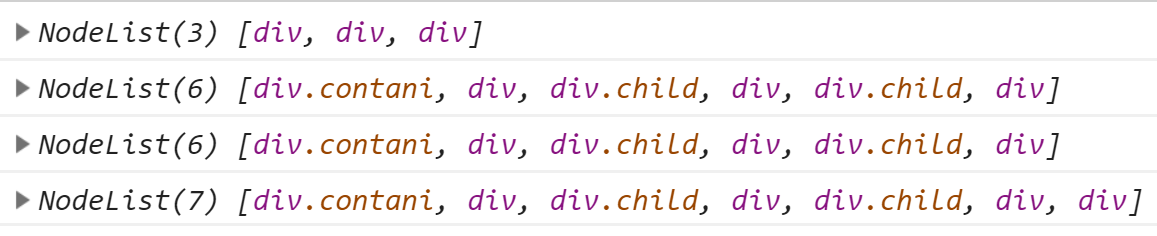
补充:non-live(不是实时更新),关于getElementsTagName();与dom.querySelectorAll();
在获取基础选择中选择器,有个getElementsTagName();获取标签(元素)选择器,这个标签选择器获得节点集合(列表)是实时更新得到,
dom.querySelectorAll();不是实时更新的;下面测试一下,当插入了一个新的节点后,获取到的原选择器否会更新;


从上面的测试中可以看出,当追加了新的节点的时候,querySelector();获取的节点集合并没有刷新,而getElementsTagName();获取的html集合是刷新的
有人会问,明明用的是className()测试的,跟tagName()有什么关系呢?因为如果直接用tagName是没有办法直接获取到box里面的div的,这时候委婉的用className来测试一下,可以得出同样的效果,读者也可以自行测试一下。
补充两点:这两个都是dom的属性,不是方法
根据父级,选择子级:
oDiv.children; //返回一个伪数组
根据子级,选择父级:
oSpan.parentNode; //返回一个元素