1. 广播变量
1.1 补充知识(来源:https://blog.csdn.net/huashetianzu/article/details/7821674)
之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://jobtracker:50030/home/XXX/file)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。(2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。而对于spark而言,其提供广播变量的方法,是的每个executor中都会有一份小文件副本
1.2 广播变量的使用场景
通常是为了实现map-side join,可以将Driver端的数据广播到属于该application的Executor,然后通过Driver广播变量返回的引用,获取实现广播到Executor的数据
1.3 广播变量的实现原理
广播变量是通过BT的方式广播的(TorrentBroadcast),多个Executor(driver端的数据就会被分成多份数据分别广播至各个executor)可以相互传递数据,可以提高效率
sc.broadcast这个方法是阻塞的(同步的)
广播变量一但广播出去就不能改变(这是其缺点,因为实际应用中有时候是需要更新小文件的信息的,如spark03中1.3例子中 的ip规则数据),解决办法:为了以后可以定期的改变要关联的数据,可以定义一个object[单例对象],在函数内使用,并且加一个定时器,然后定期更新数据(这种做法可以更新关联数据,但效率没有广播变量的方式高,spark03中1.3的例子用的就是这个方法,只是没有加一个定时器)
原理图(还是以spark03中1.3的案例为例)
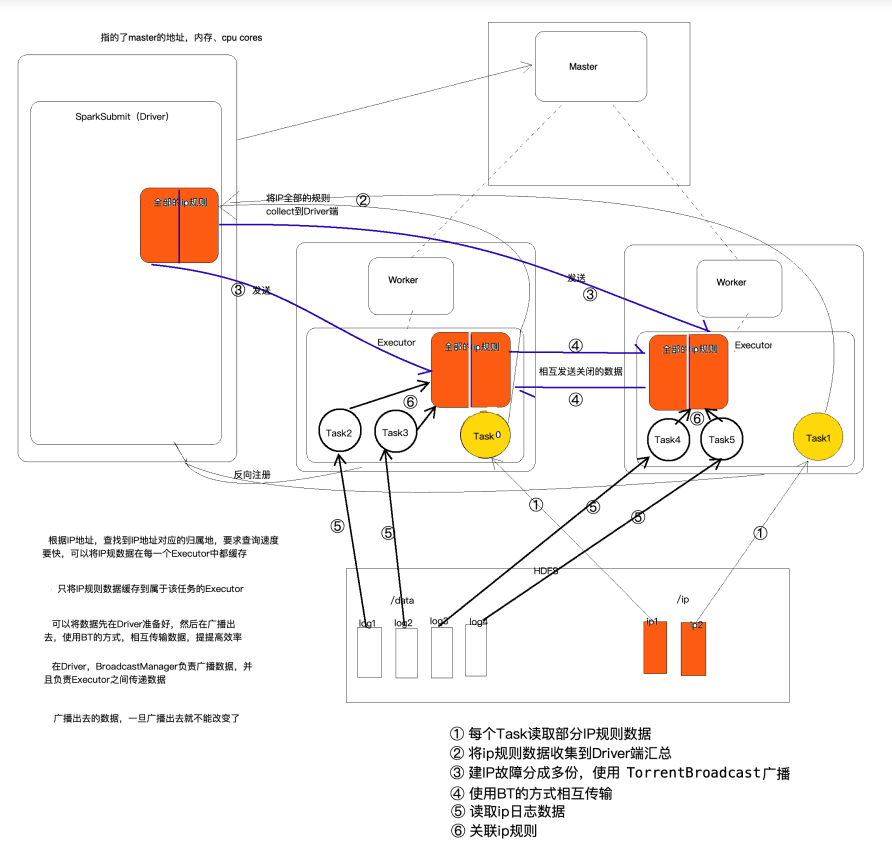
步骤:
(1)每个task读取部分IP规则数据(使用sc.textFile(),有可能将数据读取到一个executor中)
(2)将IP规则数据收集到Driver端汇总
(3)将ip规则数据分成多份(视executor的个数定),使用TorrentBroadcast广播
(4)各个executor中的数据使用BT的方式互相传播,以至于每个executor中都有一份完整的ip规则数据
问题:是不是可以将task中读取到的数据不收集到driver端,直接在各个executor中互相传输
不可以,这些数据的传输是通过driver来控制的,不然各个executor不知道要怎么传输,传输给谁。
driver想要控制这些数据的互相传输,需要调用broadcast方法并且返回一个引用。以后driver端就可以通过这个引用找到事先广播好的数据
(5)读取ip日志信息(属于大数据)
(6)关联ip规则
问题:此处的运行在各个executor中的task如何找到ip规则数据进行关联操作的呢?
调用broadcast方法返回的引用随task一起被调度到executor中,所以task能找到广播好的数据。
案例 使用Spark读取日志文件,根据IP地址,查询日志文件中的IP地址对应的位置信息 ,并统计处各个省份的用户量(使用广播变量的形式)
代码如下(BroadcastIpRules):


object BroadcastIpRules { def main(args: Array[String]): Unit = { // 决定是否在本地运行 val isLocal = args(0).toBoolean val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName) if(isLocal){ conf.setMaster("local[*]") } //创建sparkcontext,用来创建rdd val sc: SparkContext = new SparkContext(conf) val ipLines: RDD[String] = sc.textFile(args(1)) // 加载并处理ip规则数据 val ipRulesRDD: RDD[(Long, Long, String, String)] = ipLines.map(ipLine => { val split: Array[String] = ipLine.split("\|") val longStartIp: Long = split(2).toLong val longEndIp: Long = split(3).toLong val province: String = split(6) val city: String = split(7) (longStartIp, longEndIp, province, city) }) // 将ip规则数据收集到driver端 val ipRules: Array[(Long, Long, String, String)] = ipRulesRDD.collect() // 将driver端的ip规则数据广播到各个executor中,广播完成后返回各个executor中存储数据的地址引用 val ipRulesRef: Broadcast[Array[(Long, Long, String, String)]] = sc.broadcast(ipRules) // 读取日志信息文件 val logLines: RDD[String] = sc.textFile(args(2)) //处理要计算的数据并关联事先广播到Executor中的规则 val provinceRDD: RDD[(String, Int)] = logLines.map(logLine => { val split: Array[String] = logLine.split("\|") val logIp: String = split(1) val ipNum: Long = IpUtils.ip2Long(logIp) // 通过广播返回的引用找到executor中的数据 val ipRulesInExecutor: Array[(Long, Long, String, String)] = ipRulesRef.value val index: Int = IpUtils.binarySearch(ipRulesInExecutor, ipNum) var province: String = "未知" if (index != -1) { province = ipRulesInExecutor(index)._3 } (province, 1) }) // 按照省份聚合 val res: RDD[(String, Int)] = provinceRDD.reduceByKey(_+_) //建计算结果保存到HDFS中 res.saveAsTextFile(args(3)) //释放资源 sc.stop() } }
此处采用在服务器的模式中运行
步骤:
(1)将上面代码打包,得到spark01-1.0-SNAPSHOT.jar形式的jar包
(2)并将这个jar包上传值需要运行的服务器上(此处我只上传到了master节点上)
(3)运行,命令如下:
/usr/apps/spark-2.3.3-bin-hadoop2.7/bin/spark-submit --class com._51doit.spark04.BroadcastIpRules --master spark://feng05:7077 --executor-memory 1g --total-executor-cores 4 spark01-1.0-SNAPSHOT.jar false hdfs://feng05:9000/ip/ip.txt hdfs://feng05:9000/data/ipaccess.log hdfs://feng05:9000/out2
广播变量做法的优缺点(较spark03中1.3的例子)
优点:
(1)使用广播变量实现mapside join,提升关联效率
(2)使用广播变量比单例对象加载规则数据效率更快
缺点:
广播出去的规则数据一旦广播后就无法修改
2. RDD中的cache和persist(来源:https://blog.csdn.net/sunspeedzy/article/details/69055072)
2.1 RDD的缓存级别
由以下源码可知,RDD有12中缓存级别
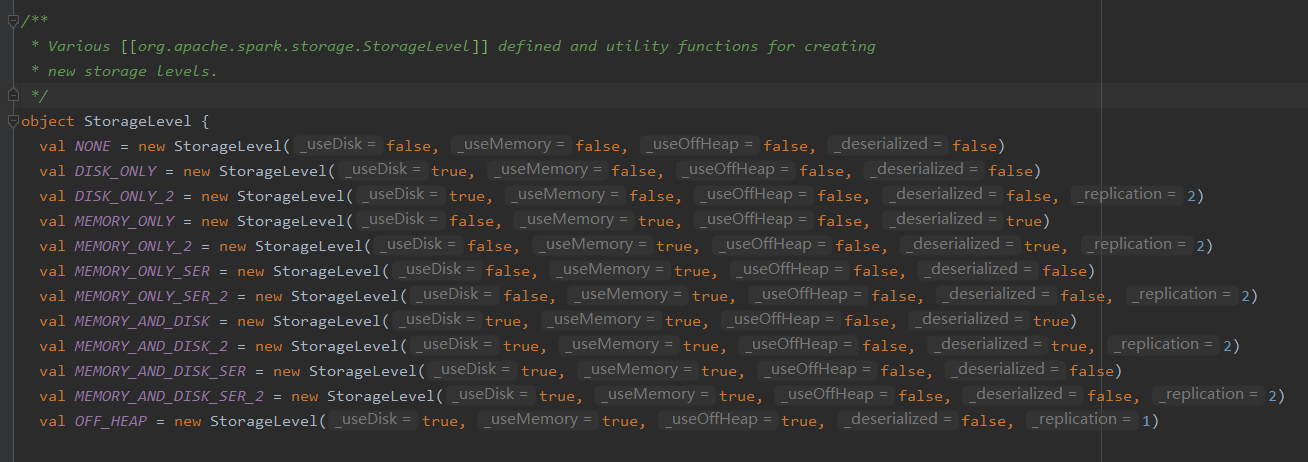
查看其构造函数
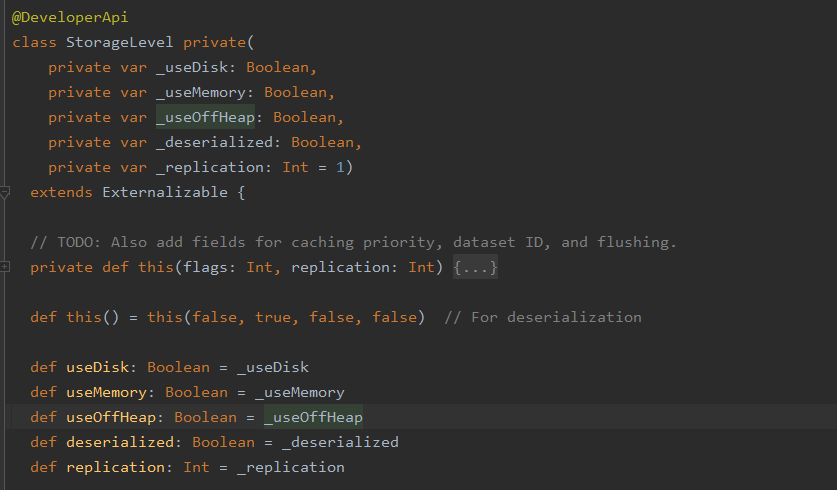
可以看到StorageLevel类的主构造器包含了5个参数:
- useDisk:使用硬盘
- useMemory:使用内存
- useOffHeap
使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
- deserialized
反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象。序列化方式存储对象可以节省磁盘或内存的空间,一般 序列化:反序列化=1:3
- replication:备份数(在多个节点上备份),默认是1份
理解了这5个参数,StorageLevel 的12种缓存级别就不难理解了。
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) 就表示使用这种缓存级别的RDD将存储在硬盘以及内存中,使用序列化(在硬盘中),并且在多个节点上备份2份(正常的RDD只有一份)
2.2 Spark RDD Cache,persist
cache既算不上transformations算子也算不上Action算子,源码中并没有返回一个新的RDD
允许将RDD缓存到内存中或磁盘上, 以便于重用 。Spark提供了多种缓存级别, 以便于用户根据实际需求进行调整
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间。
cache例子
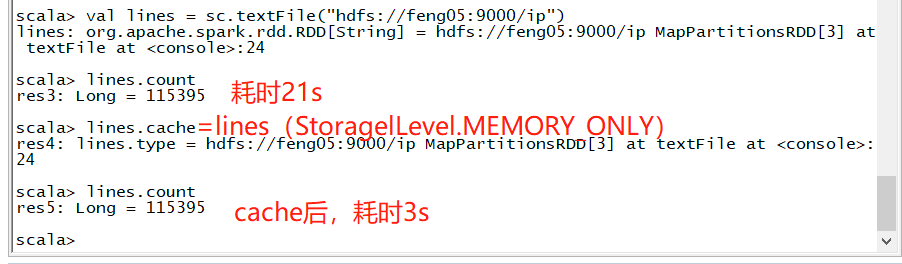
persist例子
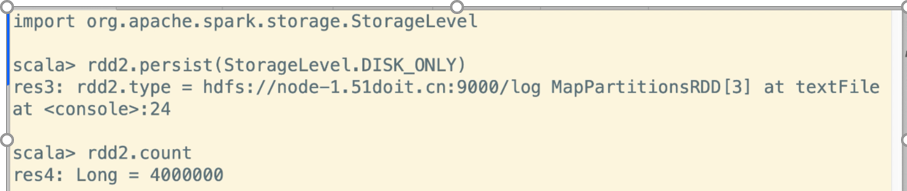
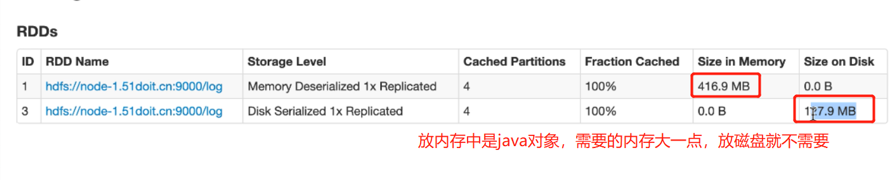

可见,放磁盘中比方catch慢,但比从hdfs中快
2.3 cache和persis的区别
基于spark2.3.3中的源码

从这段远吗可知。cache()调用了persist(),想要知道二者的不同,还需要看一下persist函数

可见persist方法内部调用了persist(StorageLevel.MEMORY_ONLY)方法,进一步查看此方法源码,如下
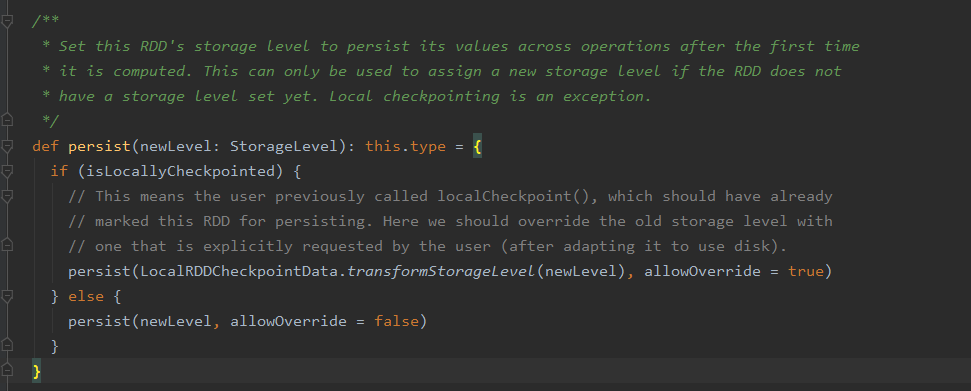
可以看出来persist有一个 StorageLevel 类型的参数,这个表示的是RDD的缓存级别。
至此便可得出cache和persist的区别了:cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
3.RDD的checkpoint方法
可以看的博客(https://blog.csdn.net/legotime/article/details/51290958)
当checkpoint为当前RDD设置检查点的时候,该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。当需要checkpoint的数据的时候,通过ReliableCheckpointRDD的readCheckpointFile方法来从file路径里面读出已经Checkpint的数据,然后加以应用
由于在checkpoint过程中,RDD的所有依赖于父RDD中的信息将全部被移出的特性,使用checkpoint前一遍都会使用catch,达到服用中间结果的目的。若是不cache,当一个rdd被checkpoint后,使用action将其触发后,其要先计算出原来已经有的结果,然后再将这个结果保存至hdfs,相当于有两个job。

例子

4. 计算学科最受欢迎老师TopN
需求:根据网站的行为日志,统计每个学科最受欢迎老师的TopN,即按照学科分组,在每一个组内进行排序
样例数据

4.1 实现方式一
调用groupBy按照学科进行分组,然后将value对应的迭代器toList,将数据全部加载到内存中,然后在调用List的sortBy方法进行排序,然后再调用take取TopN
object FavoriteTeacher { def main(args: Array[String]): Unit = { // 判断是否在本地运行 val isLocal: Boolean = args(0).toBoolean val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName) if(isLocal){ conf.setMaster("local[*]") } // 创建SparkContext val sc: SparkContext = new SparkContext(conf) // 读取文件的信息,得到相应的RDD val teacherLines: RDD[String] = sc.textFile(args(1)) // 对数据进行切分,获取一些信息 val teacherAndSubjectRDD: RDD[((String, String), Int)] = teacherLines.map(line => { val split: Array[String] = line.split("/") val subject: String = split(2).split("\.")(0) //获取科目信息 val teacher: String = split(3) ((subject, teacher), 1) }) // 聚合 val reducedRDD: RDD[((String, String), Int)] = teacherAndSubjectRDD.reduceByKey(_+_) // 按照学科进行分组 val grouped: RDD[(String, Iterable[((String, String), Int)])] = reducedRDD.groupBy(_._1._1) // 分组排序(降序) val topN = args(2).toInt val sorted: RDD[(String, List[((String, String), Int)])] = grouped.mapValues(_.toList.sortBy(-_._2).take(topN)) // 将数据收集到driver端,同时触发Action val res: Array[(String, List[((String, String), Int)])] = sorted.collect() println(res.toBuffer) sc.stop() } }
如果分组后,每一个组内的数量比较大,将迭代器toList会造成内存溢出,所以如果分组后组内的数据量比较大,这样的方式不适合。
4.2 实现方式二
上面先分组,再将每一个组对应的迭代器的数据toList后再排序,可能会出现内存溢出,所以现在使用的方式是先将每一个学科的数据单独过滤出来,然后调用RDD的sortBy方法进行排序,RDD的sortBy方法使用的是RangePartitioner,使用内存加磁盘进行排序,不会出现内存溢出。
代码如下
object FavoriteTeacher2 { def main(args: Array[String]): Unit = { // 判断是否在本地运行 val isLocal: Boolean = args(0).toBoolean val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName) if(isLocal){ conf.setMaster("local[*]") } // 创建SparkContext val sc: SparkContext = new SparkContext(conf) // 读取文件的信息,得到相应的RDD val teacherLines: RDD[String] = sc.textFile(args(1)) // 对数据进行切分,获取一些信息 val teacherAndSubjectRDD: RDD[((String, String), Int)] = teacherLines.map(line => { val split: Array[String] = line.split("/") val subject: String = split(2).split("\.")(0) //获取科目信息 val teacher: String = split(3) ((subject, teacher), 1) }) // 聚合 val reducedRDD: RDD[((String, String), Int)] = teacherAndSubjectRDD.reduceByKey(_+_) // 缓存 reducedRDD.cache() // 计算学科种类,并收集到driver端 val subjects: Array[String] = reducedRDD.map(_._1._1).distinct().collect() val topN = args(2).toInt for(subject <- subjects){ val filtered: RDD[((String, String), Int)] = reducedRDD.filter(t => t._1._1.equals(subject)) val res: Array[((String, String), Int)] = filtered.sortBy(_._2, false).take(topN) println(res.toBuffer) } // 释放资源(也会将cache释放掉) //reduced.unpersist(true) sc.stop() } }
4.3 实现方式三(自定义分区器)
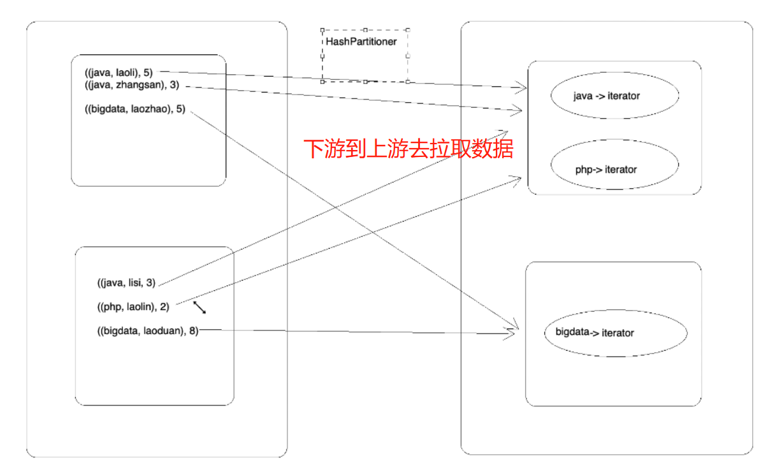
实现方式二中使用的是默认的分区器,这种情况可能会出现多个学科数据被分到一个分区里(key中hashcode的值对下游分区数求余),如下图,这样这个分区对应的task就要处理更多的数据,不太好。解决办法:自己定义分区器,确保每个学科都被分到不同的分区中去。自己定义分区器要实现两点,(1)如何分区(即给定数据,其能知道分几个区,此处是按学科的种类数进行分区)(2)给定一个值能知道是哪一个分区(此处给定一个学科可以知道是属于哪个分区)
代码
object FavoriteTeacher03 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) //指定以后从哪里读取数据创建RDD val lines: RDD[String] = sc.textFile(args(1)) //对数据进行切分 val subjectTeacherAndOne = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("[.]")(0) val teacher = fields(3) ((subject, teacher), 1) }) //聚合 val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey(_+_) //全局排序,我想要的是分组TopN //val sorted = reduced.sortBy(_._2, false) //将reduced cache到内存 reduced.cache() //计算所有的学科,并收集到Driver端 val subjects: Array[String] = reduced.map(_._1._1).distinct().collect() //paritioner是在Driver端被new出来的,但是他的方法是在Executor中被调用的 val partitioner = new SubjectPartitioner(subjects) //reduced使用指定的分区器对数据进行分区 val partitionedRDD: RDD[((String, String), Int)] = reduced.partitionBy(partitioner) //将每一个分区中的数据进行处理 val result = partitionedRDD.mapPartitions(it => it.toList.sortBy(-_._2).take(2).iterator) //触发Action,打印 val r = result.collect().toBuffer println(r) sc.stop() } } // 使用class而不是object,以后每个task都可能需要自己的分区器,使用object就变成单例的了 class SubjectPartitioner(val subjects: Array[String]) extends Partitioner { //初始化分器的分区规则 val rules = new mutable.HashMap[String, Int]() var index = 0 for(sub <- subjects) { rules(sub) = index index += 1 } override def numPartitions: Int = subjects.length //该方法会在Executor中的Task中被调用 override def getPartition(key: Any): Int = { val tuple = key.asInstanceOf[(String, String)] val subject = tuple._1 //到实现初始化的规则中查找这个学科对应的分区编号 rules(subject) } }
此方法可能也会发生内存溢出,即将迭代器toList的时候(当一个分区的数据足够大)
四. 实现方式四
实现方式3还有个明显的缺点,即需要shuffle的地方太多,有三处,如下

解决办法,reduceByKey有一个重载的方法,可以传入一个分区器,在数据聚合的时候就可以实现按特定分区器进行分区的目的
代码如下
package com._51doit.spark04 import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} import scala.collection.mutable object FavoriteTeacher4 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) //指定以后从哪里读取数据创建RDD val lines: RDD[String] = sc.textFile(args(1)) //对数据进行切分 val subjectTeacherAndOne = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("[.]")(0) val teacher = fields(3) ((subject, teacher), 1) }) //计算所有的学科,并收集到Driver端 val subjects: Array[String] = subjectTeacherAndOne.map(_._1._1).distinct().collect() //paritioner是在Driver端被new出来的,但是他的方法是在Executor中被调用的 val partitioner = new SubjectPartitioner2(subjects) //根据指定的key和分区器进行聚合(减少一次shuffle) val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey(partitioner, _+_) val topN = args(2).toInt val result = reduced.mapPartitions(it => { //定义好一个排序规则 implicit val sortRules: Ordering[((String, String), Int)] = Ordering[Int].on[((String, String), Int)](t => -t._2) //定义一个key排序的集合TreeSet val sorter = new mutable.TreeSet[((String, String), Int)]() //遍历出迭代器中的数据 it.foreach(t => { sorter += t if (sorter.size > topN) { val last = sorter.last //移除最后一个 sorter -= last } }) sorter.iterator }) val r = result.collect() println(r.toBuffer) sc.stop() } } class SubjectPartitioner2(val subjects: Array[String]) extends Partitioner { //初始化分器的分区规则 val rules = new mutable.HashMap[String, Int]() var index = 0 for(sub <- subjects) { rules(sub) = index index += 1 } override def numPartitions: Int = subjects.length //该方法会在Executor中的Task中被调用 override def getPartition(key: Any): Int = { val tuple = key.asInstanceOf[(String, String)] val subject = tuple._1 //到实现初始化的规则中查找这个学科对应的分区编号 rules(subject) } }
此处值得学习的代码

此处用到的on方法,如下

其相当于new Ordering[((String, String), Int)],完整写法应该如下
implicit val sortRules: Ordering[((String, String), Int)] = new Ordering[((String, String), Int)] { override def compare(x: ((String, String), Int), y: ((String, String), Int)): Int = { y._2-x._2 } }