1. 读取数据库的形式创建DataFrame
DataFrameFromJDBC
object DataFrameFromJDBC { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // df.printSchema() // import spark.implicits._ // df.where($"total_money" > 500).show() // 此种形式一定要导入隐式转换 df.where("money > 500").show() // 可以不导入隐式转换 } }
2. Parquet格式的数据源
2.1 spark读取的数据源效率高低需要考虑下面三点
- 1. park SQL可以读取结构化数据,读取对应格式 数据可以返回DataFrame【元数据信息,不返回的话就要自己关联shema信息,如下图】
数据存储格式有schema信息
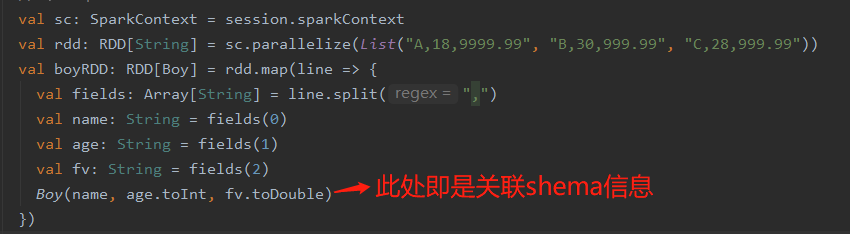
- 2. 数据存储空间更小
有特殊的序列化机制,可以使用高效的压缩机制
- 3. 读取的效率更高
使用高效的序列化和反序列化机制,可以指定查询哪些列,不select某些列,就不读取对应的数据(以前rdd读取数据的话是每行数据的所有列(字段)都会读取)
2.2 json、csv、Parquet形式的数据源的读取效率对比
2.2.1
(1)json(满足2.1中的1)

数据会有冗余,name、age等字段属性会被多次读取
(2)csv(满足2.1中的2)
此种形式的数据读取只会读取一次字段属性,效率相比json的形式高点,但它默认没有压缩方式
(3)Parquet(满足2.1中的三点,是sparksql最喜欢的数据源格式)
读取数据可以返回元数据信息、
支持压缩,默认是snappy压缩
更加高效的序反列化,列式存储
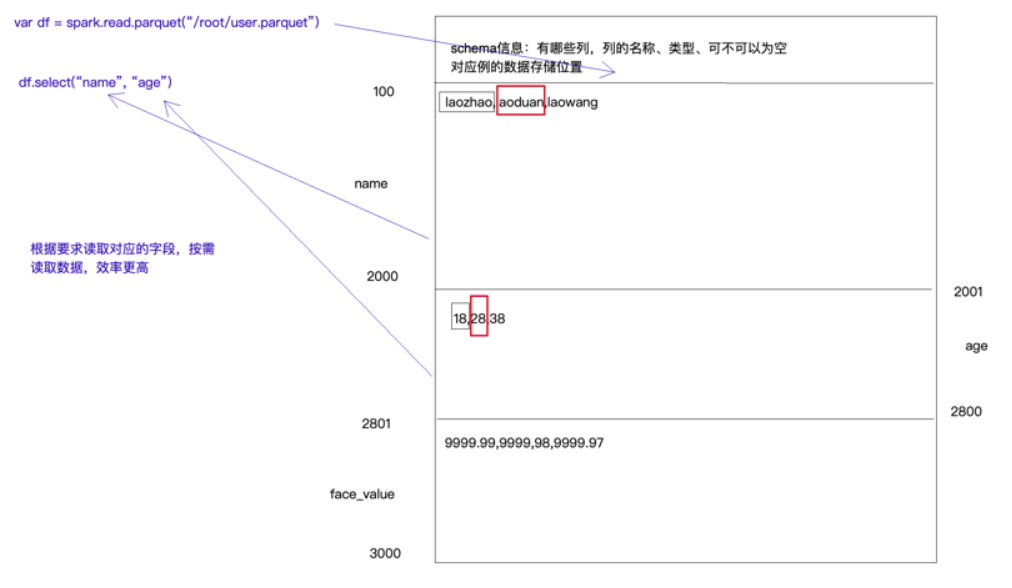
2.2.2 案 例:
(1)获取parquet格式数据
object JDBCToParquet { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // 将df的数据转换成parquet df.write.parquet("E:/javafile/spark/out1") spark.stop() } }
得到的文件部分内容如下(可见是被处理过的)
(2)读取parquet格式的文件
object JDBCToParquet { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val df: DataFrame = spark.read.parquet("E:/javafile/spark/part1.snappy.parquet") //df.show() //parquet格式是列式存储,可以按需查询,效率更高 df.select("cname", "money").show() spark.stop() } }
运行结果
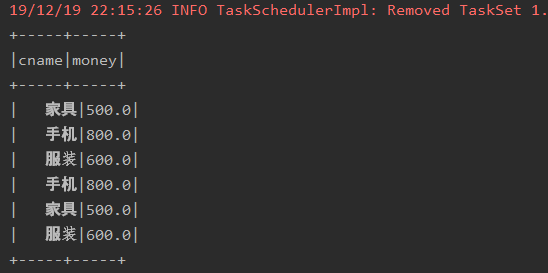
3. Orc格式的数据源
(1)获取Orc格式数据(hive 使用MR喜欢的数据格式)


package com._51doit.spark08 import java.util.Properties import org.apache.spark.sql.{DataFrame, SparkSession} object JDBCToOrc { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .enableHiveSupport() // 让sparkSQL开启对Hive的支持 .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 使用sparksession创建DF val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8", "t_result", probs) // 将df数据转换成Orc df.write.orc("E:/javafile/spark/out2") spark.stop() } }
(2)读取Orc格式的文件
object OrcDataSource { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .enableHiveSupport() // 让sparkSQL开启对Hive的支持 .getOrCreate() // 读取Orc数据源 val df: DataFrame = spark.read.orc("E:/javafile/spark/out2") // df.printSchema() df.where("money > 500").show() spark.stop() } }
4.spark_sql整合hive
(1)安装mysql并创建一个普通用户,并且授权(nysql5.7后密码不能设置的很简单)
set global validate_password_policy=LOW; set global validate_password_length=6; CREATE USER 'bigdata'@'%' IDENTIFIED BY '123456'; GRANT ALL PRIVILEGES ON hivedb.* TO 'bigdata'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; FLUSH PRIVILEGES;
(2)在spark的conf目录下。添加一个hive-site.xml,指向mysql的源数据库hivedb
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://feng05:3306/hivedb?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>bigdata</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>feng</value> <description>password to use against metastore database</description> </property> </configuration>
(3)上传一个mysql链接驱动,并启动spark_sql
./spark-sql --master spark://feng05:7077 --executor-memory 800m --total-executor-cores 3 --driver-class-path /root/mysql-connector-java-5.1.39.jar
(4)执行(3)操作后,sparkSQL会在mysql上创建一个database(hivedb),需要手动改一下DBS表中的DB_LOCATION_UIR改成hdfs的地址,如下
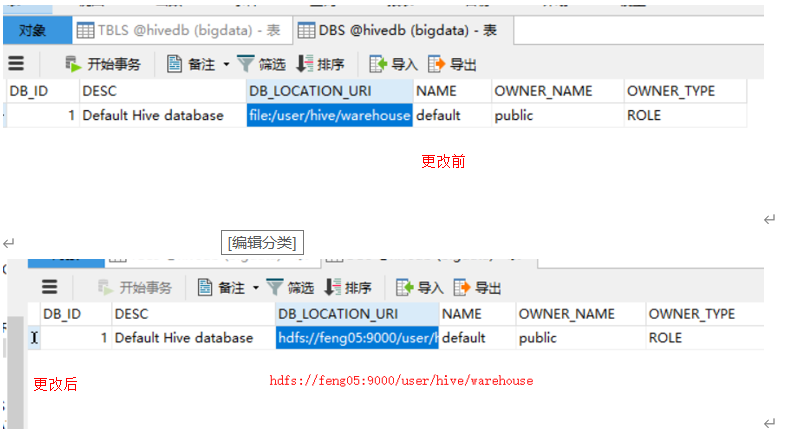
(5)重新启动SparkSQL的命令行,即可完成spark与hive的整合

(6)由上面可知,操作时会出现大量的日志信息,想要改变这种情况,可以如下操作
进入安装spark目录中测conf文件(/usr/apps/spark-2.3.3-bin-hadoop2.7/conf),将log4j.properties.template文件改成log4j.properties,并编辑内容如下
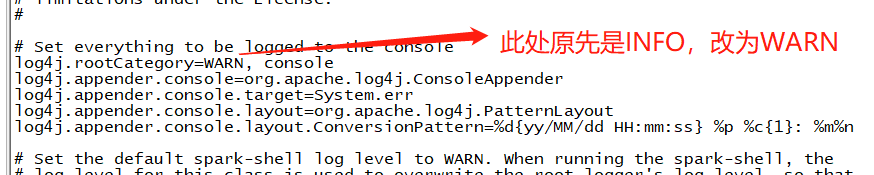
(7) 重启spark_sql即可得到干净无太多日志信息的界面,如下

补充:
- -e 后面跟SQL命令
./spark-sql --master spark://node-1.51doit.cn:7077 --executor-memory 1g --total-executor-cores 4 --driver-class-path /root/mysql-connector-java-5.1.47.jar -e "select * from user"
- -f 后面跟sql脚本
./spark-sql --master spark://node-1.51doit.cn:7077 --executor-memory 1g --total-executor-cores 4 --driver-class-path /root/mysql-connector-java-5.1.47.jar -f /root/hql.sql
5.在IDEA中编写spark程序,用来操作hive,分析数据
代码如下
/** * 在IDEA中编写spark程序,并且支持hive,可以使用Hive的源数据库 */ object SparkHive { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") val spark = SparkSession.builder() .appName("SparkHive") .master("local[*]") .enableHiveSupport() //开启Spark对Hive的支持,spark完全兼容Hive .getOrCreate() //读取HDFS中的非结构化数据,对数据进行处理 //在hive中建表 //写Hive SQL分析数据 spark.sql("CREATE TABLE person (id bigint, name string, age int) ROW FORMAT" + " DELIMITED FIELDS TERMINATED BY ','" ) spark.sql("LOAD DATA LOCAL INPATH '/Users/star/Desktop/person.txt' INTO TABLE person") val df = spark.sql("SELECT * FROM person WHERE id > 2") df.show() spark.stop() } }
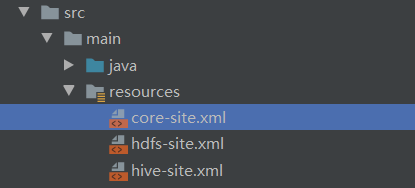
注意:需要添加如下三个配置文件
6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
数据
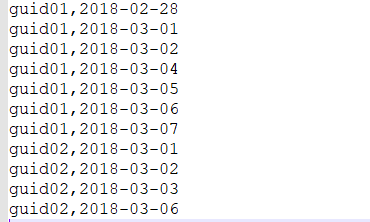
需求:连续登陆三天的用户
5.1 SQL风格
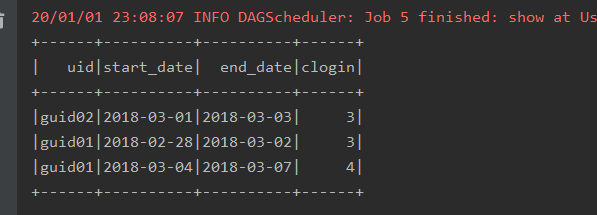
package com._51doit.spark08 import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object UserContinueLoginSQL { def main(args: Array[String]): Unit = { // 创建SparkSession val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 读取文件创建DataSet val access: DataFrame = spark.read.option("header", "true") .csv("F:\大数据第三阶段\spark\spark-day09\资料\access.csv") // 注册成视图 access.createTempView("v_access_log") spark.sql( s""" |SELECT |uid, |MIN(dt) start_date, |MAX(dt) end_date, |count(*) clogin |FROM |( | SELECT | uid, | dt, | date_sub(dt, n) diff | FROM | ( | SELECT | uid, | dt, | row_number() over(partition by uid order by dt) n | FROM | v_access_log | ) t1 |) t2 |GROUP BY uid,diff |HAVING clogin >= 3 |""".stripMargin ).show() spark.stop() } }
结果
5.2 DSL风格
package com._51doit.spark08 import org.apache.spark.sql.expressions.{Window, WindowSpec} import org.apache.spark.sql.{DataFrame, SparkSession} object UserContinueLoginDSL { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() //读取csv文件创建DataFrame val access: DataFrame = spark.read.option("header", "true") .csv("F:\大数据第三阶段\spark\spark-day09\资料\access.csv") //DSL风格的API import spark.implicits._ val win: WindowSpec = Window.partitionBy($"uid").orderBy($"dt") import org.apache.spark.sql.functions._ access.select($"uid", $"dt", row_number.over(win) as "rn") .select($"uid", $"dt", expr("date_sub(dt, rn) as dif")) .groupBy("uid", "dif") .agg(count("*") as "counts", min("dt") as "start_date", max("dt") as "end_data") .filter("counts >= 3") .select("uid", "start_date", "end_data", "counts") .show() spark.stop() } }
结果

5.3 RDD形式
package com._51doit.spark09 import java.text.SimpleDateFormat import java.util.{Calendar, Date} import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} import scala.collection.mutable object UserContinuedLoginRDD { def main(args: Array[String]): Unit = { // // 判断是否本地运行 // val isLocal = args(0).toBoolean // val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName) // if(isLocal){ // conf.setMaster("local[*]") // } // 创建SparkContext val conf = new SparkConf() .setAppName(this.getClass.getName) .setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val lines: RDD[String] = sc.textFile("E:/javafile/spark/access.csv") // 数据处理,获取(uid, date)形式的RDD val UidDateAndNull: RDD[((String, String), Null)] = lines.map(line => { val fields: Array[String] = line.split(",") val uid = fields(0) val date = fields(1) ((uid, date), null) }) // 求分区的个数 val uids: Array[String] = UidDateAndNull.keys.map(_._1).distinct().collect() // 自定义分区器,根据uid分区,并按照(uid,date排序) val sortedInPartition: RDD[((String, String), Null)] = UidDateAndNull.repartitionAndSortWithinPartitions(new Partitioner() { // 默认按照key排序,所以上面需为((uid,date), null) val idToPartitionId = new mutable.HashMap[String, Int]() for (i <- uids.indices) { idToPartitionId(uids(i)) = i } override def numPartitions: Int = uids.length override def getPartition(key: Any): Int = { val tp: (String, String) = key.asInstanceOf[(String, String)] idToPartitionId(tp._1) } }) // 给处理后的数据打上行号 val uidTimeAndDate: RDD[((String, Long), String)] = sortedInPartition.mapPartitions(it => { val sdf: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd") val calendar = Calendar.getInstance() var i = 0 it.map(t => { i += 1 val uid = t._1._1 val dateStr = t._1._2 val date: Date = sdf.parse(dateStr) calendar.setTime(date) calendar.add(Calendar.DATE, -i) val dif = calendar.getTime.getTime ((uid, dif), dateStr) }) }) // 进行计算 val firstResult: RDD[((String, Long), (String, String, Int))] = uidTimeAndDate.groupByKey().mapValues(it => { val sorted: Seq[String] = it.toList.sorted //连续登陆的次数 val counts = sorted.size //起始时间 val start_date = sorted.head //结束时间 val end_date = sorted.last (start_date, end_date, counts) }) // 最终结果 val result: RDD[(String, String, String, Int)] = firstResult.filter(_._2._3 >= 3).map(t => (t._1._1, t._2._1, t._2._2, t._2._3)) //输出结果 val r = result.collect() println(r.toBuffer) sc.stop() } }
结果

此处注意的知识点:
calendar, 自定义分区器