1. Redis
Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库)。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set有序集合)和hash(哈希类型)。
1.1 redis的安装(源码安装方式,官网供下载的redis,没有编译的,需要自己编译)
(1)下载redis4的稳定版本
(2)上传redis-4.0.14.tar.gz到Linux服务器
(3)解压redis源码包,至指定的位置
tar -zxvf redis-4.0.14.tar.gz -C /usr/local/src/ // 一般源码类放此文件夹,也可以自己选个位置
(4)进入到源码包中,编译
cd /usr/local/src/redis-4.0.14/
make
若报如下错:
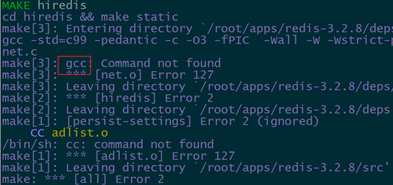
没有安装C语言的环境,redis的开发语言为C
(5)在linux中安装C语言环境
- 有网的情况下
yum -y install gcc // 有网的情况下
- 无网的情况,
配置本地yum源,具体见大数据学习day02
yum list | grep gcc // 查看yum源中的gcc版本

安装C语言环境
yum -y install gcc gcc-c++
(7)重新编译
make
如果报如下错
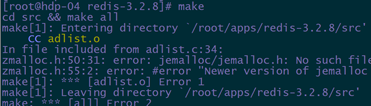
解决办法:
make MALLOC=libc
(8)安装
make install
(9) 在/usr/local/下创建一个redis目录,然后拷贝redis自带的配置文件redis.conf到/usr/local/redis中
mkdir /usr/local/redis cp /usr/local/src/redis-4.0.14/redis.conf /usr/local/redis
(10).修改当前机器的配置文件redis.conf
bind 172.16.200.103 127.0.0.1 daemonize yes #redis后台运行 requirepass 123456 #指定redis的密码 dir /data/redis #redis数据存储的位置 appendonly yes #开启aof日志,它会每次写操作都记录一条日志
(11)启动redis节点
redis-server /usr/local/redis/redis.conf

(12)查看redis进程状态
ps -ef | grep redis
如下,表示启动成功

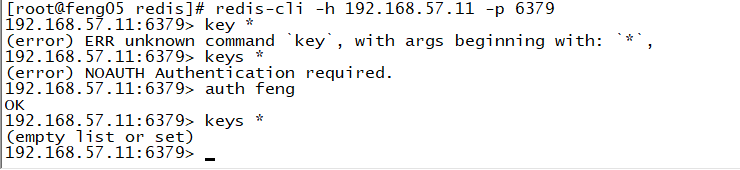
(13)使用命令登录
redis-cli -h 192.168.57.11 -p 6379
此时需要验证密码,否则没有操作权限
auth feng
2 Redis客户端
2.1 redis自带的客户端

指定启动参数:-h;指定主机IP -p:指定主机端口; 验证密码: auth 密码
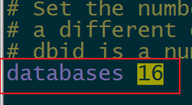
Redis安装成功之后,默认有16个数据库(可在redis.conf文件中看到,如下图),每个库之间是互相独立的。
默认存储的数据是放到db0中的,切换数据库的命令:select 数据库编号

补充:
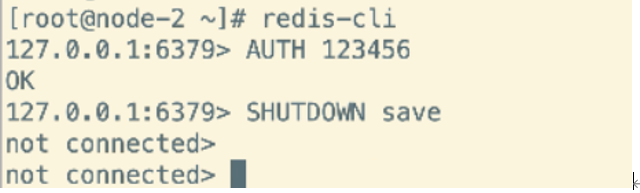
关闭redis的命令
2.2 java客户端
2.2.1 jedis介绍
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持,比如java、C、C#、C++、php、Node.js、Go等。
在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis、等其中官方推荐使用Jedis和Redisson。 在企业中用的最多的就是Jedis,下面我们就重点学习下Jedis。
Jedis同样也是托管在github上,地址:https://github.com/xetorthio/jedis
2.2.2 搭建maven工程
创建一个maven project并导入jar包依赖。
添加pom依赖:
<dependencies> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.0.1</version> </dependency> </dependencies>
3.2.3 单实例链接redis
public class RedisClient { public static void main(String[] args) { // 指定主机名和端口 Jedis jedis = new Jedis("feng05", 6379); jedis.auth("feng"); //选择使用哪个db,默认使用db0 jedis.select(0); // 测试连通 String ping = jedis.ping(); System.out.println(ping); // 关闭链接 jedis.close(); } }
3.2.3 使用连接池连接redis
public class RedisClient2 { public static void main(String[] args) { // 创建连接池 JedisPool pool = new JedisPool("feng05", 6379); // 通过连接池获取jedis实例 Jedis jedis1 = pool.getResource(); Jedis jedis2 = pool.getResource(); jedis1.auth("feng"); jedis2.auth("feng"); jedis1.set("name","zs"); String name = jedis2.get("name"); System.out.println(name); } }
3.Redis的数据类型(见redis文档)
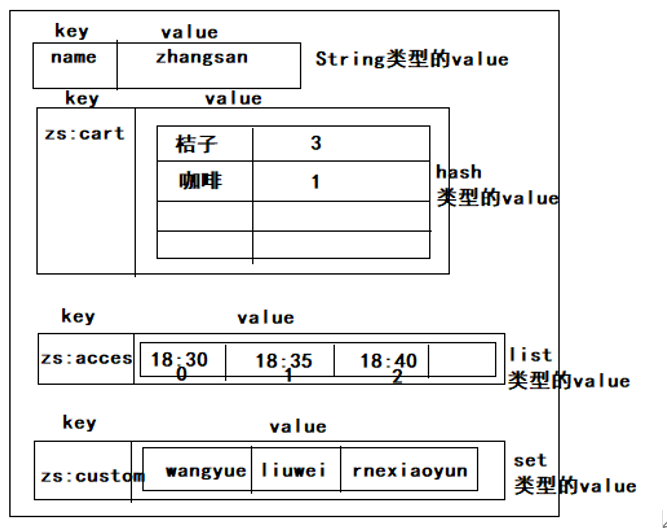
Redis中存储数据是通过key-value存储的,对于value的类型有以下几种:
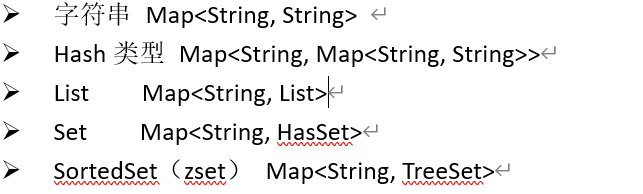
在redis中的命令语句中,命令是忽略大小写的,而key是不忽略大小写的。
3.1 String数据类型操作
删除所有的数据 flushdb ,注意 慎用该命令
(1)设置k-v:set key value
OK 127.0.0.1:6379> keys * 1) "name" 127.0.0.1:6379> get name "zhangsan" 127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> get age "18"
(2)自增(incr),自减(decr),自增(减)指定数值(子增减的步长) : incrby decrby
127.0.0.1:6379> incr age (integer) 19 127.0.0.1:6379> incr name (error) ERR value is not an integer or out of range 自增指定数值(自增的步长) incrby decrby 127.0.0.1:6379>incrby age 2 (integer) 21
(3)删除: del
127.0.0.1:6379> del name (integer) 1 127.0.0.1:6379> del xxx (integer) 0
(4)同时设置,获取多个键值
语法:
MSET key value [key value …]
MGET key [key …]
如
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> mget k1 k3 1) "v1" 2) "v3"
(5)STRLEN命令返回键值的长度,如果键不存在则返回0 :STRLEN key
127.0.0.1:6379> strlen str (integer) 0 127.0.0.1:6379> set str hello OK 127.0.0.1:6379> strlen str (integer) 5
4.kafka
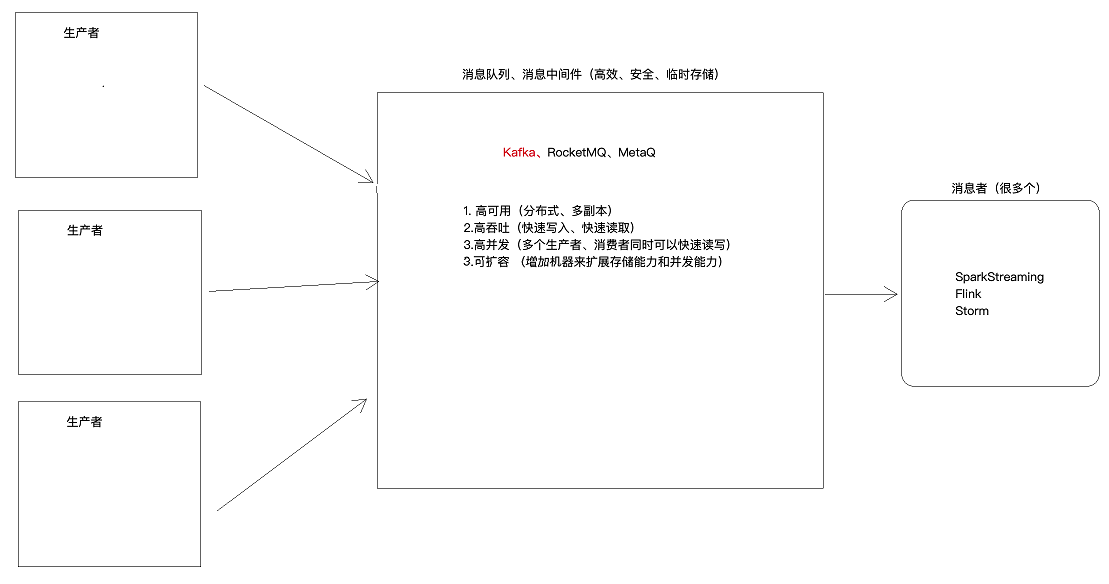
4.1 Kafka的概念
(1)Broker:安装了kafka的服务器
(2)Topic:主题,数据的分类,类似数据库中的表
(3)partition:分区,分区越多,并发能力越强,单个分区内的数据是有序的,若同一个broker中有多个leader分区,多个分区中的数据整体并不是有序的。分区的leader分区和folower由zk选举
leader分区负责读写(生产者和消费者连到Leader分区,folower分区负责同步数据)
(4)replication:副本,将数据存储多份,保证数据不丢
(5)Producer:消息的生产者,将数据发送到指定topic的leader分区
(6)Consumer:消息的消费者,从指定Topic的leader分区拉取数据,消费者会管理偏移量(记录数据读取到什么地方,避免数据重复消费)
(7)Consumer Group:消费者组,一个组中可以有多个消费者,数据不会重复消费
4.2 Kafka集群架构图
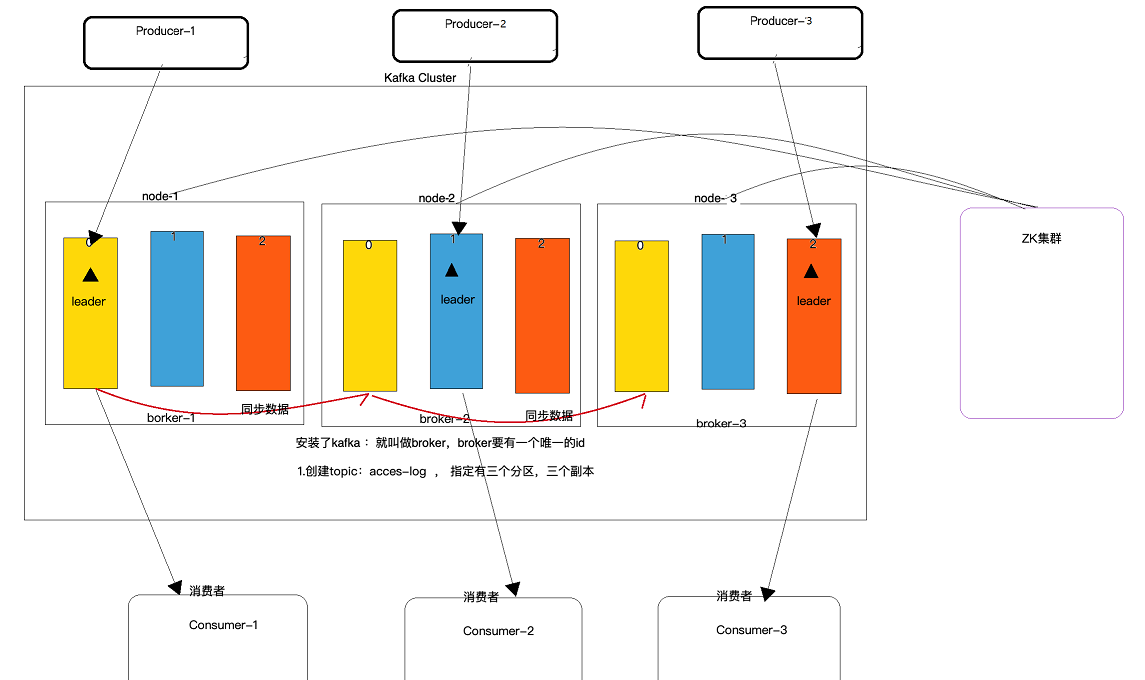
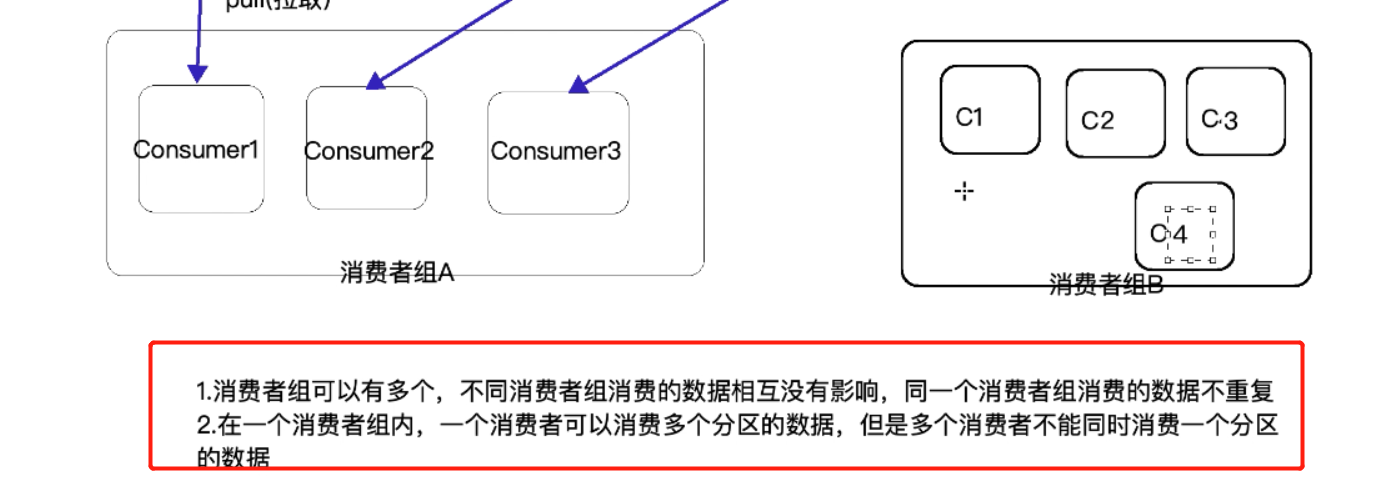
不同消费者组中的消费者可以消费同一个分区的数据,他们互不影响(各自记录各自的偏移量,都可以读取该分区内的所有数据)
总结:
.Kafka的生成者直接向Broker的Leader分区写入数据,不需要连接ZK
.Kafka的消费者(老的API需要先连接ZK,获取Broker信息和偏移量信息),新的API不需要连接ZK(直连方式,效率更高)
4.3 kafka集群的安装
前提:安装zookeeper,并启动
(1)上传kafka安装包,解压到自己想要的地址
(2)修改配置文件
#指定broker的id broker.id=1 #数据存储的目录 log.dirs=/data/kafka #指定zk地址 zookeeper.connect=feng05:2181,feng06:2181,feng07:2181 #可以删除topic的数据(一般测试的时候才配置此) delete.topic.enable=true
(3)将配置好的kafka拷贝到其他节点
[root@feng05 apps]# scp -r kafka_2.11-1.1.1 feng06:$PWD
(4)修改其他节点Kafka的broker.id
(5)在所有节点启动kafka
/usr/apps/kafka_2.11-1.1.1/bin/kafka-server-start.sh -daemon /usr/apps/kafka_2.11-1.1.1/config/server.properties
注意:此处不加-daemon的话,开启kafka是以守护进程的形式开启,加上-daemon就是以后台的形式开启kafka
(6)查看启动是否成功
至此安装完毕
4.4 一些简单命令
(1)查看kafka的topic
/usr/apps/kafka_2.11-1.1.1/bin/kafka-topics.sh --list --zookeeper localhost:2181
(2)创建topic
/usr/apps/kafka_2.11-1.1.1/bin/kafka-topics.sh --zookeeper feng05:2181 --create --topic wordcount --replication-factor 3 --partitions 3
(3)启动一个命令行生产者
/usr/apps/kafka_2.11-1.1.1/bin/kafka-console-producer.sh --broker-list feng05:9092,feng06:9092,feng07:9092 --topic wordcount

(4)启动一个命令消费者
/usr/apps/kafka_2.11-1.1.1/bin/kafka-console-consumer.sh --bootstrap-server feng05:9092 --topic wordcount --from-beginning
--from-beginning 消费以前产生的所有数据,如果不加,就是消费消费者启动后产生的数据
(5)删除topic(只有配置文件配置了可以删除topic,此操作才有用)
/usr/apps/kafka_2.11-1.1.1/bin/kafka-topics.sh --delete --topic wordcount --zookeeper localhost:2
(6) 查看topic详细信息
/usr/apps/kafka_2.11-1.1.1/bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic wordcount
分区的详细信息
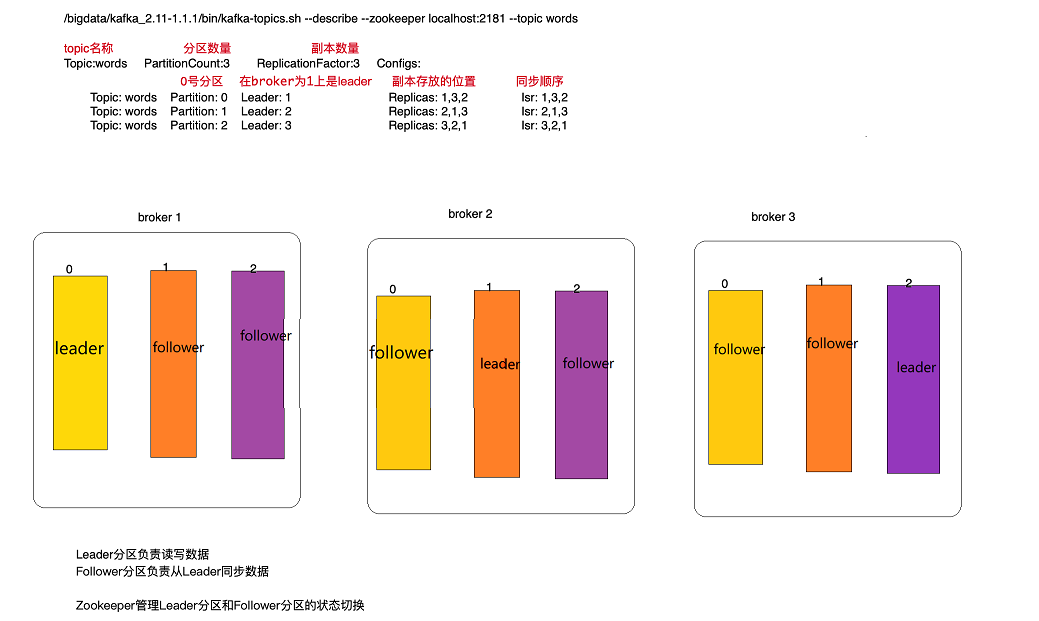
(7) 查看某个topic的偏移量
/usr/apps/kafka_2.11-1.1.1/bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server feng05:9092,feng06:9092,feng07:9092 --formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
5.kafka java客户端
前提:导入kafka的依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.1</version> </dependency>
5.1 生产者


package cn._51doit.kafka.clients import java.util.{Properties, UUID} import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} import org.apache.kafka.common.serialization.StringSerializer object ProducerDemo { def main(args: Array[String]): Unit = { // 1 配置参数 val props = new Properties() // 连接kafka节点 props.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092") //指定key序列化方式 props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") //指定value序列化方式 props.setProperty("value.serializer", classOf[StringSerializer].getName) // 两种写法都行 val topic = "wordcount" // 2 kafka的生产者 val producer: KafkaProducer[String, String] = new KafkaProducer[String, String](props) for (i <- 41 to 50) { // 3 封装的对象 //将数据发送到指定的分区编号 //val record = new ProducerRecord[String, String](topic, 1 , "abc","myvalue:"+i) //val partitionNum = i % 4 // 指定数据均匀写入4个分区中 //val record = new ProducerRecord[String, String](topic, partitionNum, null,"myvalue:"+i) //不指定分区编号,指定key, 分区编号 = key.hasacode % 4 //val record = new ProducerRecord[String, String](topic , "abc","myvalue:"+i) //根据key的hashcode值模除以topic分区的数量,返回一个分区编号 //val record = new ProducerRecord[String, String](topic , UUID.randomUUID().toString ,"myvalue:"+i) //没有指定Key和分区,默认的策略就是轮询,将数据均匀写入多个分区中 val record = new ProducerRecord[String, String](topic,"value-" + i) // 4 发送消息 producer.send(record) } println("message send success") // 释放资源 producer.close() } }
5.2 消费者
package cn._51doit.kafka.clients import java.util import java.util.Properties import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer} import org.apache.kafka.common.serialization.StringDeserializer object ConsumerDemo { def main(args: Array[String]): Unit = { // 1 配置参数 val props = new Properties() //从哪些broker消费数据 props.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092") // 反序列化的参数 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") props.setProperty("value.deserializer",classOf[StringDeserializer].getName) // 指定group.id props.setProperty("group.id","g101") // 指定消费的offset从哪里开始 //earliest:从头开始 --from-beginning //latest:从消费者启动之后 props.setProperty("auto.offset.reset","earliest") //[latest, earliest, none] // 是否自动提交偏移量 offset // enable.auto.commit 默认值就是true【5秒钟更新一次】,消费者定期会更新偏移量 groupid,topic,parition -> offset // props.setProperty("enable.auto.commit","false") // kafka自动维护偏移量 手动维护偏移量 //enable.auto.commit 5000 // 2 消费者的实例对象 val consumer: KafkaConsumer[String, String] = new KafkaConsumer[String, String](props) // 订阅 参数类型 java的集合 val topic: util.List[String] = java.util.Arrays.asList("wordcount") // 3 订阅主题 consumer.subscribe(topic) while (true){ // 4 拉取数据 val msgs: ConsumerRecords[String, String] = consumer.poll(2000) import scala.collection.JavaConversions._ for(cr <- msgs){ // ConsumerRecord[String, String] println(cr) } } //consumer.close() } }