简述
分而治之:一个分布式运算程序的编程框架。分析数据
将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个集群上
Mapreduce分为两个阶段:
-
-
Map阶段并发MapTask,完全并行运行互不相干
-
-
Reduce负责合,对map阶段的结果进行全局汇总
-
Reduce阶段的并发ReduceTask,完全互不相干,但是它们的数据依赖于上一个阶段的所有MapTask并发实例的输出
-
-
MapReduce编程模型只能包含一个Map和一个Reduce阶段。业务复杂则多个MapReduce程序串行运行
-
MapReduce运行在Yarn集群上
-
ResourceManager
-
Mapreduce工作流程:
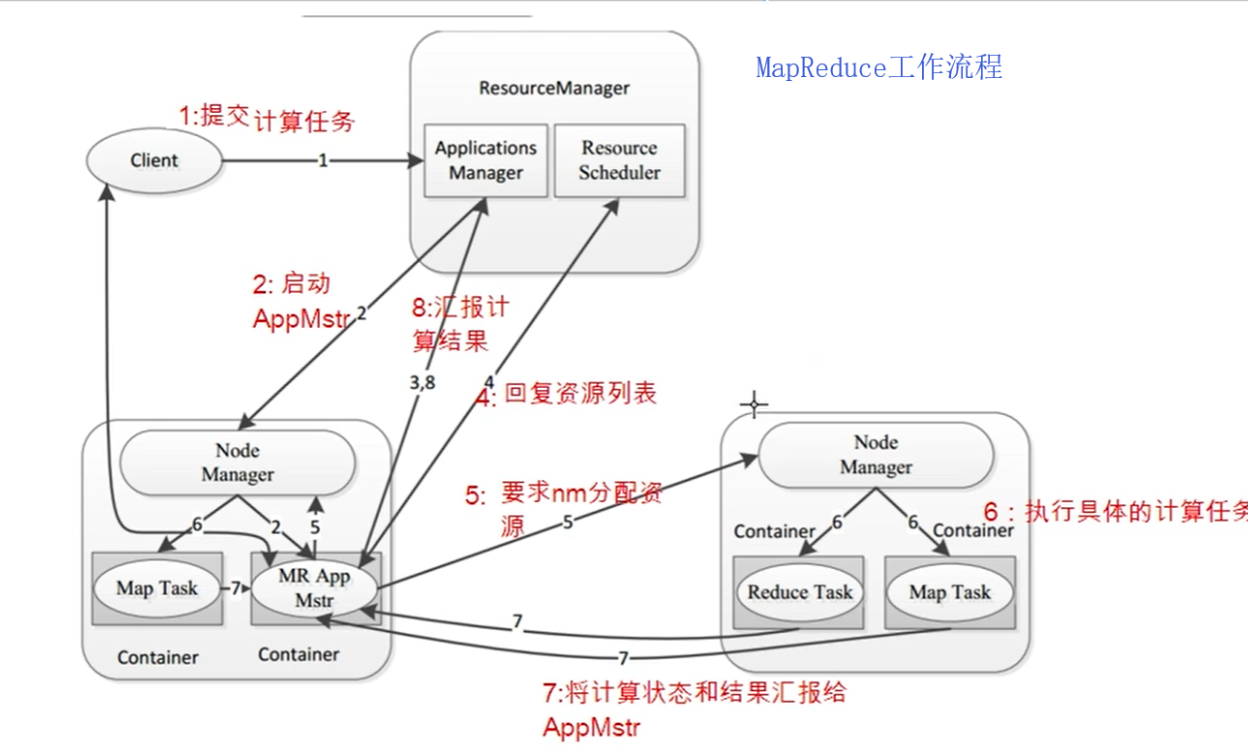
MRAppMaster:负责整个程序的过程调度及状态协调
MapTask:负责map阶段的整个数据处理流程
ReduceTask:负责reduce阶段的整个数据处理流程
MapReduce的优缺点:
优点:
-
-
良好的扩展性,增加机器来扩展计算能力
-
高容错性,副本机制
-
适合PB级以上大量数据的
-
-
不擅长流式计算(MapReduce输入数据集是静态的,不能动态变化)
-
MapReduce的各个阶段概述:
1.Map阶段:
-
-
-
对不同的数据按照相同的Key排序
-
对分组的数据初步规约,降低数据的网络拷贝
-
对数据进行分组
-
3.Reduce阶段:
在编写MR程序的时候,分为Mapper和Reducer,还有驱动类Driver:
1. Mapper:
-
-
Mapper的输入数据是KV对的形式(KV类型可自行定义)
-
Mapper中的业务逻辑写在map方法中
-
Mapper的输出数据是KV对的形式(KV类型可自行定义)
-
map()方法
-
package hch.wordCount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 注意:pom.xml中要添加一个 <packaging>jar</packaging> * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * 四个泛型: K1 V1 K2 V2 类型 * @author Joey413 */ public class WordCountMapper extends Mapper<LongWritable , Text , Text , LongWritable> { /** * map方法就是将K1和V1转为K2和V2 * 参数: * key K1 行偏移量 * value V1 每一行的文本数据 * context 表示上下文数据 * */ @Override public void map(LongWritable key,Text value, Context context) throws IOException, InterruptedException { // 将一行文本数据进行拆分 String line = value.toString(); String[] split = line.split(","); // 遍历数组,组装K2和V2 for (String word : split) { // 将K2和V2写入上下文中 context.write(new Text(word), new LongWritable(1)); } } }
- Reducer:
-
-
Reducer的输入数据类型对应的Mapper的输出数据类型,也是KV
-
Reducer中的业务逻辑写在Reduce()方法中
-
-
package hch.wordCount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * 四个泛型: K2 V2 K3 V3 * @author Joey413 */ public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { /** * 自定义reduce逻辑: 将新的K2和V2转为K3和V3,并将3和V3写入上下文中 * 所有的key都是我们的单词,所有的values都是我们单词出现的次数 * @param key 新的K2 * @param values 集合 新V2 * @param context 上下文对象 * @throws IOException * @throws InterruptedException * */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { // 1、遍历集合,将集合的数字相加 得到V3 // 2、将K3和V3写入上写文中 long count = 0; for(LongWritable value : values){ count += value.get(); } context.write(key,new LongWritable(count)); } }
- Driver: 相当于YARN集群的客户端,用于提交整个程序到YARN集群, 提交的是封装了MapReduce程序 相关运行参数的job对象
package hch.wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @author Joey413 */ public class JobMain extends Configured implements Tool { /** * 该方法用于指定一个Job任务 * */ @Override public int run(String[] strings) throws Exception { // 1、创建一个Job任务对象 Job job = Job.getInstance(super.getConf(), "WordCount"); // 2、配置Job任务对象 // 第一步:指定文件的读取方式和读取路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://192.168.199.3:8020/wordcount")); // 第二步:指定Map处理方式和数据类型 job.setMapperClass(WordCountMapper.class); // 设置Map阶段K2的类型 job.setMapOutputKeyClass(Text.class); // 设置Map阶段V2的类型 job.setMapOutputValueClass(LongWritable.class); // 第三、四、五、六步:默认方式 // 第七步:指定Reduce阶段的处理方式和数据类型 job.setReducerClass(WordCountReducer.class); // 设置K3的类型 job.setOutputKeyClass(Text.class); // 设置V3的类型 job.setOutputValueClass(LongWritable.class); // 第八步:设置输出类型 job.setOutputFormatClass(TextOutputFormat.class); // 设置输出路径 TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.199.3:8020/wordcount_out")); // 等待任务结束 boolean b = job.waitForCompletion(true); /** // waitForCompletion 这个方法内包含了submit方法 public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException { if (state == JobState.DEFINE) { submit(); }.... */ return b ? 0:1; } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); // 启动Job任务 int run = ToolRunner.run(configuration, new JobMain(), args); System.exit(run); } }