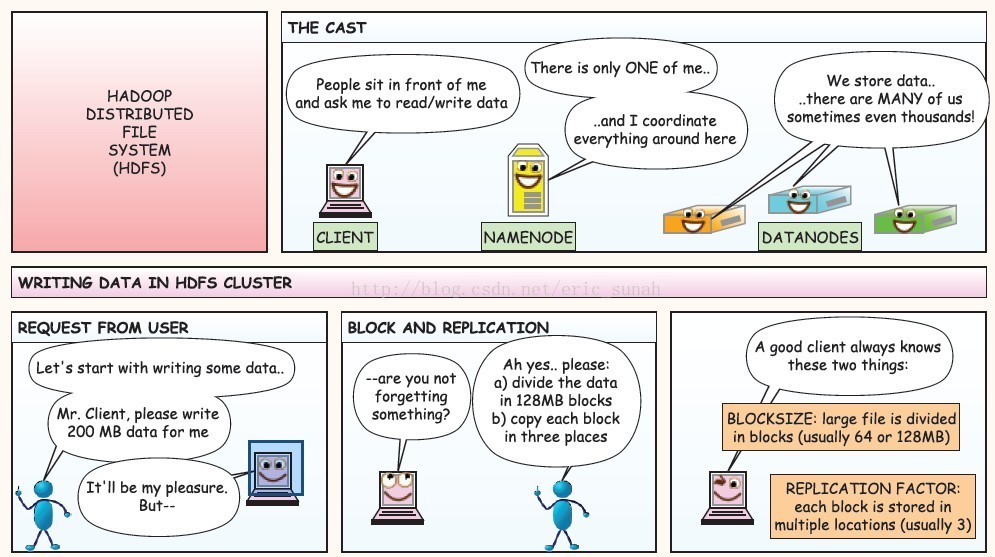
hadoop文件分布式系统(hdfs)
client:人们坐在我面前,请求我去读写数据
namenode:我只有一个,我来指挥这里所有的事情
datanode:我们存储数据,我们很多人,有时候会有几千人
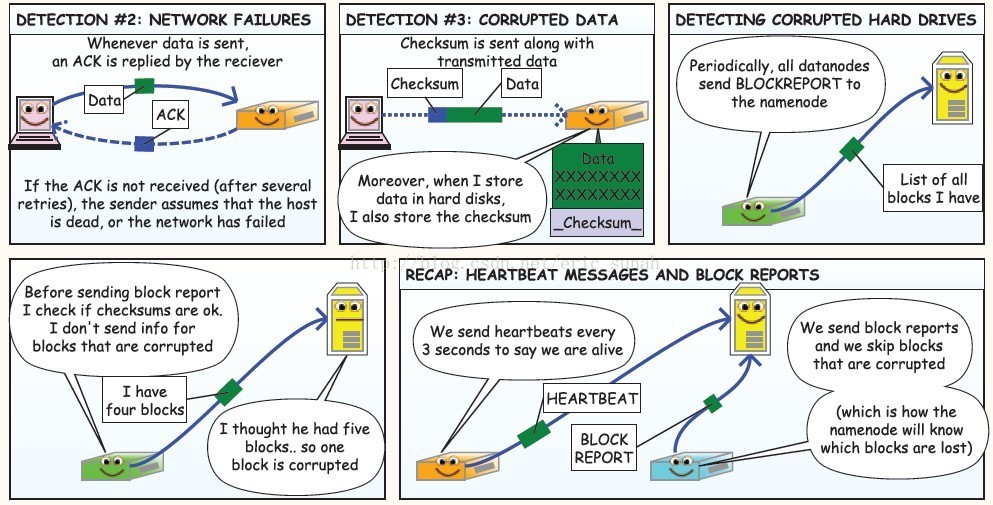
在HDFS集群中写入操作
①用户请求: “ 用户:‘让我们写一些数据吧,client先生,请给我写入200M的数据’;client:‘这是我的荣幸,但是。。。’。”
②块和复制: “client:‘你没有忘记什么东西吧?’;用户:‘噢,对了。。请帮我把数据分为128M一个包,每个包复制到三个地方;”
③一个优秀的客户端总是知道这两件事情:blocksize:大的文件分为许多的包(通常包的大小为64或者128Mb)replication factor:每一个包被复制存储在多个地方(一般是三个)
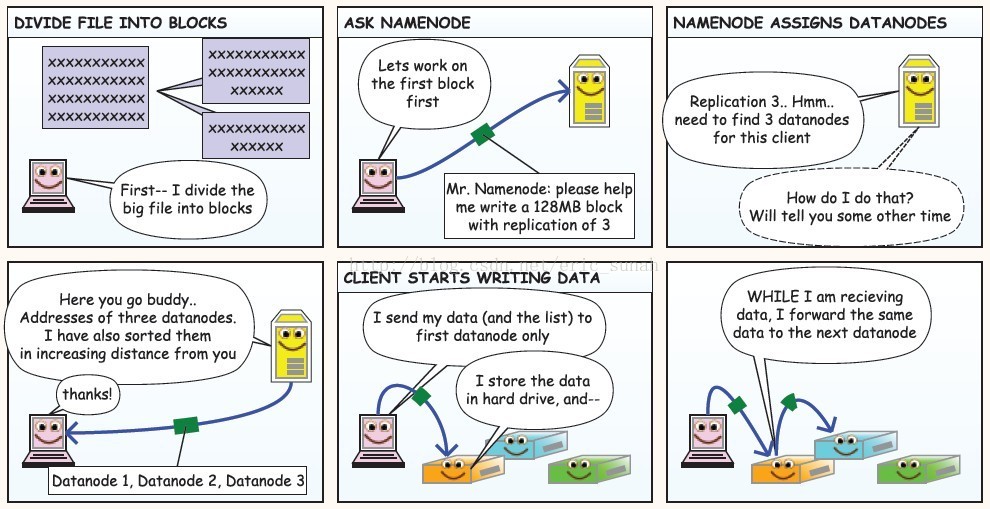
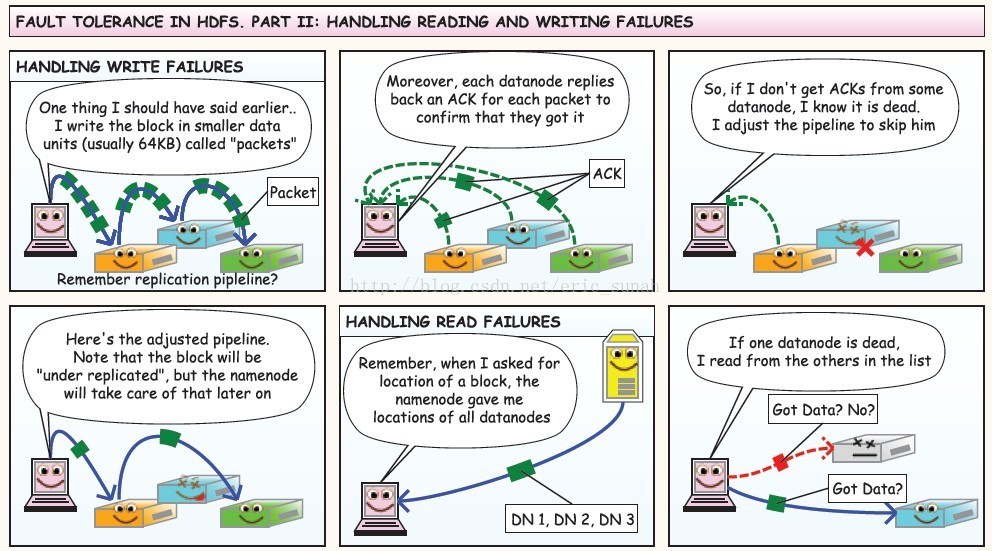
①分解文件为包:client:首先我会把这个大的文件分解为许多包
②请求namenode:client:首先让我们为第一个包开始工作吧,namenode先生,请帮我写一个128Mb的包复制三份
③namenode分配datanodes:namenode:复制三份,hmm。。。需要找三个datanode给这个client,该怎样做呢,改天再告诉你
④namenode:给你,伙计。。这是三个datanode的地址,我已经帮你从近到远排好序了;client:谢谢。
⑤client开始写数据:client:我只发送我的数据(这是清单)给第一个datanode;datanode1:我会将数据存储在硬盘里。
⑥datanode1:当我收到数据时,我将相同的数据同时发给下一个datanode
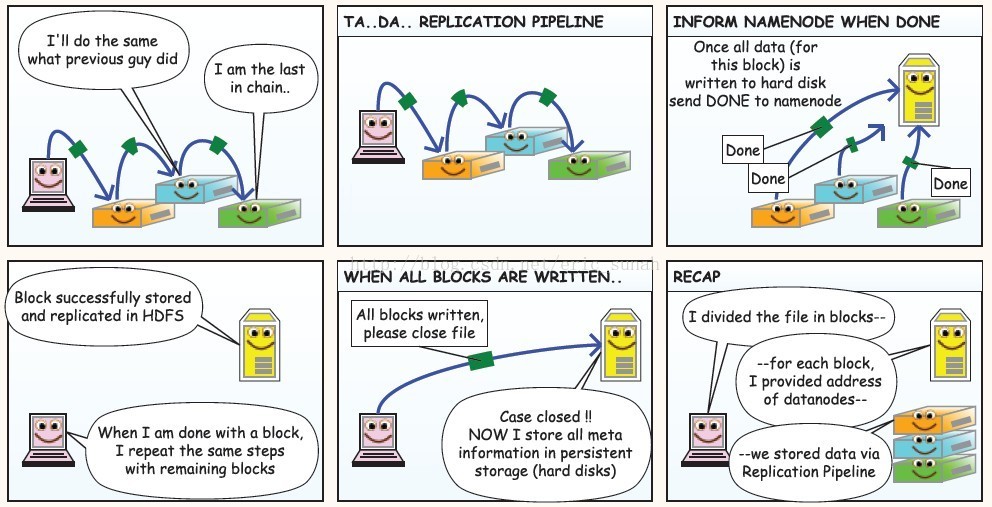
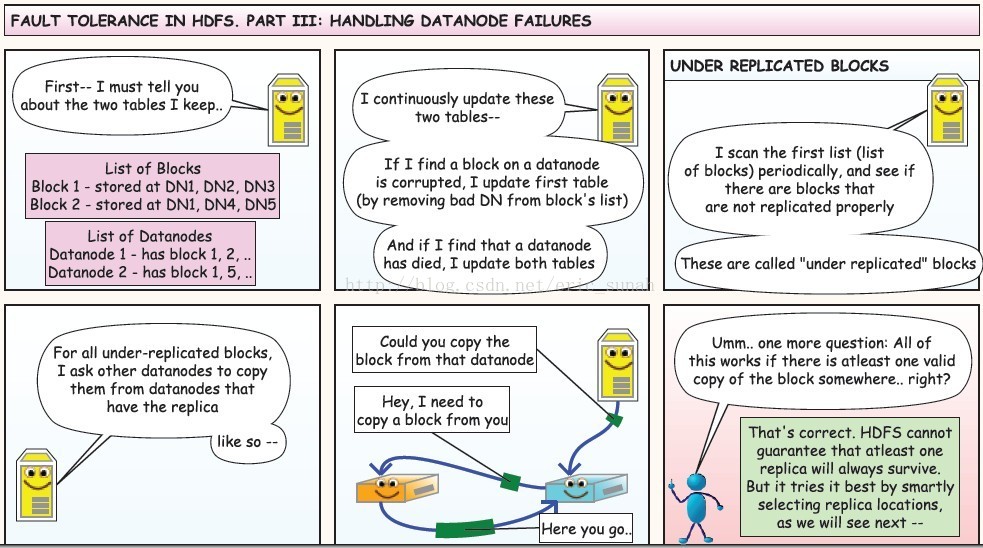
①datanode2:我要和刚才那个人一样的做;datanode3:我是最后一个节点
②TA..DA..复制 运输
③当datanode运输完成时:当所有数据(这个包)被写入硬盘,所有的datanode发送报告给namenode
④namenode:包已经成功存储和复制在hdfs中了;client:当我传输完一个包时,我重复相同的步骤来传输剩余的包
⑤当所有包传输完毕:client:当所有包传输完毕,请关闭文件。namenode:关闭情况下,现在我将所有的元信息存储在硬盘上
⑥回顾:client:我将文件分为包;namenode:对于每个包我分配了datanode的地址;datanode:我复制了几份存储了数据