一、引入背景(Why)
1. 在多线程环境下,HashMap的put会导致扩容,扩容引起死循环,导致CPU使用率100%
2. 可以使用HashTable和Collections.synchronizedMap(hashMap)可以解决多线程的问题
3. HashTable和Collections.synchronizedMap(hashMap)对读写进行加一个全局锁,一个线程读写map的元素,其余线程必须等待,性能不好
4. ConcurrentHashMap也加了锁,但是只锁了map的一部分,其余线程可以继续读写没锁住的部分,优化了操作性能
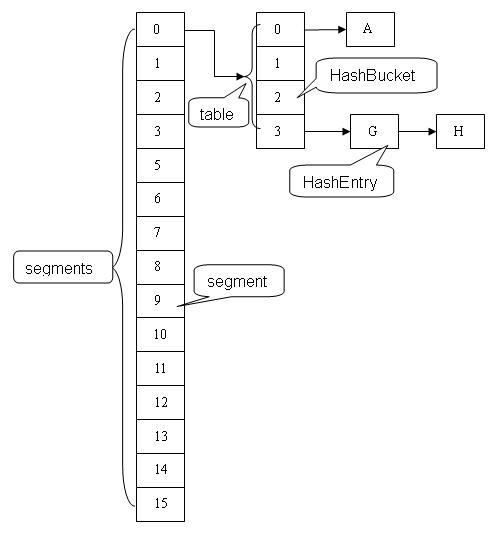
二、JDK1.7的实现(了解):Segment分段锁+HashEntry+ReentrantLock
1. HashEntry是键值对,用来存储数据
2. 桶是由若干个HashEntry连接起来的链表
3. Segment分段锁继承ReentrantLock,每个Segment对象锁住若干个桶
4. 一个ConcurrentHashMap实例中,包含由若干个Segment对象组成的数组
5. HashEntry->HashBucket->Segment->ConcurrentHashMap,一层一层被包含
三、JDK1.8的实现(理解):Node+CAS+Synchronized,锁的粒度更小
1. 数据结构:抛弃了臃肿的Segment分段锁机制,采用CAS+Synchronized来保证并发更新的安全,底层依然是数组+链表+红黑树的存储结构
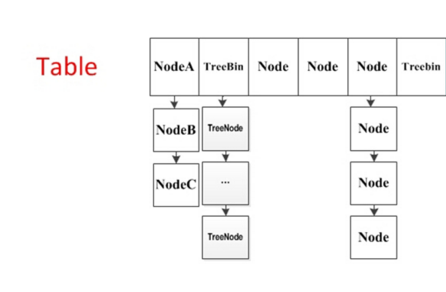
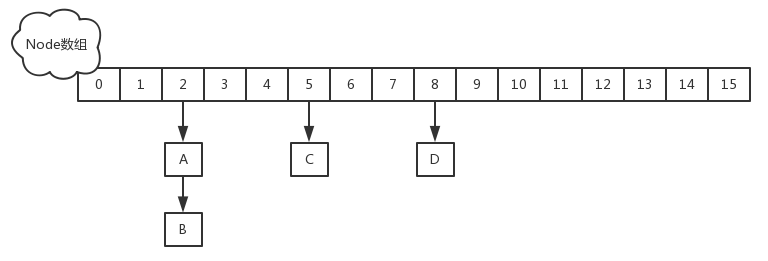
2. table,默认为16大小的数组,第一次put值才会初始化
3. Node,保存key-value,hash值和下一个node地址
class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; //volatile保证并发的可见性 volatile Node<K,V> next; //volatile保证并发的可见性
}
4. put实现,采用CAS+Synchronized实现并发插入或者更新,当链表长度大于8,会把链表转为红黑树
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); ...省略部分代码 } addCount(1L, binCount); return null; }
5. size实现:使用一个volatile类型的变量baseCount记录元素个数,通过addCount()更新
6. 扩容,数组使用volatile修饰,表示数组的地址是volatile,而不是表示数据元素是volatile,在扩容的时候,对其他线程保持可见性
7. get操作,源码没有加锁,因为Node的值和指针,使用volatile修饰的
8. JDK1.8的ConcurrentHashMap存在bug,会进入死循环,1.9修复了
四、红黑树的实现分析
1. 红黑树是一种特殊的二叉树
2. 主要用来存储有序的数据
3. 可以高效检索,时间复杂度为O(lgn)
参考:
https://www.jianshu.com/p/c0642afe03e0
https://www.jianshu.com/p/f6730d5784ad