Quartz 是开源任务调度框架中的翘楚,它提供了强大的任务调度机制。Quartz 允许开发人员灵活地定义触发器的调度时间表,并可对触发器和任务进行关联映射。此外,Quartz 提供了调度运行环境的持久化机制,可以保存并恢复调度现场,即使系统因故障关闭,任务调度现场数据也不会丢失。此外,Quartz 还提供了组件式的侦听器、各种插件、线程池等功能。
1.Quartz 基础结构
Quartz 对任务调度的领域问题进行了高度抽象,提出了调度器、任务和触发器这3个核心的概念,并在 org.quartz 中通过接口和类对核心概念进行了描述。
(1)Job:是一个接口,只有一个方法 void execute(JobExecutionContext context),开发者通过实现该接口来定义需要执行的任务,JobExecutionContext 类提供了调度上下文的各种信息。Job 运行时的信息保存在 JobDataMap 实例中。
(2)JobDetail:Quartz 在每次执行 Job 时,都重新创建一个 Job 实例,所以它不是直接接收一个 Job 实例,而是接收一个 Job 实现类,以便运行时通过 new Instance() 的反射调用机制实例化 Job。因此需要通过一个类来描述 Job 的实现类及其他相关的静态信息,如 Job 名称、描述、关联监听器等信息,而 JobDetail 承担了这一角色。通过该类的构造函数 JobDetail(java.lang.String name,java.lang.String group,java.lang.Class jobClass),可以更具体地了解它的功用。该构造函数要求指定 Job 的实现类,以及任务在 Scheduler 中的组名和 Job 名称。
(3)Trigger:是一个类,描述触发 Job 执行的时间触发规则。主要有 SimpleTrigger 和 CronTrigger 这两个子类。当仅需要触发一次或者以固定间隔周期性执行时,SimpleTrigger 是最适合的选择:而 CronTrigger 则可以通过 Cron 表达式定义出各种复杂的调度方案,如每天早晨 9:00 执行,每周一、周三、周五下午 5:00 执行等。
(4)Calendar:org.quartz.Calendar 和 java.util.Calendar 不同,它是一些日历特定时间点的集合(可以简单地将 org.quartz.Calendar 看作 java.util.Calendar 的集合—— java.util.calendar 代表一个日历时间点,若无特殊说明,后面的 Calendar 即指 org.quartz.Calendar )。一个 Trigger 可以和多个 Calendar 关联,以便排除或包含某些时间点。假设安排每周一早晨 10:00 执行任务,但是如果遇到法定节假日,则不执行任务,这时就需要在 Trigger 触发机制的基础上使用 Calendar 进行定点排除。针对不同的时间段类型,Quartz 在org.quartz.impl.calendar 包下提供了若干个 Calendar 的实现类,如 AnnualCalendar、MonthlyCalendar、WeeklyCalendar 分别针对每年、每月和每周进行定义。
(5)Scheduler:代表一个 Quartz 的独立运行容器,Trigger 和 JobDetail 可以注册到 Scheduler 中,二者在 Scheduler 中拥有各自的组及名称。组及名称是 Scheduler 查找定位容器中某一对象的依据,Trigger 的组及名称的组合必须唯一,JobDetail 的组及名称的组合也必须唯一(但可以和 Trigger 的组及名称相同,因为它们是不同类型的,处在不同的集合中)。Scheduler 定义了多个接口方法,允许外部通过组及名称访问和控制容器中的 Trigger和 JobDetail。Scheduler 可以将 Trigger 绑定到某一 JobDetail 中,这样,当被触发时,对应的 Job 就被执行。一个 Job 可以对应多个 Trigger,但一个 Trigger 只能对应一个Job。可以通过 SchedulerFactory 创建一个 Scheduler 实例。Scheduler 拥有一个 SchedulerContext,保存着 Scheduler 上下文信息,可以对照 ServleContext 来理解 SchedulerContext。Job 和 Trigger 都可以访问 SchedulerContext 内的信息。SchedulerContext 内部通过一个Map,以键值对的方式维护这些上下文数据。SchedulerContext 为保存和获取数据提供了多个 put() 和 getxxx() 方法。可以通过 Scheduler#getContext() 方法获取对应的 SchedulerContext 实例。
(6)ThreadPool:Scheduler 使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程来提高运行效率。
Job 有一个 StatefulJob 子接口,代表有状态的任务。该接口是一个没有方法的标签接口,其目的是让 Quartz 知道任务的类型,以便采用不同的执行方案。无状态任务在执行时拥有自己的 JobDataMap 复制,对 JobDataMap 的更改不会影响下次的执行。而有状态任务共享同一个 JobDataMap 实例,每次任务执行对 JobDataMap 所做的更改会保存下来,后面的执行可以看到这个更改,即每次执行任务后都会对后面的执行产生影响。
正因为这个原因,无状态的 Job 可以并发执行,而有状态的 StatefulJob 不能并发执行。这意味着如果前次的 StatefulJob 还没有执行完毕,则下次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往更复杂,因此,除非必要,应尽量避免使用有状态的 Job。
如果 Quartz 使用了数据库持久化任务调度信息,则无状态的 JobDataMap 仅会在 Scheduler 注册任务时保存一次,而有状态任务对应的 JobDataMap 在每次执行任务后都会进行保存。
Trigger 自身也可以拥有一个 JobDataMap,其关联的 JobDataMap 可以通过 JobExecutionContext#getTrigger().getJobDataMap() 方法获取。不管是有状态还是无状态的任务,在任务执行期间对 Trigger 的 JobDataMap 所做的更改都不会进行持久化,即不会对下次任务的执行产生影响。
Quartz 拥有完善的事件和监听体系,大部分组件都拥有事件,如任务执行前事件、任务执行后事件、触发器触发前事件、触发器触发后事件、调度器开始事件、调度器关闭事件等,可以注册相应的监听器处理感兴趣的事件。
下图描述了 Scheduler 的内部组件结构。SchedulerContext 提供 Scheduler 全局可见的上下文信息,每个任务都对应一个 JobDataMap,虚线框中的 JobDataMap 表示有状态的任务。
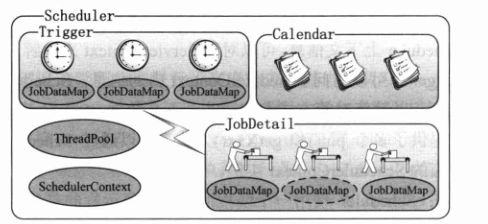
一个 Scheduler 可以拥有多个 Trigger 和多个 JobDetail,它们可以分到不同的组中。在注册 Trigger 和 JobDetail 时,如果不显式指定所属的组,那么 Scheduler 将放入默认组中,默认组的组名为 Scheduler.DEFAULT_GROUP。组名和名称组成了对象的全名,同一类型对象(Job 或 Trigger)的全名不能相同。
Scheduler 本身就是一个容器,它维护着 Quartz 的各种组件并实施调度的规则。Scheduler 还拥有一个线程池,线程池为任务提供执行线程。这比执行任务时简单地创建一个新线程要拥有更高的效率,同时通过共享机制可以减少资源的占用。基于线程池组件的支持,对于繁忙度高、压力大的任务调度,Quartz 可以提供良好的伸缩性。
提示:Quartz 完整下载包 examples 目录下拥有 10 多个实例,它们是快速掌握 Quartz 应用很好的实例。
2.使用SimpleTrigger
SimpleTrigger拥有多个重载的构造函数,用于在不同场合下构造出对应的实例。
(1)SimpleTrigger(String name,String group):通过该构造函数指定Trigger所属组和名称。
(2)SimpleTrigger(String name,String group,Date startTime):除指定 Trigger 所属组和名称外,还可以指定触发的开始时间。
(3)SimpleTrigger(String name,String group,Date startTime,Date endTime,int repeatCount,long repeatlnterval):除指定以上信息外,还可以指定结束时间、重复执行次数、时间间隔等参数。
(4)SimpleTrigger(String name,String group,String jobName,String jobGroup, Date startTime,Date endTime,int repeatCount,long repeatlnterval):这是最复杂的一个构造函数,在指定触发参数的同时,通过 jobGroup 和 jobName,使该 Trigger 和 Scheduler 中的某个任务关联起来。
通过实现 org.quartz.Job 接口,可以使 Java 类化身为可调度的任务。如下面代码:
public class SimpleJob implements Job { public void execute(JobExecutionContext jobCtx) throws JobExecutionException {//实现Job接口方法 System.out.println(jobCtx.getTrigger().getName() + " triggered. time is:" + (new Date())); } }
这个演示类的 execute(JobExecutionContext context) 方法只有一条简单的输出语句,可以在这个方法中包含任何想要执行的代码。下面通过 SimpleTrigger 对 SimpleJob 进行调度,如下面代码所示。
package com.smart.basic.quartz; import java.util.Date; import org.quartz.JobDetail; import org.quartz.Scheduler; import org.quartz.SchedulerFactory; import org.quartz.SimpleTrigger; import org.quartz.impl.StdSchedulerFactory; public class SimpleTriggerRunner { public static void main(String args[]) { try { JobDetail jobDetail = new JobDetail("job1_1", "jgroup1", SimpleJob.class);//①创建一个JobDetail实例,指定SimpleJob SimpleTrigger simpleTrigger = new SimpleTrigger("trigger1_1", "tgroup1");//②通过SimpleTrigger定义调度规则:马上启动,每2秒运行一次,共运行100次 simpleTrigger.setStartTime(new Date()); simpleTrigger.setRepeatInterval(2000); simpleTrigger.setRepeatCount(100); SchedulerFactory schedulerFactory = new StdSchedulerFactory();//③通过SchedulerFactory获取一个调度器实例 Scheduler scheduler = schedulerFactory.getScheduler(); scheduler.scheduleJob(jobDetail, simpleTrigger);//④注册并进行调度 scheduler.start();//⑤启动调度 } catch (Exception e) { e.printStackTrace(); } } }
首先在①处通过 JobDetail 封装 simpleJob,同时指定 Job 在 Scheduler 中的所属组及名称。在这里,组名为 jgroup1,而名称为 job1_1。
然后在②处创建一个 SimpleTrigger 实例,指定该 Trigger 在 Scheduler 中的所属组及名称。接着设置调度的时间规则。
最后创建 Scheduler 实例,并将 JobDetail 和 Trigger 实例注册到 Scheduler 中。在这里,通过 SchedulerFactory 获取一个 Scheduler 实例,并通过 scheduleJob(JobDetaiI jobDetail, Trigger trigger)完成两件事。
(1)将 JobDetaiI 和 Trigger 注册到 Scheduler 中。
(2)用 Trigger 对 JobDetail 中的任务进行调度。
在 Scheduler 启动后,Trigger 将定期触发并执行 SimpleJob 的 execute(JobExecutionContext jobCtx)方法,每10秒重复一次,直到任务被执行 100 次。
还可以通过 SimpleTrigger 的 setStartTime(java.util.Date startTime) 和 setEndTime(java.util.Date endTime) 方法指定运行的时间范围。当运行次数和时间范围产生冲突时,超过时间范围的任务不被执行。如可以通过simpleTrigger.setStartTime(new Date(System.CurrentTimeMillis()+60000L))方法指定 60 秒后开始运行。
除了通过 scheduleJob(jobDetail, simpleTrigger) 方法建立 Trigger 和 JobDetail 的关联外,还可以通过如下方式建立关联:
JobDetail jobDetail = new JobDetail("job1_1","jgroup1",SimpleJob.class); SimpleTrigger simpleTrigger = new SimpleTrigger("trigger1_1", "tgroupl"); ... simpleTrigger.setJobGroup("jgroupl");//①-1指定关联的Job组名 simpleTrigger.setJobName("job1_1");//①-2指定关联的Job名称 scheduler.addJob(jobDetail,true);//②注册JobDetail scheduler.scheduleJob(simpleTrigger);//③注册指定了关联JobDetail的Trigger
在这种方式中,Trigger 通过指定 Job 所属组及 Job 名称,使用 Scheduler 的 scheduleJob(Trigger trigger)方法注册 Trigger。在这里,有两个值得注意的地方。
(1)通过这种方式注册的 Trigger 必须已经指定了 Job 组名和 Job 名称,否则调用 scheduleJob(simpleTrigger)方法将抛出异常。
(2)引用的 JobDetail 对象必须已经存在于 scheduler 中,即代码中①、②和③的顺序不能随意变动。
实战经验:在构造 Trigger 实例时,可以考虑使用 org.quartz.TriggerUtils 工具类,该工具类不但提供了众多获取特定时间的方法,还拥有多个获取常见 Trigger 的方法。如 makeSecondlyTrigger(String trigName) 方法将创建一个每秒执行一次的 Trigger,makeWeeklyTrigger(String trigName, int dayOfWeek, int hour, int minute) 方法将创建一个每星期某一特定时间点执行一次的 Trigger,而 getEvenMinuteDate(Date date) 方法将返回某一时间点一分钟以后的时间。
3.使用CronTrigger
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于表达式。支持日历相关的周期时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。因此,相对于 SimpleTrigger 而言, CronTrigger 在使用上也要复杂一些。
1)Cron 表达式
Quartz 使用类似于 Linux 下的 cron 表达式定义时间规则。cron 表达式由 6 或 7 个空格分隔的时间字段组成,如下表所示。
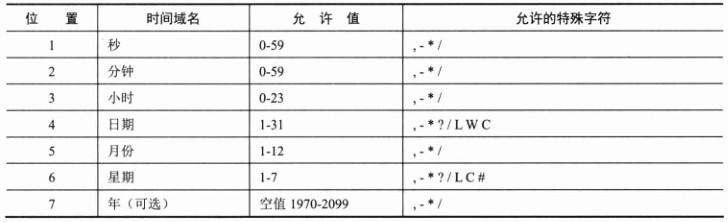
cron 表达式的时间字段除允许设置数值外,还可以使用一些特殊的字符,提供列表、范围、通配符等功能,详细介绍如下。
(1)星号(*):可用在所有字段中,表示对应时间域的每一个时刻。例如,*在分钟字段时,表示“每分钟”。
(2)问号(?):该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于占位符。
(3)减号(-):表达一个范围。如在小时字段中使用“10-12”,则表示从10点到12点,即10,11,12。
(4)逗号(,):表示一个列表值。如在星期字段中使用"MON,WED,FRI”,则表示星期一、星期三和星期五。
(5)斜杠(/):x/y表达一个等步长序列,x为起始值,Y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒;而5/15在分钟字段中表示5,20,35,50。用户也可以使用 */y,它等同于0/y。
(6)L:该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中的意思不同。如果 L 用在日期字段中,则表示这个月份的最后一天,如1月31日,非闰年2月28日;如果 L 用在星期字段中,则表示星期六,等同于 7(注意,这里的规则是星期六为一星期的最后一天)。但是,如果 L 出现在星期字段里,而且前面有一个数字 N,则表示“这个月的最后N天”。例如,6L 表示该月的最后一个星期五。
(7)W:该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如,15W 表示离该月15日最近的工作日,如果该月15日是星期六,则匹配 14 日星期五:如果15日是星期日,则匹配 16 日星期一:如果15日是星期二,那结果就是15日星期二。但必须注意关联的匹配日期不能跨月,如用户指定1W,如果1日是星期六,结果匹配的是3日星期一,而非上个月最后一天。W字符串只能指定单一日期,而不能指定日期范围。
(8)LW组合:在日期字段中可以组合使用LW,它的意思是当月的最后一个工作日。
(9)井号(#):该字符只能在星期字段中使用,表示当月的某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三。假设当月没有第五个星期三,则忽略不触发。
(10)C:该字符只在日期和星期字段中使用,代表“Calendar”的意思。它的意思是计划所关联的日期,如果日期没有被关联,则相当于日历中的所有日期。例如,5C在日期字段中相当于5日以后的那一天,1c在星期字段中相当于星期日后的第一天。
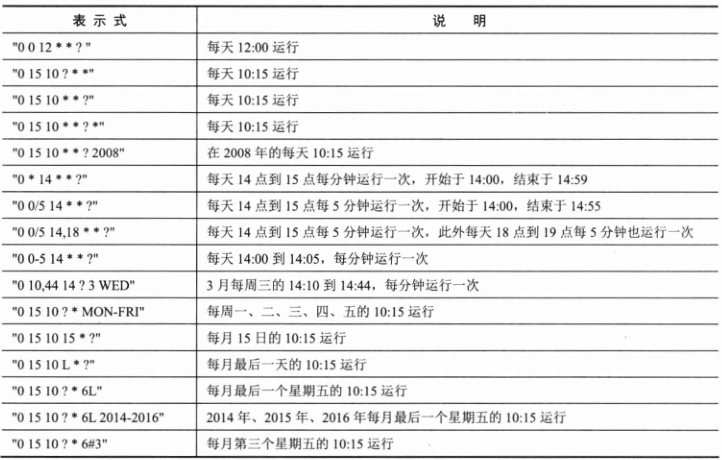
Cron 表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。下表给出了一些完整的 Cron 表示式示例。
2)CronTrigger 实例
下面使用 CronTrigger 对 SimpleJob 进行调度,通过 Cron 表达式制定调度规则,让它每5秒运行一次,如下面代码所示。
package com.smart.basic.quartz; import org.quartz.CronExpression; import org.quartz.CronTrigger; import org.quartz.JobDetail; import org.quartz.Scheduler; import org.quartz.SchedulerFactory; import org.quartz.impl.StdSchedulerFactory; public class CronTriggerRunner { public static void main(String args[]) { try { JobDetail jobDetail = new JobDetail("job1_2", "jgroup1", SimpleJob.class); CronTrigger cronTrigger = new CronTrigger("trigger1_2", "tgroup1");//①-1创建CronTrigger,指定组及名称 CronExpression cexp = new CronExpression("0/5 * * * * ?");//①-2定义Cron表达式 cronTrigger.setCronExpression(cexp);//①-3设置Cron表达式 SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler(); scheduler.scheduleJob(jobDetail, cronTrigger); scheduler.start(); //② } catch (Exception e) { e.printStackTrace(); } } }
运行 CronTriggerRunner,每5秒将触发 SimpleJob 运行一次。在默认情况下,Cron 表达式对应当前的时区,可以通过 CronTriggerRunner 的 setTimeZone(java.util.TimeZone timezone) 方法显式指定时区。用户也可以通过 setStartTime(java.util.Date startTime) 和 setEndTime(java.util.Date endTime)方法分别指定开始和结束时间。
实战经验:在上面代码②处需要通过 Thread.currentThread.sleep() 方法让主线程睡眠一段时间,使调度器可以继续执行任务调度的工作;否则在调度器启动后,因为主线程立即退出,寄生于主线程的调度器也将关闭,调度器中的任务都将相应销毁,这将导致看不到实际的运行效果。在单元测试的时候,使主线程睡眠一段时间以便让任务线程不被提前终止是经常使用的测试方法。对于测试某些长周期执行的调度任务,开发者可以简单地调整操作系统时间进行模拟。
4.使用Calendar
在实际任务调度中,不可能一成不变地按照某个特定周期调度任务,必须考虑到实现生活中日历上的特殊日期。
下面安排一个任务,每小时运行一次,并将五一劳动节和国庆节排除在外,如下面代码所示。
package com.smart.basic.quartz; import org.quartz.*; import org.quartz.impl.StdSchedulerFactory; import org.quartz.impl.calendar.AnnualCalendar; import java.util.Calendar; import java.util.Date; import java.util.GregorianCalendar; public class CalendarExample { public static void main(String[] args) throws Exception { SchedulerFactory sf = new StdSchedulerFactory(); Scheduler scheduler = sf.getScheduler(); AnnualCalendar holidays = new AnnualCalendar();//①法定节假日是以每年为周期的,所以使用AnnualCalendar //②五一劳动节 Calendar laborDay = new GregorianCalendar(); laborDay.add(Calendar.MONTH,5); laborDay.add(Calendar.DATE,1); //③国庆节 Calendar nationalDay = new GregorianCalendar(); nationalDay.add(Calendar.MONTH,10); nationalDay.add(Calendar.DATE,1); ArrayList<Calendar> calendars = new ArrayList<Calendar>(); calendars.add(laborDay); calendars.add(nationalDay); holidays.setDaysExcluded(calendars);//④排除这两个特殊日期 scheduler.addCalendar("holidays", holidays, false, false);//⑤向scheduler注册日历 //⑥从4月1号10am开始 Date runDate = TriggerUtils.getDateOf(0,0, 10, 1, 4); JobDetail job = new JobDetail("job1", "group1", SimpleJob.class); SimpleTrigger trigger = new SimpleTrigger("trigger1", "group1", runDate, null, SimpleTrigger.REPEAT_INDEFINITELY, 60L * 60L * 1000L); //⑦让Trigger遵守节日的规则(排除节日) trigger.setCalendarName("holidays"); scheduler.scheduleJob(job, trigger); scheduler.start(); try { // wait 30 seconds to show jobs Thread.sleep(30L * 1000L); // executing... } catch (Exception e) { } scheduler.shutdown(true); } }
由于节日是每年重复的,所以使用 org.quartz.Calendar 的 AnnualCalendar 实现类,通过②和③处的代码,指定五一劳动节和国庆节这两个节日,并通过 AnnualCalendar#setDaysExcluded(ArrayList days) 方法添加这两个日期。
在定制好 org.quartz.Calendar 后,还需要通过 Scheduler#addCalendar(String calName, Calendar calendar, boolean replace, boolean updateTriggers) 方法进行注册。如果 updateTriggers 为 true,则 Scheduler 中已引用 Calendar 的 Trigger 将得到更新,如④处所示。
在⑦处,让一个 Trigger 指定使用 Scheduler 中代表节日的 Calendar,这样 Trigger 就会避开五一劳动节和国庆节这两个特殊日子了。
5.任务调度信息存储
在默认情况下,Quartz 将任务调度的运行信息保存在内存中。这种方法提供了最佳的性能,因为在内存中数据访问速度最快;不足之处是缺乏数据的持久性,当程序中途停止或系统崩溃时,所有运行的信息都会丢失。比如希望安排一个执行100次的任务,如果执行到50次时系统崩溃了,那么系统重启时任务的执行计数器将从0开始计数。
在大多数实际应用中,往往并不需要保存任务调度的现场数据,因为很少需要规划一个指定执行次数的任务。对于仅执行一次的任务来说,其执行条件信息本身应该是已经持久化的业务数据(如对锁定到期的用户执行解锁的任务,锁定到期的时间点应该就是业务数据),当任务执行完成后,条件信息也会相应改变。当然,调度现场信息不仅包括运行次数,而且包括调度规则、JobDataMap 中的数据等。
如果确实需要持久化任务调度信息,则 Quartz 允许用户通过调整其属性文件,将这些信息保存到数据库中。在使用数据库保存了任务调度信息后,即使系统崩溃后重新启动,任务调度信息仍将得到恢复。如前面所说的例子,执行50次系统崩溃后重新运行,计数器将从51开始计数。使用数据库保存信息的任务称为持久化任务。
1)通过配置文件调整任务调度信息的保存策略
其实 Quartz JAR 文件的 org.quartz 包下就包含了一个 quartz.properties 属性配置文件,并提供了默认设置。如果需要调整默认配置,则可以在类路径下建立一个新的 quartz.properties 属性,它将自动被 Quartz 加载并覆盖默认的设置。
org.quartz.scheduler.instanceName = DefaultQuartzScheduler //①集群的配置,这里不使用集群
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExceptionInUserTransaction = false
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool //②配置调度器的线程池
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore //③配置任务调度现场数据保存机制
Quartz 的属性配置文件主要包括三方面的信息:
(1)集群信息。
(2)调度器线程池。
(3)任务调度现场数据的保存。
如果任务数目很大,则可以通过增大线程池获得更好的性能。在默认情况下,Quartz 采用 org.quartz.simpl.RAMJobStore 保存任务的现场数据,顾名思义,信息保存在 RAM 内存中,可以通过以下设置将任务调度现场数据保存到数据库中,如下面代码所示。
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.tablePrefix = QRTZ_ //①数据库表前缀
org.quartz.jobStore.dataSource = qzDS //②数据源名称
//③下面是定义数据源的具体属性
##Mysql
org.quartz.dataSource.qzDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.URL = jdbc:mysql://localhost:3309/sampledb
org.quartz.dataSource.qzDS.user = root
org.quartz.dataSource.qzDS.password = 1234
org.quartz.dataSource.qzDS.maxConnections = 30
#Oracle
#org.quartz.dataSource.qzDS.driver = oracle.jdbc.driver.OracleDriver
#org.quartz.dataSource.qzDS.URL = jdbc:oracle:thin:@localhost:1521:ora9i
#org.quartz.dataSource.qzDS.user = stamen
#org.quartz.dataSource.qzDS.password = abc
#org.quartz.dataSource.qzDS.maxConnections = 30
要将任务调度数据保存到数据库中,就必须使用 org.quartz.impl.jdbcjobstore.JobStoreTX 代替原来的org.quartz.simpl.RAMJobStore,并提供相应的数据库配置信息。首先在①处指定了Quartz数据库表的前缀,然后在②处定义了一个数据源,最后在③处具体定义这个数据源的连接信息。
用户必须事先在相应的数据库中创建 Quartz 的数据表(共8张),在 Quartz 的完整发布包的 docs/dbTables 目录下拥有对应不同数据库的 SQL 脚本。
2)查询数据库中的运行信息
任务的现场保存对于上层的 Quartz 程序来说是完全透明的,在src目录下编写一个如上面所示的 quartz.properties文件后,重新运行上面的程序,在数据库表中将看到对应的持久化信息。当调度程序运行过程中途停止后,任务调度的现场数据将记录在数据库表中,在系统重启时就可以在此基础上继续进行任务的调度,如下面代码所示。
package com.smart.basic.quartz; import org.quartz.Scheduler; import org.quartz.SchedulerFactory; import org.quartz.SimpleTrigger; import org.quartz.Trigger; import org.quartz.impl.StdSchedulerFactory; public class JDBCJobStoreRunner { public static void main(String args[]) { try { SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler(); String[] triggerGroups = scheduler.getTriggerGroupNames();//①获取调度器中所有的触发器组 for (int i = 0; i < triggerGroups.length; i++) {//②重新恢复在tgroup1组中名为trigger1_1的触发器的运行 String[] triggers = scheduler.getTriggerNames(triggerGroups[i]); for (int j = 0; j < triggers.length; j++) { Trigger tg = scheduler.getTrigger(triggers[j], triggerGroups[i]); if (tg instanceof SimpleTrigger && tg.getFullName().equals("tgroup1.trigger1_1")) {//②-1根据名称判断 // ((SimpleTrigger) tg).setRepeatCount(100); scheduler.rescheduleJob(triggers[j], triggerGroups[i],tg);//②-1恢复运行 } } } scheduler.start(); } catch (Exception e) { e.printStackTrace(); } } }
当之前代码中的 SimpleTriggerRunner 执行到一段时间后非正常退出,就可以通过 JDBCJobStoreRunner 根据记录在数据库中的现场数据恢复任务的调度。Scheduler 中的所有 Trigger 及 JobDetail 的运行信息都会保存在数据库中,这里仅恢复 tgroup1 组中名为 trigger1_1 的触发器,这可以通过如②-1所示的代码进行过滤,触发器采用 GROUP.TRIGGER_NAME 的全名格式。通过 Scheduler#rescheduleJob(String triggerName, String groupName, Trigger newTrigger) 方法即可重新调度关联某个 Trigger 的任务。