第二周。
1.Algorithm:每周至少做一个 leetcode 的算法题
2.Review:阅读并点评至少一篇英文技术文章
3.Tip:学习至少一个技术技巧
4.Share:分享一篇有观点和思考的技术文章
以下是各项的情况:
Algorithm
上周的有点问题 :
假如数组【3,2,4】给的数据是 6 ,按我之前的思路 直接从遍历去找当前遍历的数和所给数据和的差值,但如果从第一个数3走,那给出的答案就会是【0,0】而非期望的【1,2】。所以需要修改:
class Solution { public int[] twoSum(int[] nums, int target) { HashMap<Integer,Integer> map= new HashMap<Integer,Integer>(); int[] result = new int[2]; for(int i=0;i<nums.length;i++){ if(map.containsKey(target-nums[i])){ result[1]=i; result[0] = map.get(target-nums[i]); break; }else{ map.put(nums[i],i); } } return result; } }
思路 是 干脆就来两个指针 来指向和存 就不会出现指向同一个位置的了。
这周的链接 :[LeetCode-07]-Reverse Integer
Java:
class Solution { public int reverse(int x) { if(x == 0){ return x; }else{ int r = 0; while(x != 0){ if(r > 2147483647/10 || r < -2147483647/10) return 0; r = r*10 + x%10; x = x/10; } return r; } } }
Review
回顾
1. 内部存储器
JAVA 中 HashMap 类 是 Map <K,V> 接口的实现 。该接口的主要方法是:
- V put(K key, V value)
- V get(Object key)
- V remove(Object key)
- Boolean containsKey(Object key)
HashMaps用一个内部类来存储数据:Entry <K,V>。此 Entry 是一个带有两个额外数据的简单键值对:
-
- 对另一个 Entry 的引用,以便 HashMap 可以存储单个链接列表等条目
- 一个哈希值用来存 key 值。这个哈希值是用来存储该散列值,以避免每次使用 HashMap 需要重新计算散列。
以下是JAVA 7中Entry实现的一部分:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; … }
HashMap将数据存储到多个单链接的条目列表(也称为桶,buckets 或 目录 ,bins)中。所有列表都在 Entry(Entry <K,V> [] 数组)数组中注册,并且此内部数组的默认容量为16。
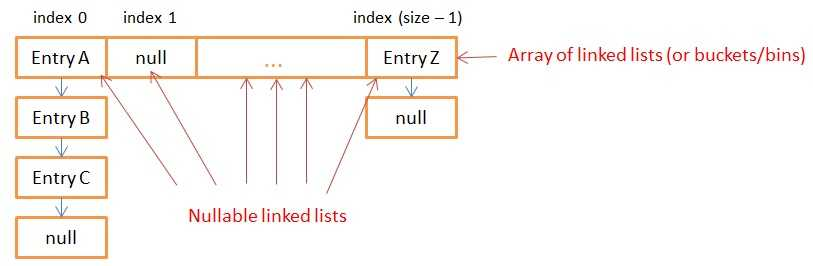
图显示了具有可为空条目数组的 HashMap 实例的内部存储。每个条目都可以链接到另一个条目以形成链接列表。
具有相同散列值的所有键都放在同一个链表(bucket)中。具有不同散列值的键可能最终出现在同一个 bucket 中。
当用户调用 put(K key,V value)或 get(Object key)方法时,该函数计算条目所在桶 (bucket)的索引。然后,函数遍历列表,寻找具有相同 key 的条目(使用 key 的 equals() 函数)。
对于 get()语句,函数返回与条目 Entry 关联的值(如果条目 Entry 存在)。
在put(K key,V value)语句中,如果条目 Entry 存在,则函数将用新值来替换原值,否则它将在单链接列表的头部创建新条目(来自参数中的键和值)。
bucket 的这个索引(链表)是由 Map 以3个步骤生成:
-
- 首先获取 key 的哈希码 hashcode。
- 重新散列 rehash 哈希码 , 以防止键的散列函数出错,因为键会将所有数据放在内部数组的相同索引(bucket)中
- 接受重新散列的哈希码,并用数组的长度(- 1)对其进行位掩码操作。此操作确保索引不能大于数组的大小。您可以将其视为用来计算优化的模数函数
2. 自动调整大小
创建HashMap时,可以使用以下构造函数指定初始大小和loadFactor:
public HashMap(int initialCapacity, float loadFactor)
如果未指定参数,则默认initialCapacity为16,默认loadFactor为0.75。initialCapacity表示链接列表的内部数组的大小。
每次使用 put(…) 在 Map 中添加新键/值时,函数都会检查是否需要增加内部数组的容量。为了做到这一点,map存储了2个数据:
-
- Map 的大小:它表示HashMap中的条目数。此值在每次添加或删除条目时更新。
- 阈值 : 它等于(内部数组的容量)* loadFactor,每次调整内部数组的大小后都会刷新它
在添加新条目之前,put(…)检查大小是否为>阈值,如果是,则重新创建一个大小为双倍的新数组。由于新数组的大小发生了变化,索引函数(它返回按位操作“hash(key)和(sizeOfArray-1)”)发生了变化。因此,调整数组大小会创建两个以上的bucket(即链表),并将所有现有的条目重新分配到bucket中(旧的和新创建的)。
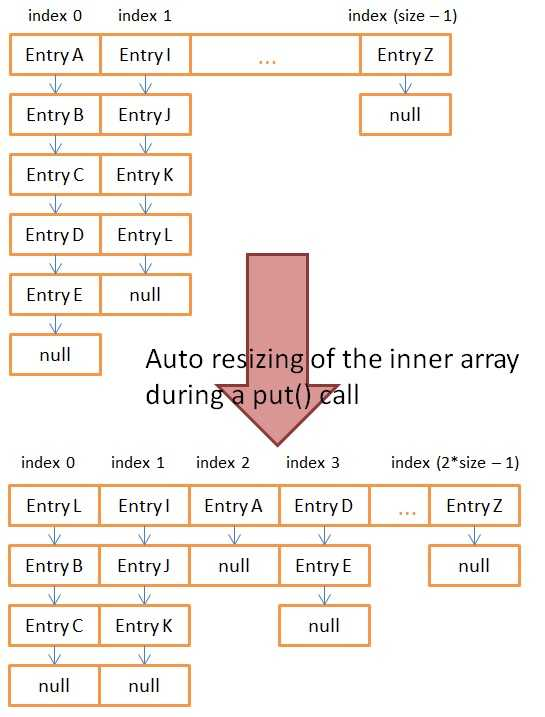
该图显示了调整内部数组大小前后的表示形式。在增加之前,为了得到条目E,map 必须遍历一个包含所有5个元素的列表。调整大小之后,相同的 get() 只遍历一个包含2个元素的链表,调整大小之后get()的速度是原来的2倍!
注意:HashMap只增加了内部数组的大小,而没有提供减小的方法。
3. 线程安全
HashMaps 线程不安全 , 这个是很多人都知道的 。 但是为什么呢 ? 例如,假设有一个只将新数据放入Map的Writer线程和一个从Map中读取数据的Reader线程,为什么不能工作呢?
答:因为在自动调整大小机制期间,如果线程尝试放入或获取对象,则映射可能使用旧索引值,并且将找不到该条目所在的bucket。
最糟糕的情况是2个线程同时放入数据那2个 put()调用在同时调整 Map 的大小。由于两个线程在同时修改链接列表,因此 Map 可能最终在其链接列表中有一个内部循环。如果您尝试使用内部循环获取列表中的数据,则get()将永远不会结束。
哈希表(HashTable)的实现是线程安全的实现,用来防止这种情况出现。但是,由于所有CRUD方法都是用Synchronized(这里不清楚指的是同步 还是JVM里关键字Synchronized , 用来上锁的),因此这种实现非常缓慢。例如,如果线程1调用 get(key1),则线程2调用 get(key2),线程3调用 get(key3),一次只有一个线程能够获取其值,而3个线程可以同时访问数据。
自 JAVA 5 以来,存在一个更安全的线程安全 HashMap 实现:ConcurrentHashMap。只有 buckets 是同步的,因此多个线程可以用 get(),remove()或 put()同时操作数据,如果它不代表着访问同一个bucket或调整内部数组的大小。最好在多线程应用程序中使用此实现。
4. 关键不变性
为什么一般 HashMap 的键(key)都用的是字符串和整数?主要是因为它们是不变的!如果您选择创建自己的 Key 的类并且不使其不可变,则可能会丢失 HashMap 中的数据。
看看下面的用例:
-
- 你有一个内部值为“1”的键
- 您使用此键将对象放入HashMap中
- HashMap根据Key的哈希码生成哈希值(因此从“1”开始)
- Map 将此哈希存储 在新创建的Entry中
- 您将键的内部值修改为“2”
- 密钥的哈希值被修改但HashMap不知道它(因为存储了旧的哈希值)
- 您尝试使用修改后的密钥获取对象
- 映射计算密钥的新哈希值(因此从“2”开始)以查找条目所在的链表(bucket)
- 情况1:由于您修改了密钥,因此映射会尝试在错误的存储桶中找到该条目,但找不到该条目
- 情况2:幸运的是,修改后的密钥生成与旧密钥相同的桶。然后,映射遍历链表以查找具有相同键的条目。但是为了找到密钥,映射首先比较哈希值,然后调用 equals()比较。由于修改后的密钥与旧散列值(存储在条目中)没有相同的散列,因此映射将不会在链接列表中找到该条目。
这是Java中的一个具体示例。我在 Map 中放了两个键值对,我修改了第一个键,然后尝试获取2个值。只有第二个值从 Map 返回,第一个值在 HashMap 中“丢失”:
public class MutableKeyTest { public static void main(String[] args) { class MyKey { Integer i; public void setI(Integer i) { this.i = i; } public MyKey(Integer i) { this.i = i; } @Override public int hashCode() { return i; } @Override public boolean equals(Object obj) { if (obj instanceof MyKey) { return i.equals(((MyKey) obj).i); } else return false; } } Map<MyKey, String> myMap = new HashMap<>(); MyKey key1 = new MyKey(1); MyKey key2 = new MyKey(2); myMap.put(key1, "test " + 1); myMap.put(key2, "test " + 2); // modifying key1 key1.setI(3); String test1 = myMap.get(key1); String test2 = myMap.get(key2); System.out.println("test1= " + test1 + " test2=" + test2); } }
输出为:“test1 = null test2 = test 2”。正如所料,Map无法使用修改后的密钥1检索字符串1。
5. Java8的改动
在JAVA 8中,HashMap的内部表示发生了很大的变化。实际上,JAVA 7中的实现需要1k行代码,而JAVA 8中的实现需要2k行。除了链接的条目列表之外,我之前说过的大部分内容都是正确的。在JAVA8中,您仍然有一个数组,但它现在存储的节点包含与条目完全相同的信息,因此也是链接列表:
以下是JAVA 8中Node实现的一部分:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;
那么与JAVA 7的最大区别是什么?好吧,节点可以扩展到TreeNodes。TreeNode是一种红黑树结构,可以存储更多信息,以便它可以添加,删除或获取O(log(n))中的元素。
仅供参考,这是存储在TreeNode中的数据的详尽列表
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { final int hash; // inherited from Node<K,V> final K key; // inherited from Node<K,V> V value; // inherited from Node<K,V> Node<K,V> next; // inherited from Node<K,V> Entry<K,V> before, after;// inherited from LinkedHashMap.Entry<K,V> TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red;
红黑树是自平衡二叉搜索树。尽管新添加或删除了节点,但它们的内部机制确保它们的长度始终为log(n)。使用这些树的主要优点是在许多数据位于内部表的相同索引(bucket)中的情况下,树中的搜索将花费 O(log(n)),而它将花费O(n)带有链表。
如您所见,树比链接列表占用更多空间(我们将在下一部分中讨论它)。
通过继承,内部表可以包含 Node(链表)和 TreeNode(红黑树)。Oracle决定使用具有以下规则的两种数据结构:
- 如果内部表中的给定索引(存储 bucket)有超过8个节点,则链表将转换为红黑树
- 如果对于给定索引(存储 bucket) )在内表中有少于6个节点,树被转换为链表

此图显示了JAVA 8 HashMap的内部数组,其中包含两个树(在 bucket 0处)和链接列表(在 bucke 1,2和3处)。Bucket 0是一棵树,因为它有超过8个节点。
6. 内存开销
JAVA 7
使用HashMap需要以内存为代价。在JAVA 7中,HashMap在条目中包装键值对。一个条目有:
-
- 对下一个条目的引用
- 预先计算的哈希(整数)
- 对密钥的引用
- 对价值的参考
而且,JAVA 7 HashMap使用Entry的内部数组。假设JAVA 7 HashMap包含N个元素且其内部数组具有容量CAPACITY,则额外的内存成本约为:
sizeOf(整数)* N + sizeOf(参考)*(3 * N + C)
Where:
-
- 整数的大小取决于4个字节
- 引用的大小取决于JVM / OS / Processor,但通常是4个字节。
这意味着开销通常是16 * N + 4 * CAPACITY字节
提醒:在自动调整Map的大小之后,内部数组的CAPACITY等于N之后的下一个2的幂。
注意:从JAVA 7开始,HashMap类有一个惰性初始化。这意味着,即使您分配了HashMap,在第一次使用put()方法之前,内部数组条目(成本为4 * CAPACITY字节)也不会在内存中分配。
JAVA 8
使用JAVA 8实现,获取内存使用变得有点复杂,因为Node可以包含与Entry相同的数据或相同的数据加上6个引用和布尔值(如果它是TreeNode)。
如果所有节点都只是节点,则JAVA 8 HashMap的内存消耗与JAVA 7 HashMap相同。
如果所有节点都是TreeNodes,则JAVA 8 HashMap的内存消耗将变为:
N * sizeOf(整数)+ N * sizeOf(布尔值)+ sizeOf(参考)*(9 * N +容量)
在大多数标准JVM中,它等于44 * N + 4 * CAPACITY字节
性能问题
倾斜的HashMap与均衡的HashMap相比
在最好的情况下,get()和 put()方法的时间复杂度成本为O(1)。但是,如果你不处理密钥的哈希函数,你最终可能会得到非常慢的 put()和 get()调用。put()和get的良好性能取决于将数据重新分配到内部数组(bucket)的不同索引中。如果你的密钥的哈希函数设计不合理,你将有一个偏斜重新分区(无论内部数组的容量有多大)。所有使用最大链接列表的 put()和 get()都会很慢,因为它们需要迭代整个列表。在最坏的情况下(如果大多数数据都在相同的存储区中),最终可能会出现 O(n)时间复杂度。
这是一个视觉示例。第一张图片显示了偏斜的 HashMap,第二张图片显示了平衡的 HashMap。

在这个偏斜的 hashMap 条件下, bucket 0 上 使用 get() / put() 方法浪费内存巨大 。获得实体 K 将要花费6次迭代
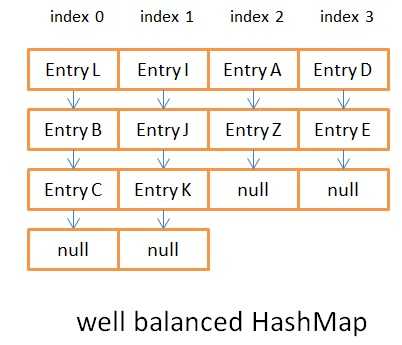
在这个平衡良好的HashMap的情况下,获得Entry K将花费3次迭代。两个HashMaps都存储相同数量的数据并具有相同的内部数组大小。唯一的区别是分配桶中条目的哈希(密钥)函数。
这是JAVA中的一个极端示例,我创建了一个哈希函数,将所有数据放在同一个 bucket 中,然后我添加了200万个元素。
public class Test { public static void main(String[] args) { class MyKey { Integer i; public MyKey(Integer i){ this.i =i; } @Override public int hashCode() { return 1; } @Override public boolean equals(Object obj) { … } } Date begin = new Date(); Map <MyKey,String> myMap= new HashMap<>(2_500_000,1); for (int i=0;i<2_000_000;i++){ myMap.put( new MyKey(i), "test "+i); } Date end = new Date(); System.out.println("Duration (ms) "+ (end.getTime()-begin.getTime())); } }
在我的CPU i5-2500k @ 3.6Ghz的电脑上使用 java 8u40 处理上面程序 需要超过45分钟(我在45分钟后停止了这个过程)。
现在,如果我运行相同的代码,但这次我使用以下哈希函数
@Override public int hashCode() { int key = 2097152-1; return key+2097152*i; }
需要46秒,这是更好的方式!此哈希函数具有比前一个更好的重新分区,因此put()调用更快。
如果我使用以下散列函数运行相同的代码,该函数提供更好的散列重新分区
@Override public int hashCode() { return i; }
现在需要2秒钟。
我希望你意识到哈希函数的重要性。如果在JAVA 7上运行相同的测试,则第一和第二种情况的结果会更糟(因为JAVA 7中的放置的时间复杂度为JAVA 7中的O(n)vs O(log(n))
使用HashMap时,您需要为键找到一个哈希函数,将键扩展到最可能的桶中。为此,您需要避免哈希冲突。String对象是一个很好的密钥,因为它具有良好的散列函数。整数也很好,因为它们的哈希码是它们自己的值。
调整开销大小
如果需要存储大量数据,则应创建初始容量接近预期容量的HashMap。
如果不这样做,Map 将采用默认大小 16,factorLoad为0.75。第一个 put()将非常快,但第12个(16 * 0.75)将重新创建一个新的内部数组(及其相关的链表/树),新容量为32个。第13个到第23个将快速但是第24个(32 * 0.75)将重新创建(再次)一个昂贵的新表示,使内部数组的大小加倍。内部调整大小操作将出现在put()的第48,第96,第192,...调用中。在低音量时,内部阵列的完全重新创建是快速的,但是在高音量时它可能需要几秒到几分钟。通过初始设置预期的大小,您可以避免这些 昂贵的操作。
但是有一个缺点:如果你设置一个非常高的数组大小,如2 ^ 28,而你的数组中只使用2 ^ 26个 bucket,你将浪费大量内存(在这种情况下约为2 ^ 30字节)。
Tip
曾遇到一个问题:
一个 springMVC 项目中 报异常信息 : cvc-complex-type.2.3: Element 'beans' cannot have character [children], because the type's content type is element-only.
且 .xml 最底部的 </bean> 标红,且有 Error 提示。 如图示 :

异常分析过程 :
猜想可能是没法确认控制器包的位置,那么就需要从项目的src级别开始给出完整的地址,但是我排查了很久 没发现配置文件和代码有什么错 怎么回事?
异常解决方案 :
Google 后在https://stackoverflow.com/questions/26725306/springs-element-beans-cannot-have-character-children-because-the-types-con# 获得解决 .感谢Stack OverFlow 。
我有同样的问题。我看了几个小时。我找不到任何问题。然后我决定,如果你使用不同的编辑器,有时会看到不同的东西。我关闭了Netbeans并在emacs中打开了该文件。我立即看到,有一些不间断的空格字符,或制表符,或某些类型的空白不是空格。我不知道它是哪个角色但它在emacs中以红色显示,但在Netban中是空白
我看了这个答案后 , 发现果然是空格的问题 。 同时也证明了, 99%的代码问题源于愚蠢的琐碎问题。
Share
Code Tells You How,Comments Tell You Why。 Brilliant!这周继续推荐
耗子哥的文章 高效学习:如何学习和阅读代码