- 什么是索引?
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。
id和磁盘地址的映射。

关系型数据库存在磁盘当中。
- 为什要用索引?
索引能极大减少存储引擎需要扫描的数据量。
索引可以把随机IO变成顺序IO。
索引可以帮助我们在进行分组、排序等操作时,避免使用临时表。
二叉查找树,Binary Search Tree。使用二分查找法,可以提高查找效率,但数据可能不均匀,极限时和全表扫描一样。

平衡二叉树:balanced binary search tree 相对平衡术(二路)

二叉树插入过程网址:www.cs.usfca.edu
一个节点的子节点高度差不超过1.
存在问题:

多路平衡查找树,B -tree,(B树)绝对平衡树

m路的平衡查找树,关键字最多是m-1个,解决了二叉树的问题。关系型数据库,B-树作为索引最常见的一种数据结构,或者用变种。mysql用的B+树。
索引不宜建多,会影响新增和删除。因为索引结构会调整,为了维持绝对平衡,特别耗时。
加强版多路平衡查找树-B+树:(没有数据区)

1.B+节点关键字搜索采用闭合区间。
2.B+非叶节点不保存数据相关信息,只保存关键字和子节点的引用。
3.B+关键字对应的数据保存在叶子节点中。
4.B+叶子结点是按顺序排列的,并且向临界点具有顺序引用的关系。
为什么选用B+tree:
B+树是B-树的变种多路平衡查找树,他拥有B-树的优势。
B+树扫库和扫表能力更强,尤其是扫表。
B+树的磁盘读写能力更强。(因为没有数据区,节约了磁盘空间,可以存储更多的关键字,路数更多)
B+树排序能力更强。(本身就有顺序)
B+树的查询效率更加稳定。(B+必须找到叶子结点,B-树查询效率不稳定,因为深度不一定。so仁者见仁,智者见智)
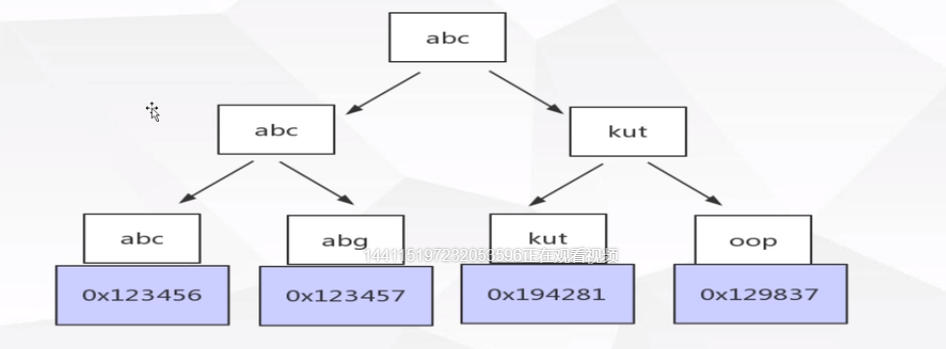
Mysql B+Tree索引体现形式
Mysql B+Tree索引体现形式 -Myisam
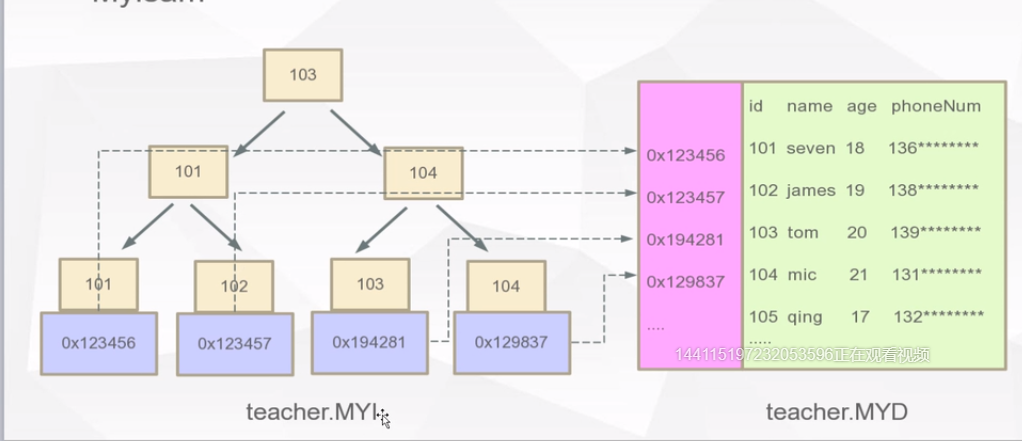
index文件保存索引,最末叶子结点保存指向每条记录的磁盘地址,data文件保存所有的数据。
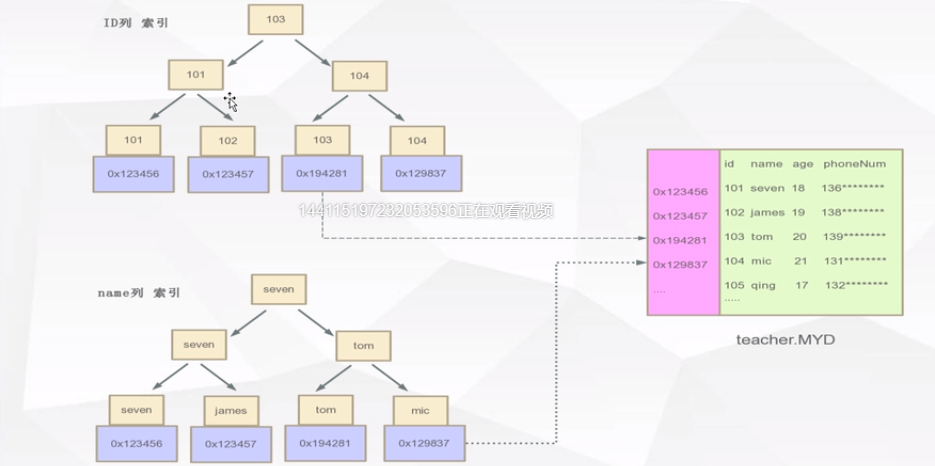
Mysql B+Tree索引体现形式 -InnoDB

innodb只有主键是聚集索引,其他都是非聚集索引

设计初衷,只有主键重要。
InnoDB vs Myisam

列的离散型 count(distinct col):count(col)
如下离散型最好的列是name:
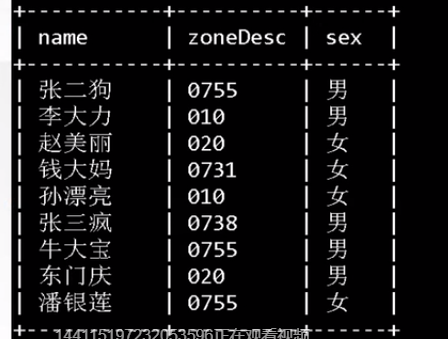
离散型越高,选择性越好。
最左匹配原则
对索引中关键字进行计算(对比),一定是从左往右依次进行,且不可跳过
like %abc%用不到索引,因为离散型太差 ,还不如做全表扫描。
联合索引
单列索引:节点中关键字【name】
联合索引:节点中关键字【name,phoneNum】
结论:
单列索引是特殊的联合索引
联合索引列选择原则
1.经常用的列优先【最左匹配原则】
2.选择性(离散度)高的列优先【离散度高原则】
3.宽度小的列优先【最小空间原则】
哈哈
经排查发现最常用的SQL语句:处理不优秀

最左匹配原则,建一个联合索引就够了。
覆盖索引
如果查询列可通过索引节点中的关键字直接返回,则该索引称为覆盖索引。

一条sql只会选择一条索引。
结论:
索引列的长度能少则少。
索引不一定越多越好,越全越好,一定是建合适的。
匹配列前缀可用到索引 like 999%,like %999%、like %999用不到索引;
where 条件中 not in 和 <>、!= 操作无法使用索引;
匹配范围值,order by ,group by 也可以用到索引;
多用指定列查询,只返回自己想到的数据列,少用select *;
联合索引中如果不是按照索引最左开始查找,无法使用索引;
联合索引中精确匹配最左前列并范围匹配另外一个列可以用到索引;
联合索引中如果查询有某个列的范围查询,则其右边的所有列都无法使用索引;
有些 where 条件会导致索引无效:
1.where 子句的查询条件里有!=,MySQL 将无法使用索引。
2.where 子句使用了 Mysql 函数的时候,索引将无效,比如:select * from tb
where left(name, 4) = 'xxx'
3.使用 LIKE 迕行搜索匹配的时候,返样索引是有效的:select * from tbl1 where name like 'xxx%',而 like '%xxx%' 时索引无效
4.不匹配的数据类型 char 搜索的时候 where name=你好 应该用 where name='你好' 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.在Where子句中使用IS NULL或者IS NOT NULL。
6.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)