从开始着手装双系统,到配置Hadoop,整整五天之后才终于能运行Eclipse里的代码,虽然时间用得有点久,但是对于一个对JAVA和分布式完全不了解的小白来说,我还是蛮开心的哈哈哈~
系统:Win8 + Ubuntu 12.04 LtS
前期准备:最开始我是打算在虚拟机VMware里配置Hadoop,装好了之后问同学注意事项的时候被告知,电脑配置不高的话虚拟机太卡,这种属于完全分布式的模式暂时还永不到,让我装双系统然后配置伪分布式,秉承着要“师傅另进门”的心态,准备听从大牛的建议。然后大牛辛苦了一天帮我装上Ubuntu(其间由于电脑显卡的问题折腾了好久,还换了个Ubuntu的版本才搞定),之后就都是我自己的事情了嗯嗯。。先配置Hadoop 和 Eclipse(http://www.cnblogs.com/kathyrine/p/3641330.html),里边的各种命令大多都不太懂,按照网上的教程来弄,出了好几个问题,好在各种查和问过同学之后搞定了。在运行过Hadoop里自带的 WordCount 程序之后,开始学着用 Eclipse 自己编译和运行代码。
参考链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 一定是大牛写的,看着人家写的蛮简单的,运行过程就直接说了个运行,其他的都没有说,人家应该是提前把各种小方面都配置好了,其实还蛮麻烦的。
第一个案例:数据去重,输入是以字符串String的形式,跟我们的作业大同小异,我们的输入只是整数。
第一步:建立输入文件:
file1.txt
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
file2.txt
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
第二步:写 MapReduce 代码:
首先要在 Eclipse 里建立 Java 的Project (name: hw),然后在 src 文件夹里 New Package (name: org.bigdata,名称最好都是小写,后来才知道里边的 . 是有建立子文件夹的用处 ) ,再再这个包里 New Class (name: Dedup,首字母需要大写,貌似是Java 写类名的规范 )
1 package org.bigdata; 2 3 import java.io.IOException; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.Mapper; 9 import org.apache.hadoop.mapreduce.Reducer; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 import org.apache.hadoop.util.GenericOptionsParser; 13 14 public class Dedup { 15 16 public static class Map extends Mapper { 17 private static Text line = new Text(); 18 19 public void map(Object key, Text value, Context context) 20 throws IOException, InterruptedException{ 21 line = value; 22 context.write(line, new Text("")); 23 } 24 } 25 26 public static class Reduce extends Reducer { 27 public void reduce(Text key, Iterable values, Context context) 28 throws IOException, InterruptedException{ 29 context.write(key, new Text("")); 30 } 31 } 32 33 public static void main(String[] args) throws Exception{ 34 Configuration conf = new Configuration(); 35 conf.set("mapred.job.tracke", "192.168.1.2:9001"); 36 37 String[] ioArgs = new String[]{"dedup_in", "dedup_out"}; 38 String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs(); 39 if(otherArgs.length != 2){ 40 System.err.println("Usage: Data Deduplication "); 41 System.exit(2); 42 } 43 44 Job job = new Job(conf, "Data Deduplication"); 45 job.setJarByClass(Dedup.class); 46 47 job.setMapperClass(Map.class); 48 job.setCombinerClass(Reduce.class); 49 job.setReducerClass(Reduce.class); 50 51 job.setOutputKeyClass(Text.class); 52 job.setOutputValueClass(Text.class); 53 54 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 55 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); 56 System.exit(job.waitForCompletion(true) ? 0 : 1); 57 } 58 }
运行 Ctrl + F11 之后会发现有很多错误,各种手足无措。按照Console上面的错误信息一个一个Google 发现是因为缺少 Hadoop 相关外部引用的 jar 包,这些包不会自动添加,需要手动加进来,网上有很多说法是在下载hadoop/lib 文件夹里又这些 jar 文件,其实没有,需要自己去找,找了好久,第一个下载得蛮快的。参考下载地址:
http://repo1.maven.org/maven2/org/apache/hadoop/hadoop-core/1.2.1/
http://www.java2s.com/Code/Jar/h/Downloadhadoopcore121jar.htm
方法:http://www.crifan.com/java_eclipse_the_import_org_apache_cannot_be_resolved/
选择 “Configure Build Path"
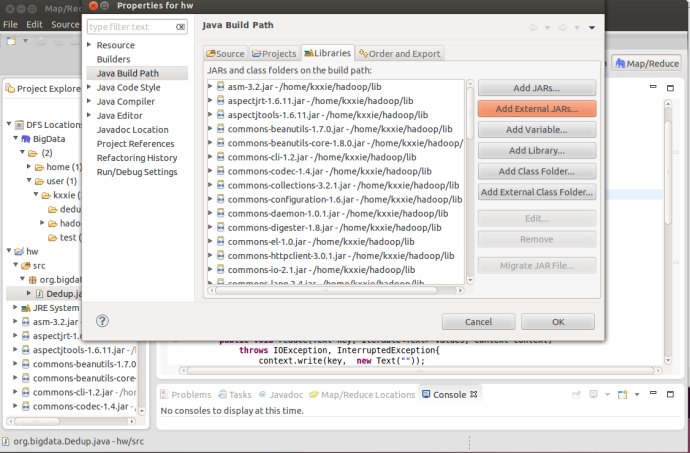
选择 Add External JARs,(将之前下载的hadoop-core-1.2.1.jar 解压到 hadoop/lib里),将 jar 包都加进来。然后运行,在Java里的各种输入地址特别关键,否则就会出现这个问题:
14/03/30 14:04:36 ERROR security.UserGroupInformation: PriviledgedActionException as:kxxie cause:org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/home/kxxie/workspace/hw/dedup_in
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/home/kxxie/workspace/hw/dedup_in
先明确当前目录是和src同级的目录,这个问题我弄了好久才明白,也就是如果要写相对路径的话,按照下面这种写法, input 和 output 的地址是和src的地址一样的。然后再运行就妥妥的了。这应该是本地运行,然后出现 output 文件夹,里边的文件part-r-0000就是运行结果。
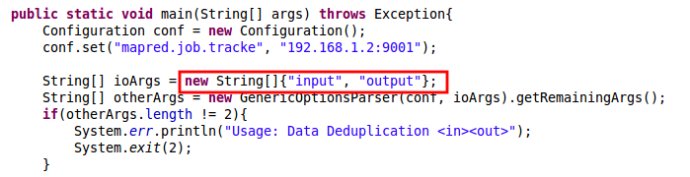
下面在Hadoop上运行,一开始我按照上面链接里说的,先在DFS Locations 的 /user/kxxie下建立 input 文件夹,Upload上面两个输入文件,然后在Eclipse里选择 Run on Hadoop就可以了。但是运行完之后跟大牛说的不一样,不会在DFS里不会出现 output 文件夹。然后舍弃了直接用的方法,不知道是不是尤其他的设置。
运行成功的方法如下:http://blog.sina.com.cn/s/blog_5d2184eb0100r0tz.html
如果想用Hadoop,要编译Dedup.java文件,将其制作成可执行的 jar包,(有同学告诉我说不这样也成功过,但是我不知到要怎么做),方法如下:
在终端输入命令: javac /org/bigdata/Dedup.java (前提是已经在编辑好了系统环境变量 classpath)
在org同级目录上建立manifest.mf:(Java项目中manifest.mf的作用:http://blog.sina.com.cn/s/blog_9075354e0101kc37.htm)输入命令: $ vim manifest.mf ,插入
Main-Class: org.bigdata.Dedup (注意在冒号后面又空格,且末尾输入后又回车,http://hi.baidu.com/gaoke966/item/78dc61cfe3fac426a1b50a63)(在查看输出文件的时候我不知道为什么必须写绝对路径,相对路径怎么也不对)
$ jar -cvfm Dedup.jar manifest.mf org/ $ hadoop jar Dedup.jar input output $ hadoop fs -cat /user/kxxie/output/part-r-00000
运行结果如下:
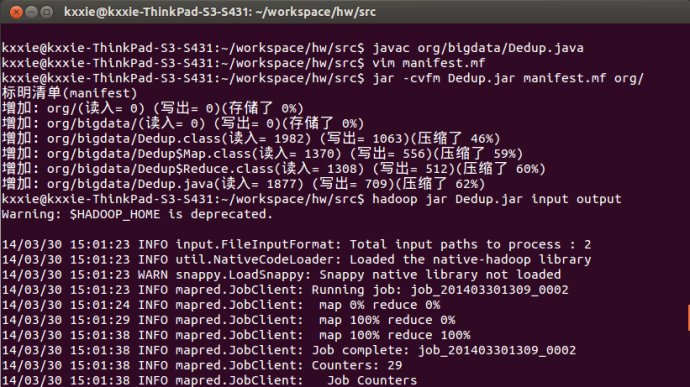
嗯。。很开心,终于知道怎么运行了。