跳过登录更改密码:
跳过密码登录:首先确保打开mysql服务,mysql路径加入了path中,然后使用管理员方式打开dos,输入命令:mysqld --skip-grant-tables 不要关闭窗口,再打开另一个dos窗口输入命令:mysql 登录成功。
更改密码:打开mysql数据库更改里面的user表,输入命令:
mysql>update user set authentication_string=password('123456') where user='root';
(将root用户密码更改为123456)
创建用户(参考博客:https://www.cnblogs.com/wanghetao/p/3806888.html)

创建数据库(模式):create schema text_schema;
show databases;
在模式里面创建表 :use text_chema;
create table text_table(text_col int,text_col1 smallint);
show tables;
删除数据库(模式):drop schema text_chema;
show tables;(报错)
show databases;
创建表:create database school_database;
create table student(sno char(9),primary key,sname char(20) unique,ssex char(2),sage smallint,sdept char(20));
show tables;
create table course(cno char(4) primary key,cname char(40) not null,cpno char(4),ccredit smallint,foreign key(cpno) references course(cno));//外键
create table sc(sno char(9),cno char(4),grade smallint,primary key(sno,cno),foreign key(sno) references student(sno),foreign key(cno) references course(cno));
数据类型
|
数据类型 |
含义 |
|
char(n),character(n) |
长度为n的定长字符串 |
|
varchar(n),charactervarying(n) |
最大长度为n的变长字符串 |
|
clob |
字符串大对象 |
|
blob |
二进制大对象 |
|
int,interger |
长整数(4字节) |
|
smallint |
短整型(2字节) |
|
bigint |
大整数(8字节) |
|
numeric(p,d), decimal(p,d),dec(p,d) |
顶点数,整数部分p位,小数部分d位 |
|
real |
取决于机器精度的单精度浮点数 |
|
double precision |
取决于机器精度的双精度浮点数 |
|
float(n) |
可选精度的浮点数,进度至少n位数字 |
|
boolean |
逻辑布尔量 |
|
date |
日期,YYYY-MM-DD |
|
time |
时间,HH:MM:SS |
|
timestamp |
时间戳类型 |
|
interval |
时间间隔类型 |
修改表:alter table student add s_entrance date;
alter table student modify sage int;
alter table course add unique(cname);
删除表:create table text_table(text_col int);
drop table text_table;
索引:顺序文件上的索引、B+树索引、散列索引、位图索引。
索引分为:unique(表明此索引的每一个索引值只对应唯一的数据记录)、cluster(聚簇索引)。
索引的建立与删除:create unique index stusno on student(sno);
create unique index coucno on course(cno);
create unique index scno on sc(sno asc,cno desc);
修改索引名:alter table sc drop index scno;
create unique index scsno on sc(sno asc,cno desc);
mysql中engine=innodb和engine=myisam的区别(https://www.cnblogs.com/avivahe/p/5427884.html)
修改编码:
1)修改mysql表的字符编码方式:alter table t_name convert to character set utf8 collate utf8_bin;
2)修改数据库的字符集:alter database mydb character set utf8;
3)创建数据库指定数据库的字符集:create database mydb character set utf8;
(*注意:修改编码是由于外键约束,导致报错,所以只有先撤销外键约束,修改后再建立)
![]()
撤销外键:
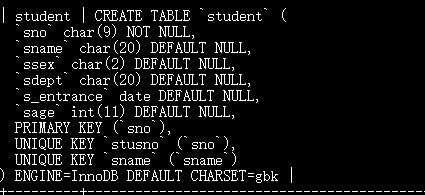
查看外键名:show create table course;
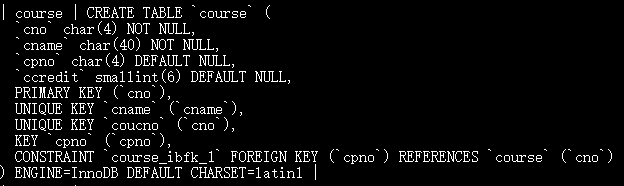
解除外键:alter table course drop foreign key course_ibfk_1;
重新创建外键的时候出现105错误,存在这种报错主要是创建约束时,有属性不一致的情况:ERROR 1005 (HY000): Can't create table 'school_database.#sql-1cd8_10' (errno: 150)
1)类型不一致:外键的引用类型不一样,如主键是int外键是char
2)引用不存在:找不到主表中引用的列
3)编码不一致:引用的字段和外键的字符编码不一致,也可能存储引擎不一样
4)约束不一致:引用的字段和外键的约束不同


插曲:student修改位utf8之后,还是105报错,其实是collate(排序规则)存在差异区别。
![]()

数据更新:
插入数据: insert into student(sno,sname,ssex,sdept,sage) values('201215121','李晨','男','sc',21);
修改数据:
修改一个元组:update student set sage=22 where sno='201215121';
修改多个元组:update student set sage=sage+1;
删除数据:
删除一个元组:delete from student where sno=’201215121’;
删除多个元组:delete from sc;
查看数据:select * from student;
向表中增加数据
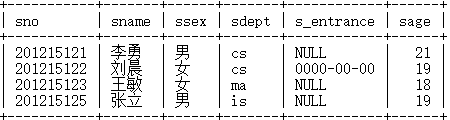

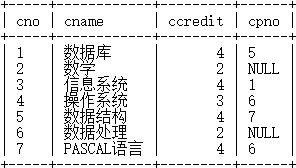
单表查询:
select sno,sname from student; select * from student;
select sno,2014-sage form student; select sno,’bir:’,2014-sage from student;
select sno,’Year of Birth:’,2014-sage birthday,upper(sdept) Dept from student;
select distinct sno from sc;//去掉表中的重复行
|
查询条件 |
谓词 |
|
比较 |
=,>,<,>=,<=,!=,<>,!>,!<;NOT+表运算符 |
|
确定范围 |
betweed and,not between and |
|
确定集合 |
in,not in |
|
字符匹配 |
like,not like |
|
空值 |
is null,is not null |
|
多重条件(逻辑运算) |
and,or,not |
select sname,sdept,sage from student where sage between 20 and 23;
select sname,ssex from student where sdept in(‘cs’,’ma’,’is’);
select sname,sno,ssex from student where sname like '刘%';
select sname from student where sname like '欧阳_';
select cno,ccredit from course where cname like ‘db\_Design’ ESCAPE’’;
//%表示任意长度字符串,’_’表示任意单个字符。ESCAPE‘’表示“”为换码字符。
select sname,grade from sc where cno=’3’ order by grade desc;
//desc降序、asc升序
|
聚集函数 |
功能 |
|
count(*) |
统计元组个数 |
|
count([distinct|all] <列名>) |
统计一列中值的个数 |
|
sum([distinct|all] <列名>) |
计算一列值得总和(此列是数值型) |
|
avg([distinct|all] <列名>) |
计算一列值得平均值 |
|
max([distinct|all] <列名>) |
求一列值中的最大值 |
|
min([distinct|all] <列名>) |
求一列值中的最大值 |
group by子句将查询结果按某一列或多列的值分组,值相等的为一组。分组后聚集函数讲座用于每一个组,即每一组都有一个函数值。
select cno,count(sno) from sc group by cno;
select sno from sc from sc group by sno having count(*)>3;//查询了选修了三门以上课的学生。
where子句和having短语的区别:where作用于基本表或视图,从中选出满足条件的元组。having作用于组,从中选出满足条件的组。
where子句不能用于聚集函数作为条件表达式。
错误:select sno,avg(grade) from sc where avg(grade)>=90 group by sno;
正确:select sno,avg(grade) from sc group by sno having avg(grade)>=90;
连接查询:
select student.sno,sname from student,sc where student.sno=sc.sno and sc.cno='2' and sc.grade>90;
自身连接:
select first.cno,second.cpno from course first,course second where first.cpno=second.cno and second.cpno is not null;
外连接 :
select student.sno,sname,ssex,sage,sdept,cno,grade from student left outer join sc on(student.sno=sc.sno);//左外连接
select student.sno,sname,ssex,sage,sdept,cno,grade from student right outer join sc on(student.sno=sc.sno);//右外连接
嵌套查询:select sname from student where sno in(select sno from sc where cno=’2’);
查询块:select-from-where语句成为一个查询块。
嵌套查询:将一个查询块嵌套到另一个查询块的where子句或having短语的条件中成为嵌套查询。
带in嵌套查询:
不相关子查询:子查询的查询条件不依赖于父查询。两个查询可以独立实现。
select sno,sname,sdept from student when sdept in(select sdept from student where sname=’刘晨‘);
带比较运算符嵌套查询
相关子查询:子查询的查询条件依赖于父查询。
select sno,cno from sc x where grade>=(select avg(grade) from sc y where y.sno=x.sno);
//x是sc的别名,又称为元组变量。参数x.sno的值与父查询相关。
带有any(some)或all谓词嵌套查询
select sname,sage,sdept from student where sage<any(select sage from student whre sdept=’cs’);
建立视图:create view is_student as select sno,sname,sage from student where sdept=’is’;
//create view只是把视图定义存入数据字典,并不执行其中的select语句。
create view is_student as select sno,sname,sage from student where sdept=’is’ with check option;//对数据进行操作都需要满足sdept=‘is’条件。
行列子集视图:从单个基本表导出的,并且只是去掉基本表的某些行或某些列,但保留了主码,则称这类视图为行列子集视图。
删除视图:drop view is_student;
查询视图:
视图消解:从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合起来,转换成等价的对基本表的查询,然后再执行修正了的查询。
目前多数关系数据库系统对行列自己视图的查询均能进行正确转换。但对非行列子集视图的查询就不一定能够转换。
更新视图:最总作用是表的更新。
视图的作用:1)视图能供简化用户的操作、2)视图使用户能以多角度看待同一数据、3)视图对重构数据库提供了一定程度的逻辑独立性、4)视图能够对机密数据提供安全保护、5)适当利用视图可以更清晰地表达查询。