常用快捷键:
Tab:使用Tab键来进行命令补全,补全目录、补全命令参数
Ctrl+c键来强行终止当前程序
Ctrl+d 键盘输入结束或退出终端
Ctrl+s 暂停当前程序,暂停后按下任意键恢复运行
Ctrl+z 将当前程序放到后台运行,恢复到前台为命令fg
Ctrl+a 将光标移至输入行头,相当于Home键
Ctrl+e 将光标移至输入行末,相当于End键
Ctrl+k 删除从光标所在位置到行末
Alt+Backspace 向前删除一个单词
Shift+PgUp 将终端显示向上滚动
Shift+PgDn 将终端显示向下滚动
通配符是一种特殊语句,主要有星号(*)和问号(?),用来对字符串进行模糊匹配(比如文件名、参数名)。当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正字符。
创建多个文件:touch love_{1..10}_keep.txt
创建新用户:sudo adduser 自定义用户名
切换用户:su -l 自定义用户名
删除用户: sudo deluser 自定义用户名 --remove-home
FHS标准:FHS(英文:Filesystem Hierarchy Standard 中文:文件系统层次结构标准)。
FHS 定义了两层规范,第一层是, / 下面的各个目录应该要放什么文件数据,例如 /etc 应该放置设置文件,/bin 与 /sbin 则应该放置可执行文件等等。
第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统日志文件,/usr/share 放置共享数据等等
使用 cd 命令可以切换目录
进入上一级目录:cd ..
进入home目录:cd ~
查看当前路径:pwd
绝对路径:简单地说就是以根" / "目录为起点的完整路径,以你所要到的目录为终点,表现形式如: /usr/local/bin,表示根目录下的 usr 目录中的 local 目录中的 bin 目录
相对路径:也就是相对于你当前的目录的路径,相对路径是以当前目录 . 为起点,以你所要到的目录为终点,表现形式如: usr/local/bin (这里假设你当前目录为根目录)。
# 绝对路径
$ cd /usr/local/bin
# 相对路径
$ cd ../../usr/local/bin
文件基本操作
新建空白文件:使用 touch 命令创建空白文件
新建目录:使用 mkdir(make directories)命令可以创建一个空目录,也可同时指定创建目录的权限属性。使用 -p 参数,同时创建父目录(如果不存在该父目录),如下我们同时创建一个多级目录(这在安装软件、配置安装路径时非常有用) 如:mkdir -p father/son/grandson
复制文件:使用 cp(copy)命令复制一个文件到指定目录,如:cp test father/son/grandson
复制目录:cp 加上 -r 或者 -R 参数,表示递归复制 如:cp -r father family
删除文件:使用 rm(remove files or directories)命令删除一个文件 如:rm 文件名
强制删除:rm -f 文件名
删除目录:跟复制目录一样,要删除一个目录,也需要加上 -r 或 -R 参数
如:rm -r family
移动文件:使用 mv(move or rename files)命令移动文件(剪切)如:将文件“ file1 ”移动到 Documents 目录 , mv file1 Documents
重命名文件:如:将文件“ file1 ”重命名为“ myfile ”:mv file1 myfile
批量重命名:rename
如:
# 使用通配符批量创建 5 个文件:
$ touch file{1..5}.txt
# 批量将这 5 个后缀为 .txt 的文本文件重命名为以 .c 为后缀的文件:
$ rename 's/.txt/.c/' *.txt
# 批量将这 5 个文件,文件名和后缀改为大写:
$ rename 'y/a-z/A-Z/' *.c
查看文件:使用 cat,tac 和 nl 命令,前两个命令都是用来打印文件内容到标准输出(终端),其中 cat 为正序显示,tac 为倒序显示。
如:cat 文件名 加-n 参数显示行号
nl 命令,添加行号并打印,这是个比 cat -n 更专业的行号打印命令。
这里简单列举它的常用的几个参数:
-b : 指定添加行号的方式,主要有两种:
-b a:表示无论是否为空行,同样列出行号("cat -n"就是这种方式)
-b t:只列出非空行的编号并列出(默认为这种方式)
-n : 设置行号的样式,主要有三种:
-n ln:在行号字段最左端显示
-n rn:在行号字段最右边显示,且不加 0
-n rz:在行号字段最右边显示,且加 0
-w : 行号字段占用的位数(默认为 6 位)
使用 head 和 tail 命令查看文件,只查看文件的头几行
只看一行, 加上 -n 参数,后面紧跟行数。
tail 命令,不得不提的还有它一个很牛的参数 -f,这个参数可以实现不停地读取某个文件的内容并显示。这可以让我们动态查看日志,达到实时监视的目的。
查看文件类型:file命令
变量:要解释环境变量,得先明白变量是什么,准确的说应该是 Shell 变量,所谓变量就是计算机中用于记录一个值(不一定是数值,也可以是字符或字符串)的符号,而这些符号将用于不同的运算处理中。通常变量与值是一对一的关系,可以通过表达式读取它的值并赋值给其它变量,也可以直接指定数值赋值给任意变量。为了便于运算和处理,大部分的编程语言会区分变量的类型,用于分别记录数值、字符或者字符串等等数据类型。Shell 中的变量也基本如此,有不同类型(但不用专门指定类型名),可以参与运算,有作用域限定。
使用 declare 命令创建一个变量名为 tmp 的变量:
$ declare tmp
读取变量的值,使用 echo 命令和 $ 符号($ 符号用于表示引用一个变量的值)
注意:并不是任何形式的变量名都是可用的,变量名只能是英文字母、数字或者下划线,且不能以数字作为开头。
环境变量:
set:显示当前 Shell 所有变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量。
env:显示与当前用户相关的环境变量,还可以让命令在指定环境中运行。
export:显示从 Shell 中导出成环境变量的变量,也能通过它将自定义变量导出为环境变量。
按变量的生存周期来划分,Linux 变量可分为两类:
永久的:需要修改配置文件,变量永久生效;
临时的:使用 export 命令行声明即可,变量在关闭 shell 时失效。
.profile 只对当前用户永久生效。而写在 /etc/profile 里面的是对所有用户永久生效,所以如果想要添加一个永久生效的环境变量,只需要打开 /etc/profile,在最后加上你想添加的环境变量就好啦。
变量删除:
unset 命令删除一个环境变量
相关的命令常用的有 whereis,which,find 和 locate
whereis 简单快速:whereis 只能搜索二进制文件(-b),man 帮助文件(-m)和源代码文件(-s)
locate 快而全:
which 小而精:which 本身是 Shell 内建的一个命令,我们通常使用 which 来确定是否安装了某个指定的软件,因为它只从 PATH 环境变量指定的路径中去搜索命令
find 精而细:find 应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索。注意 find 命令的路径是作为第一个参数的, 基本命令格式为 find [path] [option] [action] 。
参数 说明
-atime 最后访问时间
-ctime 最后修改文件内容的时间
-mtime 最后修改文件属性的时间
下面以 -mtime 参数举例:
-mtime n:n 为数字,表示为在 n 天之前的“一天之内”修改过的文件
-mtime +n:列出在 n 天之前(不包含 n 天本身)被修改过的文件
-mtime -n:列出在 n 天之内(包含 n 天本身)被修改过的文件
-newer file:file 为一个已存在的文件,列出比 file 还要新的文件名
Linux上压缩包文件格式:
文件后缀名 说明
*.zip zip 程序打包压缩的文件
*.rar rar 程序压缩的文件
*.7z 7zip 程序压缩的文件
*.tar tar 程序打包,未压缩的文件
*.gz gzip 程序(GNU zip)压缩的文件
*.xz xz 程序压缩的文件
*.bz2 bzip2 程序压缩的文件
*.tar.gz tar 打包,gzip 程序压缩的文件
*.tar.xz tar 打包,xz 程序压缩的文件
*tar.bz2 tar 打包,bzip2 程序压缩的文件
*.tar.7z tar 打包,7z 程序压缩的文件
zip命令的使用:
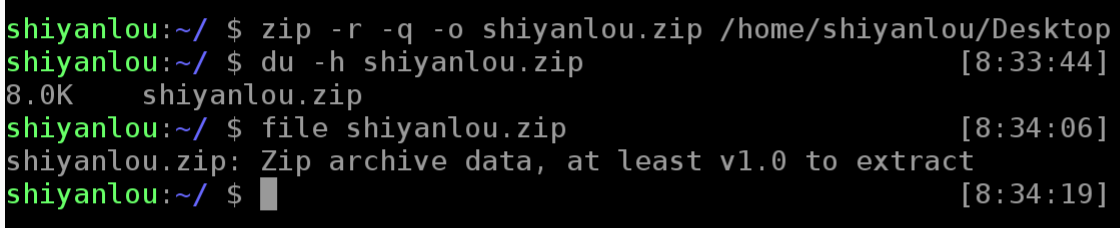
上面命令将目录 /home/shiyanlou/Desktop 打包成一个文件,并查看了打包后文件的大小和类型。第一行命令中,-r 参数表示递归打包包含子目录的全部内容,-q 参数表示为安静模式,即不向屏幕输出信息,-o,表示输出文件,需在其后紧跟打包输出文件名。后面使用 du 命令查看打包后文件的大小。
设置压缩级别为 9 和 1(9 最大,1 最小),重新打包:
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou/Desktop -x ~/*.zip $ zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou/Desktop -x ~/*.zip
这里添加了一个参数用于设置压缩级别 -[1-9],1 表示最快压缩但体积大,9 表示体积最小但耗时最久。最后那个 -x 是为了排除我们上一次创建的 zip 文件,否则又会被打包进这一次的压缩文件中,注意:这里只能使用绝对路径,否则不起作用。
再用 du 命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小
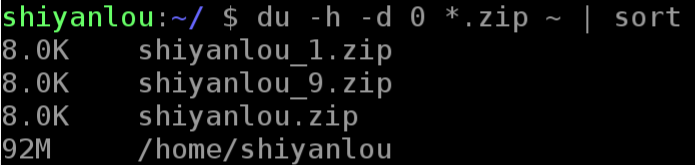
- h, --human-readable(加了能以k,或者M的单位显示文件的大小,不加则默认以k为单位显示文件大小)
- d, --max-depth(所查看文件的深度)
创建加密 zip 包
使用 -e 参数可以创建加密压缩包:
![]()
使用unzip命令解压缩zip文件
将 shiyanlou.zip 解压到当前目录:
$ unzip shiyanlou.zip
使用安静模式,将文件解压到指定目录:
$ unzip -q shiyanlou.zip -d ziptest
上述指定目录不存在,将会自动创建。如果你不想解压只想查看压缩包的内容你可以使用 -l 参数:
$ unzip -l shiyanlou.zip
注意: 使用 unzip 解压文件时我们同样应该注意兼容问题,不过这里我们关心的不再是上面的问题,而是中文编码的问题,通常 Windows 系统上面创建的压缩文件,如果有有包含中文的文档或以中文作为文件名的文件时默认会采用 GBK 或其它编码,而 Linux 上面默认使用的是 UTF-8 编码,如果不加任何处理,直接解压的话可能会出现中文乱码的问题(有时候它会自动帮你处理),为了解决这个问题,我们可以在解压时指定编码类型。
使用 -O(英文字母,大写 o)参数指定编码类型:
unzip -O GBK 中文压缩文件.zip (GBK位置可以自由选择编码类型,如:utf-8,gb2312等)
- zip:
- 打包 :zip something.zip something (目录请加 -r 参数)
- 解包:unzip something.zip
- 指定路径:-d 参数
- tar:
- 打包:tar -cf something.tar something
- 解包:tar -xf something.tar
- 指定路径:-C 参数
作业:创建一个名为 test 的文件,分别用 zip 和 tar 打包成压缩包,再解压到 /home/shiyanlou 目录。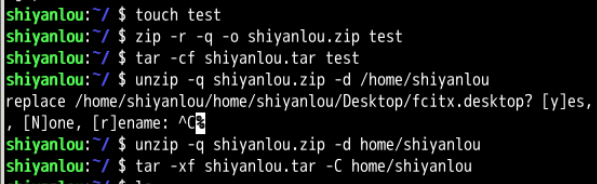
文件系统操作与磁盘管理:
1,使用 df 命令查看磁盘的容量
$ df
2,使用 du 命令查看目录的容量
du -h #同--human-readable 以K,M,G为单位,提高信息的可读性。 du -a #同--all 显示目录中所有文件的大小。 du -s #同--summarize 仅显示总计,只列出最后加总的值
使用 dd 命令创建虚拟镜像文件
通过上面一小节,你应该掌握了dd的基本使用,下面就来使用dd命令来完成创建虚拟磁盘的第一步。
从/dev/zero设备创建一个容量为 256M 的空文件:
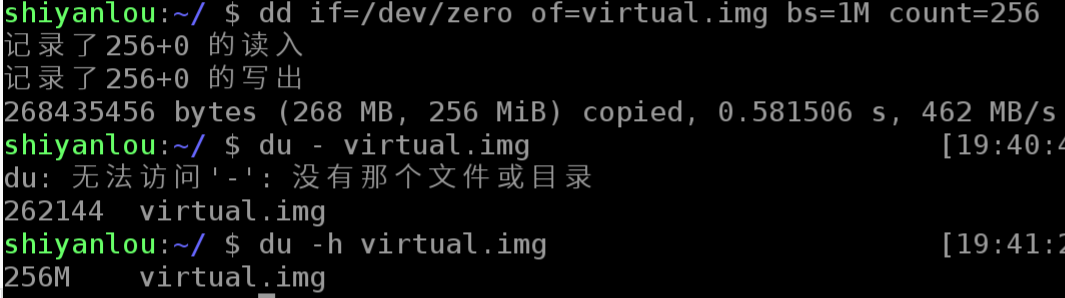
使用 mkfs 命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
你可以在命令行输入 sudo mkfs 然后按下Tab键,你可以看到很多个以 mkfs 为前缀的命令,这些不同的后缀其实就是表示着不同的文件系统,可以用 mkfs 格式化成的文件系统。
我们可以简单的使用下面的命令来将我们的虚拟磁盘镜像格式化为ext4文件系统:
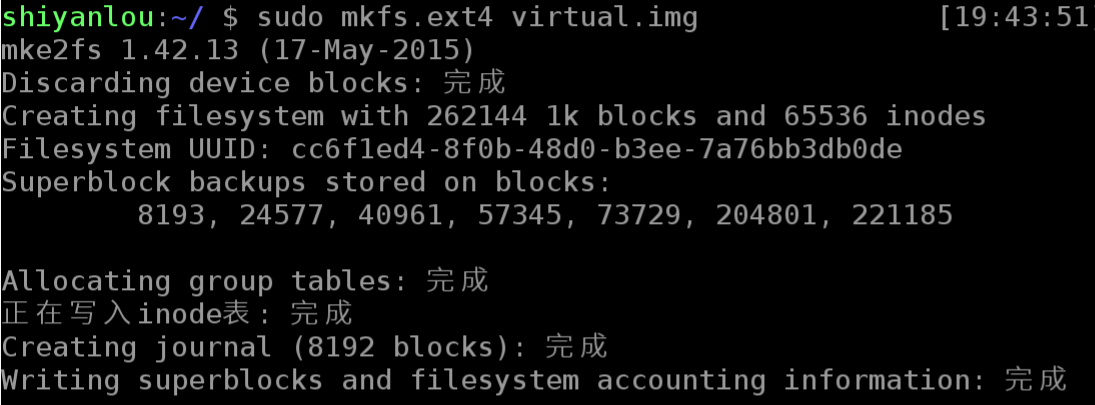
使用 mount 命令挂载磁盘到目录树
用户在 Linux/UNIX 的机器上打开一个文件以前,包含该文件的文件系统必须先进行挂载的动作,此时用户要对该文件系统执行 mount 的指令以进行挂载。该指令通常是使用在 USB 或其他可移除存储设备上,而根目录则需要始终保持挂载的状态。又因为 Linux/UNIX 文件系统可以对应一个文件而不一定要是硬件设备,所以可以挂载一个包含文件系统的文件到目录树。
Linux/UNIX 命令行的 mount 指令是告诉操作系统,对应的文件系统已经准备好,可以使用了,而该文件系统会对应到一个特定的点(称为挂载点)。挂载好的文件、目录、设备以及特殊文件即可提供用户使用。
$ sudo mount

输出的结果中每一行表示一个设备或虚拟设备,每一行最前面是设备名,然后是 on 后面是挂载点,type 后面表示文件系统类型,再后面是挂载选项(比如可以在挂载时设定以只读方式挂载等等)。
挂载我们创建的虚拟磁盘镜像到/mnt目录:
$ mount -o loop -t ext4 virtual.img /mnt # 也可以省略挂载类型,很多时候 mount 会自动识别 # 以只读方式挂载 $ mount -o loop --ro virtual.img /mnt # 或者mount -o loop,ro virtual.img /mnt
使用 umount 命令卸载已挂载磁盘
# 命令格式 sudo umount 已挂载设备名或者挂载点,如: $ sudo umount /mnt
使用 fdisk 为磁盘分区
# 查看硬盘分区表信息 $ sudo fdisk -l
# 进入磁盘分区模式 $ sudo fdisk virtual.img
使用 losetup 命令建立镜像与回环设备的关联
$ sudo losetup /dev/loop0 virtual.img # 如果提示设备忙你也可以使用其它的回环设备,"ls /dev/loop*"参看所有回环设备 # 解除设备关联 $ sudo losetup -d /dev/loop0
然后再使用mkfs格式化各分区(前面我们是格式化整个虚拟磁盘镜像文件或磁盘),不过格式化之前,我们还要为各分区建立虚拟设备的映射,用到kpartx工具,需要先安装:
$ sudo apt-get install kpartx $ sudo kpartx -av /dev/loop0 # 取消映射 $ sudo kpartx -dv /dev/loop0
接着再是格式化,我们将其全部格式化为 ext4:
$ sudo mkfs.ext4 -q /dev/mapper/loop0p1 $ sudo mkfs.ext4 -q /dev/mapper/loop0p5 $ sudo mkfs.ext4 -q /dev/mapper/loop0p6
格式化完成后在/media目录下新建四个空目录用于挂载虚拟磁盘:
$ mkdir -p /media/virtualdisk_{1..3}
# 挂载磁盘分区
$ sudo mount /dev/mapper/loop0p1 /media/virtualdisk_1
$ sudo mount /dev/mapper/loop0p5 /media/virtualdisk_2
$ sudo mount /dev/mapper/loop0p6 /media/virtualdisk_3
# 卸载磁盘分区
$ sudo umount /dev/mapper/loop0p1
$ sudo umount /dev/mapper/loop0p5
$ sudo umount /dev/mapper/loop0p6
$ df -h
内建命令与外部命令的区别:
内建命令实际上是 shell 程序的一部分,其中包含的是一些比较简单的 Linux 系统命令,这些命令是写在bash源码的builtins里面的,由 shell 程序识别并在 shell 程序内部完成运行,通常在 Linux 系统加载运行时 shell 就被加载并驻留在系统内存中。而且解析内部命令 shell 不需要创建子进程,因此其执行速度比外部命令快。比如:history、cd、exit 等等。
外部命令是 Linux 系统中的实用程序部分,因为实用程序的功能通常都比较强大,所以其包含的程序量也会很大,在系统加载时并不随系统一起被加载到内存中,而是在需要时才将其调入内存。虽然其不包含在 shell 中,但是其命令执行过程是由 shell 程序控制的。外部命令是在 Bash 之外额外安装的,通常放在/bin,/usr/bin,/sbin,/usr/sbin等等。比如:ls、vi等。

#得到这样的结果说明是内建命令,正如上文所说内建命令都是在 bash 源码中的 builtins 的.def中 xxx is a shell builtin #得到这样的结果说明是外部命令,正如上文所说,外部命令在/usr/bin or /usr/sbin等等中 xxx is /usr/bin/xxx #若是得到alias的结果,说明该指令为命令别名所设定的名称; xxx is an alias for xx --xxx
挑战-----备份日志
题目
备份日志
小明是一个服务器管理员,他需要每天备份论坛数据(这里我们用日志替代),备份当天的日志并删除之前的日志。而且备份之后文件名是年-月-日的格式。alternatives.log在/var/log/下面。
目标
为shiyanlou用户添加计划任务
每天凌晨3点的时候定时备份alternatives.log到/home/shiyanlou/tmp/目录
命名格式为年-月-日,比如今天是2017年4月1日,那么文件名为2017-04-01
提示
date
crontab
cp(备份)
用一条命令写在crontab里面即可,不用写脚本
注:如果fail没有任何提示信息,请刷新一下页面。注意crontab的计划用户者
crontab -e 表示为当前用户添加计划任务
sudo crontab -e 表示为root用户添加计划任务
解决方案
1.启动crontab
sudo crontab -f &2.编辑crontab文件
crontab -e在文件末尾加上
0 3 * * * cp /var/log/alternatives.log /home/shiyanlou/tmp/$(date+ \%Y-\%m-\%d)退出并保存 :wq
cut命令:打印每一行的某个字段。
# 前五个(包含第五个) $ cut /etc/passwd -c -5 # 前五个之后的(包含第五个) $ cut /etc/passwd -c 5- # 第五个 $ cut /etc/passwd -c 5 # 2到5之间的(包含第五个) $ cut /etc/passwd -c 2-5
grep命令,在文本中或stdin中查找匹配字符串。
grep命令的一般形式为:
grep [命令选项]... 用于匹配的表达式 [文件]...
我们搜索/home/shiyanlou目录下所有包含"shiyanlou"的文本文件,并显示出现在文本中的行号:

-r 参数表示递归搜索子目录中的文件,-n表示打印匹配项行号,-I表示忽略二进制文件。这个操作实际没有多大意义,但可以感受到grep命令的强大与实用。
wc命令简单小巧的计数工具。wc 命令用于统计并输出一个文件中行、单词和字节的数目。
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
# 行数 $ wc -l /etc/passwd # 单词数 $ wc -w /etc/passwd # 字节数 $ wc -c /etc/passwd # 字符数 $ wc -m /etc/passwd # 最长行字节数 $ wc -L /etc/passwd
注意:对于西文字符来说,一个字符就是一个字节,但对于中文字符一个汉字是大于2个字节的,具体数目是由字符编码决定的
sort 排序命令:功能很简单就是将输入按照一定方式排序,然后再输出,它支持的排序有按字典排序,数字排序,按月份排序,随机排序,反转排序,指定特定字段进行排序等等。
默认为字典排序:
$ cat /etc/passwd | sort
反转排序:
$ cat /etc/passwd | sort -r
按特定字段排序:
$ cat /etc/passwd | sort -t':' -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是以字典序排序的,如果要按照数字排序就要加上-n参数:
$ cat /etc/passwd | sort -t':' -k 3 -n
注意观察第二个冒号后的数字:

命令tr,col,join,paste的使用:
tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。
使用方式:
tr [option]...SET1 [SET2]常用的选项有:
-d :删除和set1匹配的字符,注意不是全词匹配也不是按字符顺序匹配
-s:去除set1指定的在输入文本中连续并重复的字符
操作举例:
# 删除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 将"hello" 中的ll,去重为一个l
$ echo 'hello' | tr -s 'l'
# 将输入文本,全部转换为大写或小写输出
$ echo 'input some text here' | tr '[:lower:]' '[:upper:]'
# 上面的'[:lower:]' '[:upper:]'你也可以简单的写作'[a-z]' '[A-Z]',当然反过来将大写变小写也是可以的
col 命令可以将Tab换成对等数量的空格键,或反转这个操作。
使用方式:
col [option]
常用的选项有:
-x:将Tab转换为空格。
-h:将空格转换为Tab(默认选项)。
操作举例:
# 查看 /etc/protocols 中的不可见字符,可以看到很多 ^I ,这其实就是 Tab 转义成可见字符的符号
$ cat -A /etc/protocols
# 使用 col -x 将 /etc/protocols 中的 Tab 转换为空格,然后再使用 cat 查看,你发现 ^I 不见了
$ cat /etc/protocols | col -x | cat -A
join这个命令就是用于将两个文件中包含相同内容的那一行合并在一起。
使用方式:
join [option]... file1 file2常用的选项有:
-t:指定分隔符,默认为空格
-i:忽略大小写的差异
-1:指明第一个文件要用哪个字段来对比,默认对比第一个字段
-2:指明第二个文件要用哪个字段来对比,默认对比第一个字段
操作举例:
$ cd /home/shiyanlou
# 创建两个文件
$ echo '1 hello' > file1
$ echo '1 shiyanlou' > file2
$ join file1 file2
# 将/etc/passwd与/etc/shadow两个文件合并,指定以':'作为分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 将/etc/passwd与/etc/group两个文件合并,指定以':'作为分隔符, 分别比对第4和第3个字段
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
使用方式:
paste [option] file...常用的选项有:
-d:指定合并的分隔符,默认为Tab
-s:不合并到一行,每个文件为一行
操作举例:
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3
作业:
1、在《文件打包与解压缩》一节实验中提到 Windows/dos 与 Linux/UNIX 文本文件一些特殊字符不一致
如断行符 Windows 为 CR+LF(
),Linux/UNIX 为 LF(
)。使用cat -A 文本 可以看到文本中包含的不可见特殊字符。Linux 的
表现出来就是一个$,而 Windows/dos的表现为^M$,可以直接使用dos2unix和unix2dos工具在两种格式之间进行转换,使用file命令可以查看文件的具体类型。
不过现在希望你在不使用上述两个转换工具的情况下,使用前面学过的命令手动完成 dos 文本格式到 UNIX 文本格式的转换。
![]()
数据流重定向:
以下两个简单的重定向操作,操作符>,>>表示是从左到右 , <,<<右到左

Linux 默认提供了三个特殊设备,用于终端的显示和输出,分别为stdin(标准输入,对应于你在终端的输入),stdout(标准输出,对应于终端的输出),stderr(标准错误输出,对应于终端的输出)。

文件描述符:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
默认使用终端的标准输入作为命令的输入和标准输出作为命令的输出。将cat的连续输出(heredoc方式)重定向到一个文件
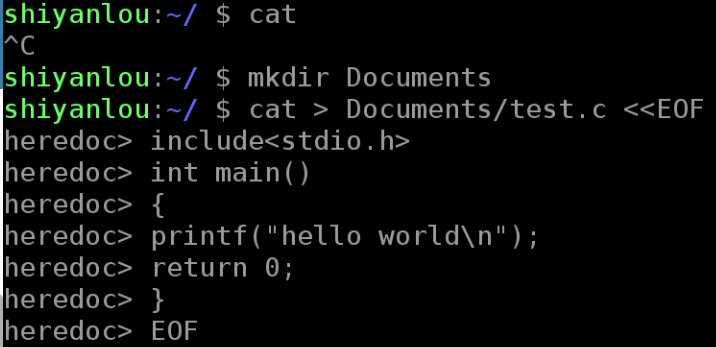
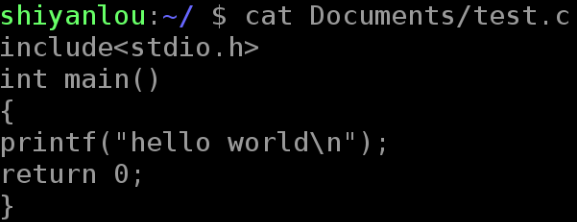
将一个文件作为命令的输入,标准输出作为命令的输出:
将echo命令通过管道传过来的数据作为cat命令的输入,将标准输出作为命令的输出
$ echo 'hi' | cat
将echo命令的输出从默认的标准输出重定向到一个普通文件
$ echo 'hello shiyanlou' > redirect
$ cat redirect管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接
标准错误重定向:
重定向标准输出到文件,这是一个很实用的操作,另一个很实用的操作是将标准错误重定向,标准输出和标准错误都被指向伪终端的屏幕显示,所以我们经常看到的一个命令的输出通常是同时包含了标准输出和标准错误的结果的。比如下面的操作:
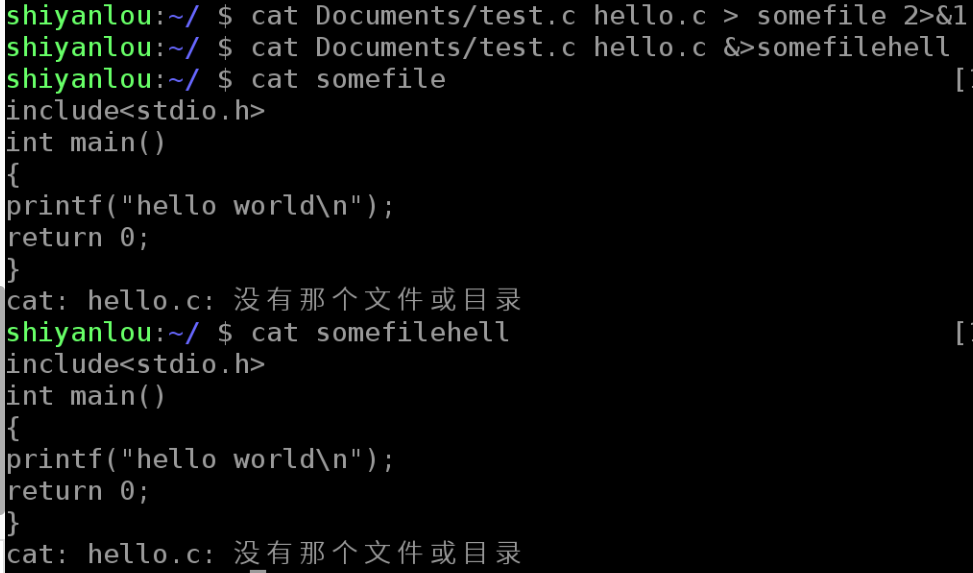
# 使用cat 命令同时读取两个文件,其中一个存在,另一个不存在
$ cat Documents/test.c hello.c
# 你可以看到除了正确输出了前一个文件的内容,还在末尾出现了一条错误信息
# 下面我们将输出重定向到一个文件
$ cat Documents/test.c hello.c > somefile 
遗憾的是,这里依然出现了那条错误信息,这正是因为如我上面说的那样,标准输出和标准错误虽然都指向终端屏幕,实际它们并不一样。那有的时候我们就是要隐藏某些错误或者警告,那又该怎么做呢。这就需要用到我们前面讲的文件描述符了:
# 将标准错误重定向到标准输出,再将标准输出重定向到文件,注意要将重定向到文件写到前面
$ cat Documents/test.c hello.c >somefile 2>&1
# 或者只用bash提供的特殊的重定向符号"&"将标准错误和标准输出同时重定向到文件
$ cat Documents/test.c hello.c &>somefilehell
注意你应该在输出重定向文件描述符前加上&,否则shell会当做重定向到一个文件名为1的文件中
使用tee命令同时重定向到多个文件
你可能还有这样的需求,除了需要将输出重定向到文件,也需要将信息打印在终端。那么你可以使用tee命令来实现:
$ echo 'hello shiyanlou' | tee hello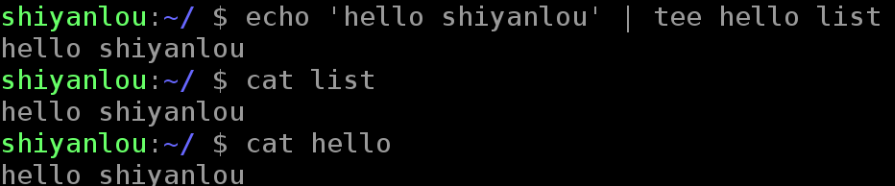
永久重定向:
你应该可以看出我们前面的重定向操作都只是临时性的,即只对当前命令有效,那如何做到“永久”有效呢,比如在一个脚本中,你需要某一部分的命令的输出全部进行重定向,难道要让你在每个命令上面加上临时重定向的操作嘛,当然不需要,我们可以使用exec命令实现“永久”重定向。exec命令的作用是使用指定的命令替换当前的 Shell,即使用一个进程替换当前进程,或者指定新的重定向:
# 先开启一个子 Shell
$ zsh
# 使用exec替换当前进程的重定向,将标准输出重定向到一个文件
$ exec 1>somefile
# 后面你执行的命令的输出都将被重定向到文件中,直到你退出当前子shell,或取消exec的重定向(后面将告诉你怎么做)
$ ls
$ exit
$ cat somefile

创建输出文件描述符:
在 Shell 中有9个文件描述符。上面我们使用了也是它默认提供的0,1,2号文件描述符。另外我们还可以使用3-8的文件描述符,只是它们默认没有打开而已。你可以使用下面命令查看当前 Shell 进程中打开的文件描述符:
$ cd /dev/fd/;ls -Al
同样使用exec命令可以创建新的文件描述符:
$ zsh
$ exec 3>somefile
# 先进入目录,再查看,否则你可能不能得到正确的结果,然后再回到上一次的目录
$ cd /dev/fd/;ls -Al;cd -
# 注意下面的命令>与&之间不应该有空格,如果有空格则会出错
$ echo "this is test" >&3
$ cat somefile
$ exit关闭文件描述符:
如上面我们打开的3号文件描述符,可以使用如下操作将它关闭:
$ exec 3>&-
$ cd /dev/fd;ls -Al;cd -完全屏蔽命令的输出:
在 Linux 中有一个被称为“黑洞”的设备文件,所有导入它的数据都将被“吞噬”。
在类 UNIX 系统中,/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成。读取它则会立即得到一个EOF。
我们可以利用设个/dev/null屏蔽命令的输出:
$ cat Documents/test.c nefile 1>/dev/null 2>&1
上面这样的操作将使你得不到任何输出结果。
介绍
在 Linux 中,对于文本的处理和分析是极为重要的,现在有一个文件叫做 data1,可以使用下面的命令下载:
$ cd /home/shiyanlou
$ wget http://labfile.oss.aliyuncs.com/courses/1/data1
data1 文件里记录是一些命令的操作记录,现在需要你从里面找出出现频率次数前3的命令并保存在 /home/shiyanlou/result。
目标
- 处理文本文件
/home/shiyanlou/data1 - 将结果写入
/home/shiyanlou/result - 结果包含三行内容,每行内容都是出现的次数和命令名称,如“100 ls”
提示
- cut 截取 (参数可以使用
-c 8-,使用 man cut 可以查看含义) uniq -dc去重- sort 的参数选择
-k1 -n -r - 操作过程使用管道,例如:
$ cd /home/shiyanlou
$ cat data1 |....|....|.... > /home/shiyanlou/result参考答案
cat data1 |cut -c 8-|sort|uniq -dc|sort -rn -k1 |head -3 > /home/shiyanlou/resultcut -c 8- 获取八位以后的有效字符
sort 默认排序
uniq -dc 删除重复,并输出重复数字
sort -n -r 按数字从大到小排列
head -n- 3 显示头三个
正则表达式:
什么是正则表达式呢?
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在 Perl 中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由 UNIX 中的工具软件(例如
sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有 regexp、regex,复数有 regexps、regexes、regexen。
基本语法:
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
选择
|竖直分隔符表示选择,例如"boy|girl"可以匹配"boy"或者"girl"
数量限定
数量限定除了我们举例用的*,还有+加号,?问号,如果在一个模式中不加数量限定符则表示出现一次且仅出现一次:
+表示前面的字符必须出现至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;?表示前面的字符最多出现一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";*星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。例如,"gr(a|e)y"等价于"gray|grey",(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),"(grand)?father"匹配father和grandfather(这里体验了范围,?将圆括号内容作为一个整体匹配)。
语法(部分)
正则表达式有多种不同的风格,下面列举一些常用的作为 PCRE 子集的适用于perl和python编程语言及grep或egrep的正则表达式匹配规则:(由于markdown表格解析的问题,下面的竖直分隔符用全角字符代替,实际使用时请换回半角字符)
| 字符 | 描述 |
|---|---|
| 将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。“ ”匹配一个换行符。序列“\”匹配“”而“(”则匹配“(”。 | |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“ ”之外的任何单个字符。要匹配包括“ ”在内的任何字符,请使用像“(.| )”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用“(”或“)”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字符仅有反斜线保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果出现在首位则仅作为普通字符。 |
| [^xyz] | 排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
优先级
优先级为从上到下从左到右,依次降低:
运算符 说明
转义符
(), (?:), (?=), [] 括号和中括号
*、+、?、{n}、{n,}、{n,m} 限定符
^、$、任何元字符 定位点和序列
| 选择
regex的思导图:

grep模式匹配命令:
grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
不过在你没学过perl语言的大多数情况下你将只会使用到ERE和BRE,所以我们接下来的内容都不会讨论到PCRE中特有的一些正则表达式语法(它们之间大部分内容是存在交集的,所以你不用担心会遗漏多少重要内容)
在通过grep命令使用正则表达式之前,先介绍一下它的常用参数:
| 参数 | 说明 |
|---|---|
-b |
将二进制文件作为文本来进行匹配 |
-c |
统计以模式匹配的数目 |
-i |
忽略大小写 |
-n |
显示匹配文本所在行的行号 |
-v |
反选,输出不匹配行的内容 |
-r |
递归匹配查找 |
-A n |
n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行 |
-B n |
n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行 |
--color=auto |
将输出中的匹配项设置为自动颜色显示 |
注:在大多数发行版中是默认设置了grep的颜色的,你可以通过参数指定或修改
GREP_COLOR环境变量。

使用正则表达式:
使用基本正则表达式,BRE
- 位置
查找/etc/group文件中以"shiyanlou"为开头的行
$ grep 'shiyanlou' /etc/group
$ grep '^shiyanlou' /etc/group
- 数量
# 将匹配以'z'开头以'o'结尾的所有字符串
$ echo 'zero
zo
zoo' | grep 'z.*o'
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ echo 'zero
zo
zoo' | grep 'z.o'
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ echo 'zero
zo
zoo' | grep 'zo*'
注意:其中
为换行符
- 选择
# grep默认是区分大小写的,这里将匹配所有的小写字母 $ echo '1234 abcd' | grep '[a-z]' # 将匹配所有的数字 $ echo '1234 abcd' | grep '[0-9]' # 将匹配所有的数字 $ echo '1234 abcd' | grep '[[:digit:]]' # 将匹配所有的小写字母 $ echo '1234 abcd' | grep '[[:lower:]]' # 将匹配所有的大写字母 $ echo '1234 abcd' | grep '[[:upper:]]' # 将匹配所有的字母和数字,包括0-9,a-z,A-Z $ echo '1234 abcd' | grep '[[:alnum:]]' # 将匹配所有的字母 $ echo '1234 abcd' | grep '[[:alpha:]]'
下面包含完整的特殊符号及说明:
| 特殊符号 | 说明 |
|---|---|
[:alnum:] |
代表英文大小写字母及数字,亦即 0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字母,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字母,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字符 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:" ' ? ! ; : # $... |
[:upper:] |
代表大写字母,亦即 A-Z |
[:space:] |
任何会产生空白的字符,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在
LANG环境变量的值,zh_CN.UTF-8的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,"a A b B...z Z",[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
-
# 排除字符 $ $ echo 'geek good' | grep '[^o]'
注意:当^放到中括号内为排除字符,否则表示行首。
使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
- 数量
# 只匹配"zo"
$ echo 'zero
zo
zoo' | grep -E 'zo{1}'
# 匹配以"zo"开头的所有单词
$ echo 'zero
zo
zoo' | grep -E 'zo{1,}'
注意:推荐掌握
{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
- 选择
# 匹配"www.shiyanlou.com"和"www.google.com"
$ echo 'www.shiyanlou.com
www.baidu.com
www.google.com' | grep -E 'www.(shiyanlou|google).com'
# 或者匹配不包含"baidu"的内容
$ echo 'www.shiyanlou.com
www.baidu.com
www.google.com' | grep -Ev 'www.baidu.com'
注意:因为
.号有特殊含义,所以需要转义。
sed流编辑器:
sed 命令基本格式:
sed [参数]... [执行命令] [输入文件]...
# 形如:
$ sed -i 's/sad/happy/' test # 表示将test文件中的"sad"替换为"happy"
| 参数 | 说明 |
|---|---|
-n |
安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
-e |
用于在脚本中添加多个执行命令一次执行,在命令行中执行多个命令通常不需要加该参数 |
-f filename |
指定执行filename文件中的命令 |
-r |
使用扩展正则表达式,默认为标准正则表达式 |
-i |
将直接修改输入文件内容,而不是打印到标准输出设备 |
sed执行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中n1,n2表示输入内容的行号,它们之间为,逗号则表示从n1到n2行,如果为~波浪号则表示从n1开始以step为步进的所有行;command为执行动作,下面为一些常用动作指令:
| 命令 | 说明 |
|---|---|
s |
行内替换 |
c |
整行替换 |
a |
插入到指定行的后面 |
i |
插入到指定行的前面 |
p |
打印指定行,通常与-n参数配合使用 |
d |
删除指定行 |
我们先找一个用于练习的文本文件:
$ cp /etc/passwd ~
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'行内替换
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
注意: 行内替换可以结合正则表达式使用。
行间替换
$ nl passwd | grep "shiyanlou"
# 删除第21行
$ sed -n '21cwww.shiyanlou.com' passwd
(这里我们只把要删的行打印出来了,并没有真正的删除,如果要删除的话,请使用-i参数)awk文本处理语言
awk所有的操作都是基于pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {action}
你可以看到就如同很多编程语言一样,它将所有的动作操作用一对{}花括号包围起来。其中pattern通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作。在一个完整awk操作中,这两者可以只有其中一个,如果没有pattern则默认匹配输入的全部文本,如果没有action则默认为打印匹配内容到屏幕。
awk处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk以空格作为一个字段的分割符,不过这不是固定的,你可以任意指定分隔符,下面将告诉你如何做到这一点。
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件。
先用vim新建一个文本文档
$ vim test
包含如下内容:
I like linux
www.shiyanlou.com
- 使用awk将文本内容打印到终端
# "quote>" 不用输入
$ awk '{
> print
> }' test
# 或者写到一行
$ awk '{print}' test
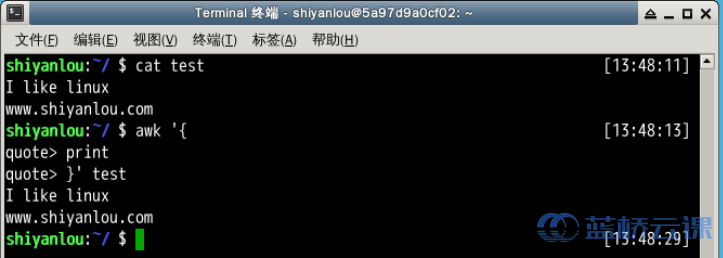
说明:在这个操作中我是省略了pattern,所以awk会默认匹配输入文本的全部内容,然后在"{}"花括号中执行动作,即print打印所有匹配项,这里是全部文本内容
- 将test的第一行的每个字段单独显示为一行
$ awk '{
> if(NR==1){
> print $1 "
" $2 "
" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="
"
> print $1, $2, $3
> } else {
> print}
> }' test
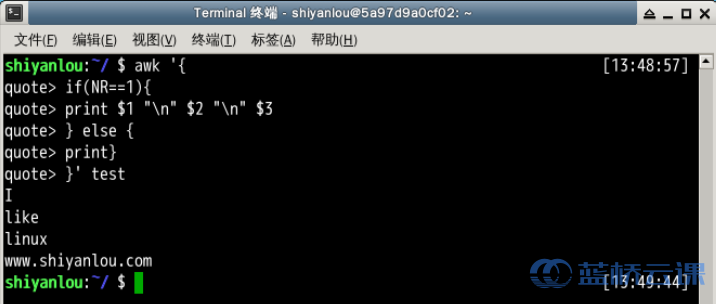
说明:你首先应该注意的是,这里我使用了awk语言的分支选择语句if,它的使用和很多高级语言如C/C++语言基本一致,如果你有这些语言的基础,这里将很好理解。另一个你需要注意的是NR与OFS,这两个是awk内建的变量,NR表示当前读入的记录数,你可以简单的理解为当前处理的行数,OFS表示输出时的字段分隔符,默认为" "空格,如上图所见,我们将字段分隔符设置为
换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是$N其中N为相应的字段号,这也是awk的内建变量,它表示引用相应的字段,因为我们这里第一行只有三个字段,所以只引用到了$3。除此之外另一个这里没有出现的$0,它表示引用当前记录(当前行)的全部内容。
- 将test的第二行的以点为分段的字段换成以空格为分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 " " $2 " " $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS=" " # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test
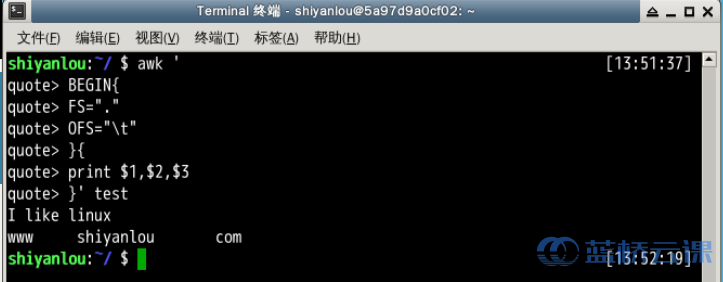
说明:这里的-F参数,前面已经介绍过,它是用来预先指定待处理记录的字段分隔符。我们需要注意的是除了指定OFS我们还可以在print 语句中直接打印特殊符号如这里的 ,print打印的非变量内容都需要用""一对引号包围起来。上面另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是FS赋值了新的"."点号代替默认的" "空格
| 变量名 | 说明 |
|---|---|
FILENAME |
当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
$0 |
当前记录的内容 |
$N |
N表示字段号,最大值为NF变量的值 |
FS |
字段分隔符,由正则表达式表示,默认为" "空格 |
RS |
输入记录分隔符,默认为" ",即一行为一个记录 |
NF |
当前记录字段数 |
NR |
已经读入的记录数 |
FNR |
当前输入文件的记录数,请注意它与NR的区别 |
OFS |
输出字段分隔符,默认为" "空格 |
ORS |
输出记录分隔符,默认为" " |
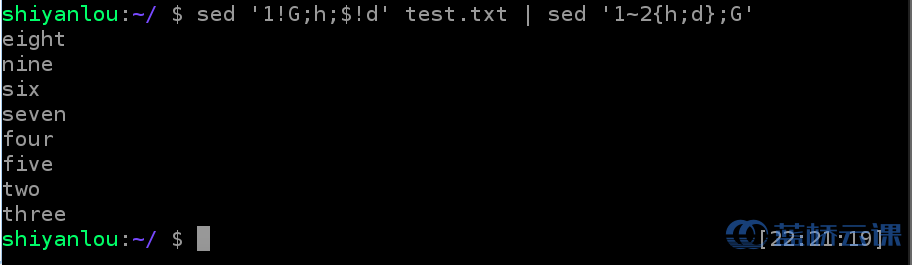
练习:基于 pattern space 和 hold space 实现将一个文本倒序输出和交换奇数行和偶数行
假设构建一个如下的简单文档test.txt:
$ vim text.txt #one
two.........eight
nine
$ sed '1!G;h;$!d' test.txt | sed '1~2{h;d};G'