Chapter 6 - Data Sourcing via Web
Segment 5 - Introduction to NLP
import nltk
text = "On Wednesday, the Association for Computing Machinery, the world’s largest society of computing professionals, announced that Hinton, LeCun and Bengio had won this year’s Turing Award for their work on neural networks. The Turing Award, which was introduced in 1966, is often called the Nobel Prize of computing, and it includes a $1 million prize, which the three scientists will share."
nltk.set_proxy('http://192.168.2.16:1080')
nltk.download('punkt')
[nltk_data] Downloading package punkt to /home/ericwei/nltk_data...
[nltk_data] Package punkt is already up-to-date!
True
Sentence Tokenizer
from nltk.tokenize import sent_tokenize
sent_tk = sent_tokenize(text)
print("Sentence tokenizing the text:
")
print(sent_tk)
Sentence tokenizing the text:
['On Wednesday, the Association for Computing Machinery, the world’s largest society of computing professionals, announced that Hinton, LeCun and Bengio had won this year’s Turing Award for their work on neural networks.', 'The Turing Award, which was introduced in 1966, is often called the Nobel Prize of computing, and it includes a $1 million prize, which the three scientists will share.']
Word Tokenizer
from nltk.tokenize import word_tokenize
word_tk = word_tokenize(text)
print("Word tokenizing the text:
")
print(word_tk)
Word tokenizing the text:
['On', 'Wednesday', ',', 'the', 'Association', 'for', 'Computing', 'Machinery', ',', 'the', 'world', '’', 's', 'largest', 'society', 'of', 'computing', 'professionals', ',', 'announced', 'that', 'Hinton', ',', 'LeCun', 'and', 'Bengio', 'had', 'won', 'this', 'year', '’', 's', 'Turing', 'Award', 'for', 'their', 'work', 'on', 'neural', 'networks', '.', 'The', 'Turing', 'Award', ',', 'which', 'was', 'introduced', 'in', '1966', ',', 'is', 'often', 'called', 'the', 'Nobel', 'Prize', 'of', 'computing', ',', 'and', 'it', 'includes', 'a', '$', '1', 'million', 'prize', ',', 'which', 'the', 'three', 'scientists', 'will', 'share', '.']
Removing stop words
nltk.download('stopwords')
[nltk_data] Downloading package stopwords to
[nltk_data] /home/ericwei/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
True
from nltk.corpus import stopwords
sw = set(stopwords.words("english"))
print("Stop words in English language are:
")
print(sw)
Stop words in English language are:
{'each', "weren't", 'just', 'on', 'o', 'all', "won't", 'how', 'own', 'didn', 'shouldn', 'will', 'out', 'against', 'off', 'very', 'now', 'that', 'weren', 'if', 'ain', 'ma', 'it', 'the', 'i', 'yourself', "hadn't", 'needn', 'have', "she's", 'an', 'he', 'because', 'for', 'few', "mustn't", 'than', 'don', 'and', 'other', 'were', 'should', 're', 'there', 'll', 'down', 'couldn', 'herself', 'then', "needn't", 'my', 'is', 'she', 'with', 'where', 'having', 'from', 'himself', "haven't", "isn't", 'after', 'no', 'has', 'am', 'does', 'between', 'a', 'mustn', 'did', 'being', 'at', 'doesn', "couldn't", 'y', 'yourselves', 's', 'who', 'until', 'what', 'myself', 'hers', 'those', "you've", "you'd", 'mightn', 'above', 'had', 'themselves', 'any', 'more', "hasn't", 'during', "doesn't", 'aren', 'these', 'hadn', 'whom', 'are', 'won', 'through', 'hasn', 'further', "don't", "wouldn't", "mightn't", 'too', 'why', 'itself', 'm', 'most', 'such', "you're", 'to', 'while', 'over', 'nor', 'ourselves', 'doing', 'they', "wasn't", 'been', 'shan', 'do', 'd', 'up', 'was', "didn't", 'some', "shouldn't", 'so', "it's", 'me', 'again', "should've", 'them', 'but', 'same', 'or', "aren't", 'her', 'below', 'wasn', 'be', "that'll", 'him', 'in', 'when', 'about', 'as', 'can', 'our', 'under', 'both', 'once', 'before', 'their', 'wouldn', 'here', 've', 'which', 'his', 'not', 'isn', 'theirs', 'only', 'its', 'we', 'of', 'you', "you'll", 'by', 'haven', "shan't", 'this', 'ours', 'yours', 't', 'your', 'into'}
filtered_words = [w for w in word_tk if not w in sw]
print("The text after removing stop words
")
print(filtered_words)
The text after removing stop words
['On', 'Wednesday', ',', 'Association', 'Computing', 'Machinery', ',', 'world', '’', 'largest', 'society', 'computing', 'professionals', ',', 'announced', 'Hinton', ',', 'LeCun', 'Bengio', 'year', '’', 'Turing', 'Award', 'work', 'neural', 'networks', '.', 'The', 'Turing', 'Award', ',', 'introduced', '1966', ',', 'often', 'called', 'Nobel', 'Prize', 'computing', ',', 'includes', '$', '1', 'million', 'prize', ',', 'three', 'scientists', 'share', '.']
Stemming
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
port_stem = PorterStemmer()
stemmed_words = []
for w in filtered_words:
stemmed_words.append(port_stem.stem(w))
print("Filtered Sentence:
", filtered_words, "
")
print("Stemmed Sentence:
", stemmed_words)
Filtered Sentence:
['On', 'Wednesday', ',', 'Association', 'Computing', 'Machinery', ',', 'world', '’', 'largest', 'society', 'computing', 'professionals', ',', 'announced', 'Hinton', ',', 'LeCun', 'Bengio', 'year', '’', 'Turing', 'Award', 'work', 'neural', 'networks', '.', 'The', 'Turing', 'Award', ',', 'introduced', '1966', ',', 'often', 'called', 'Nobel', 'Prize', 'computing', ',', 'includes', '$', '1', 'million', 'prize', ',', 'three', 'scientists', 'share', '.']
Stemmed Sentence:
['On', 'wednesday', ',', 'associ', 'comput', 'machineri', ',', 'world', '’', 'largest', 'societi', 'comput', 'profession', ',', 'announc', 'hinton', ',', 'lecun', 'bengio', 'year', '’', 'ture', 'award', 'work', 'neural', 'network', '.', 'the', 'ture', 'award', ',', 'introduc', '1966', ',', 'often', 'call', 'nobel', 'prize', 'comput', ',', 'includ', '$', '1', 'million', 'prize', ',', 'three', 'scientist', 'share', '.']
Lemmatizing
nltk.download('wordnet')
[nltk_data] Downloading package wordnet to /home/ericwei/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
True
from nltk.stem.wordnet import WordNetLemmatizer
lem = WordNetLemmatizer()
from nltk.stem.porter import PorterStemmer
stem = PorterStemmer()
lemm_words = []
for i in range(len(filtered_words)):
lemm_words.append(lem.lemmatize(filtered_words[i]))
print(lemm_words)
['On', 'Wednesday', ',', 'Association', 'Computing', 'Machinery', ',', 'world', '’', 'largest', 'society', 'computing', 'professional', ',', 'announced', 'Hinton', ',', 'LeCun', 'Bengio', 'year', '’', 'Turing', 'Award', 'work', 'neural', 'network', '.', 'The', 'Turing', 'Award', ',', 'introduced', '1966', ',', 'often', 'called', 'Nobel', 'Prize', 'computing', ',', 'includes', '$', '1', 'million', 'prize', ',', 'three', 'scientist', 'share', '.']
Parts of Speech Tagging
nltk.download('averaged_perceptron_tagger')
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /home/ericwei/nltk_data...
[nltk_data] Package averaged_perceptron_tagger is already up-to-
[nltk_data] date!
True
from nltk import pos_tag
pos_tagged_words = pos_tag(word_tk)
print(pos_tagged_words)
[('On', 'IN'), ('Wednesday', 'NNP'), (',', ','), ('the', 'DT'), ('Association', 'NNP'), ('for', 'IN'), ('Computing', 'VBG'), ('Machinery', 'NNP'), (',', ','), ('the', 'DT'), ('world', 'NN'), ('’', 'NNP'), ('s', 'RB'), ('largest', 'JJS'), ('society', 'NN'), ('of', 'IN'), ('computing', 'VBG'), ('professionals', 'NNS'), (',', ','), ('announced', 'VBD'), ('that', 'IN'), ('Hinton', 'NNP'), (',', ','), ('LeCun', 'NNP'), ('and', 'CC'), ('Bengio', 'NNP'), ('had', 'VBD'), ('won', 'VBN'), ('this', 'DT'), ('year', 'NN'), ('’', 'VBZ'), ('s', 'JJ'), ('Turing', 'NNP'), ('Award', 'NNP'), ('for', 'IN'), ('their', 'PRP$'), ('work', 'NN'), ('on', 'IN'), ('neural', 'JJ'), ('networks', 'NNS'), ('.', '.'), ('The', 'DT'), ('Turing', 'NNP'), ('Award', 'NNP'), (',', ','), ('which', 'WDT'), ('was', 'VBD'), ('introduced', 'VBN'), ('in', 'IN'), ('1966', 'CD'), (',', ','), ('is', 'VBZ'), ('often', 'RB'), ('called', 'VBN'), ('the', 'DT'), ('Nobel', 'NNP'), ('Prize', 'NNP'), ('of', 'IN'), ('computing', 'NN'), (',', ','), ('and', 'CC'), ('it', 'PRP'), ('includes', 'VBZ'), ('a', 'DT'), ('$', '$'), ('1', 'CD'), ('million', 'CD'), ('prize', 'NN'), (',', ','), ('which', 'WDT'), ('the', 'DT'), ('three', 'CD'), ('scientists', 'NNS'), ('will', 'MD'), ('share', 'NN'), ('.', '.')]
Frequency Distribution Plots
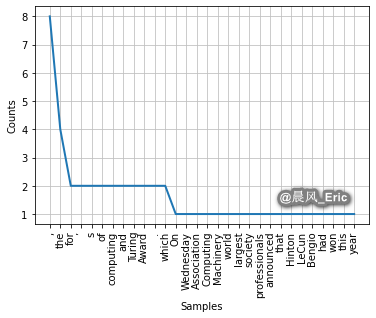
from nltk.probability import FreqDist
fd = FreqDist(word_tk)
print(fd)
<FreqDist with 56 samples and 76 outcomes>
import matplotlib.pyplot as plt
fd.plot(30, cumulative=False)
plt.show()
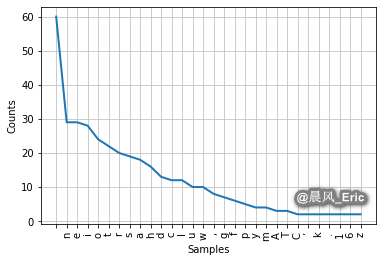
fd_alpha = FreqDist(text)
print(fd_alpha)
fd_alpha.plot(30, cumulative=False)
<FreqDist with 41 samples and 387 outcomes>
<AxesSubplot:xlabel='Samples', ylabel='Counts'>