当网络10.4.0.0发生故障时,RouterC检测到故障,并停止其E0接口的路由报文。 然而,路由器A和B还没有收到失败的通知。 路由器A仍然认为可以通过路由器B访问10.4.0.0。路由器A的路由表仍然反映出距离为2的网络10.4.0.0的路径。
由于RouterB的路由表指示到网络10.4.0.0的路由,因此RouterC认为路由器B具有通过路由器B的10.4.0.0网络的可行路径。路由器C更新其路由表以反映网络10.4.0.0的路径 跳数为2,如图3-10所示。
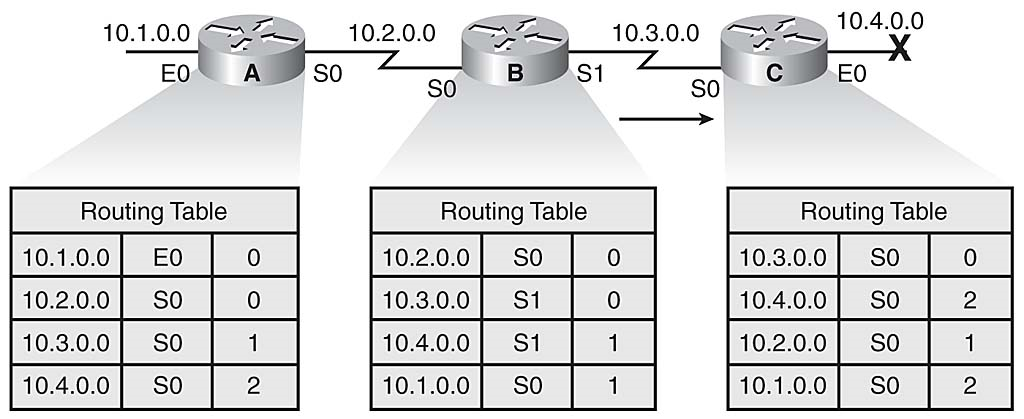
图3-10
路由器之间不一致的路由信息
路由器B从Router C接收到一个新的更新(3跳)。 路由器A从RouterB接收新的路由表,检测修改后的网络距离矢量为10.4.0.0,并将自己的距离向量重新计算为10.4.0.0,如图3-11所示。
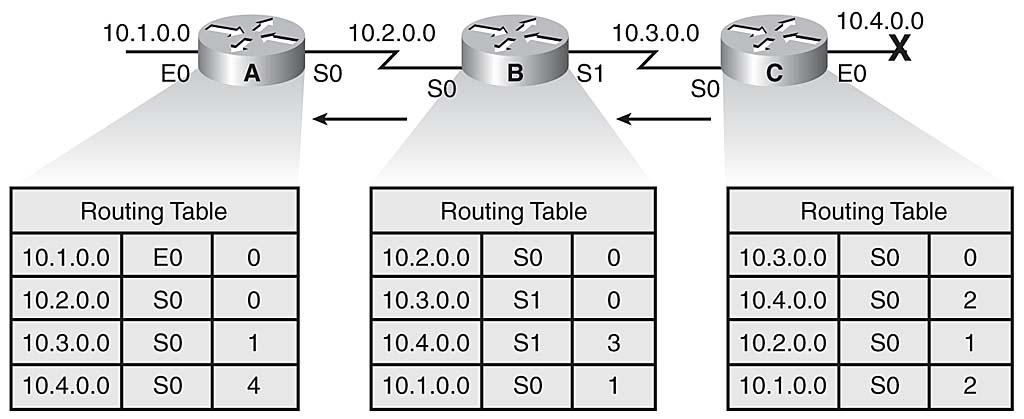
图3-11
数据不一致继续传播
因为路由器A,B和C的结论是,网络10.4.0.0的最佳路径是通过彼此,路由器A发往网络10.4.0.0的数据包在路由器B和C之间继续反弹,如图3-12所示。
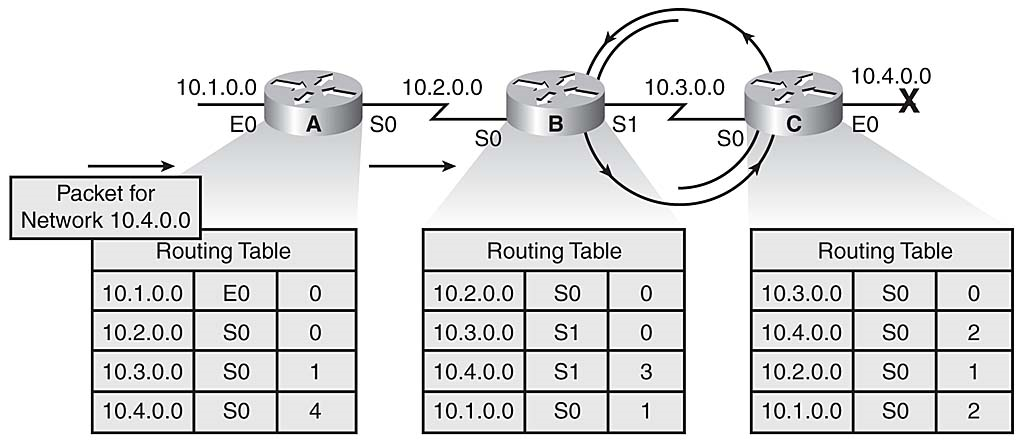
图3-12
路由循环存在错误跳数
继续图3-12中的示例,关于网络10.4.0.0的无效更新继续循环。 在其他一些进程可以停止循环之前,由于网络10.4.0.0关闭,路由器之间的路由器会相应地进行更新。
这种条件称为无穷计算,导致路由协议在设备之间来回连续地增加其度量和路由数据包,尽管目标网络10.4.0.0已经关闭。 当路由协议计数到无穷大时,无效信息导致路由回路存在,如图3-13所示。
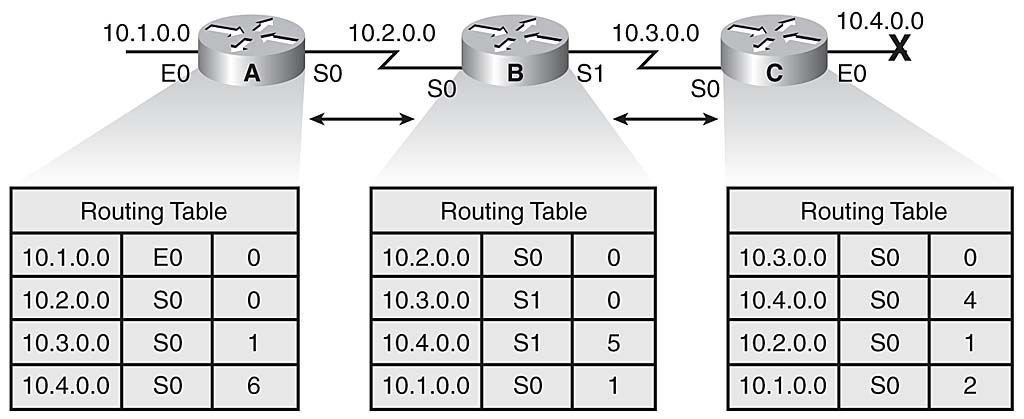
无穷计数情形
没有对策来停止此过程,每次路由更新广播到另一个路由器时,跳数的距离矢量递增。因为路由表中的信息不正确,导致数据包通过网络发送。 以下部分介绍了距离矢量路由协议用于防止路由环路无限期运行的对策。
以最大跳数设置排除路由循环
IP数据包通过IP报头中的生存时间(TTL)值具有固有的限制。 换句话说,路由器必须在每次获取数据包时至少将TTL字段减1。 如果TTL值为0,则丢弃该报文。 但是,这不会阻止路由器继续尝试将数据包发送到已关闭的网络。
为了避免长时间的问题,距离矢量协议定义无穷大为一些最大数量。 该数字是指路由度量,例如跳数。
使用这种方法,路由协议允许路由循环,直到度量超过其最大允许值。 图3-14显示了16跳的不可达值。 在度量值超过最大值后,网络10.4.0.0被认为是无法访问的。

图3-14最大跳数
预防路由环路与水平分割
消除路由环路并加快收敛的一种方法是通过称为水平分割的技术。 水平分割规则是从原始更新到来的方向发送关于路由的信息从未有用。 例如,图3-15说明了以下内容:
路由器B可以通过路由器C访问网络10.4.0.0。但是下面的做好毫无意义:路由器B向路由器C通知路由器B可以通过路由器C访问网络10.4.0.0。
如果路由器B通过路由到网络10.4.0.0的路由到路由器A,那么路由器A公布其从网络10.4.0.0到路由器B的距离就是无意义的。
没有替代路径到网络10.4.0.0,路由器B断定网络10.4.0.0是不可访问的。
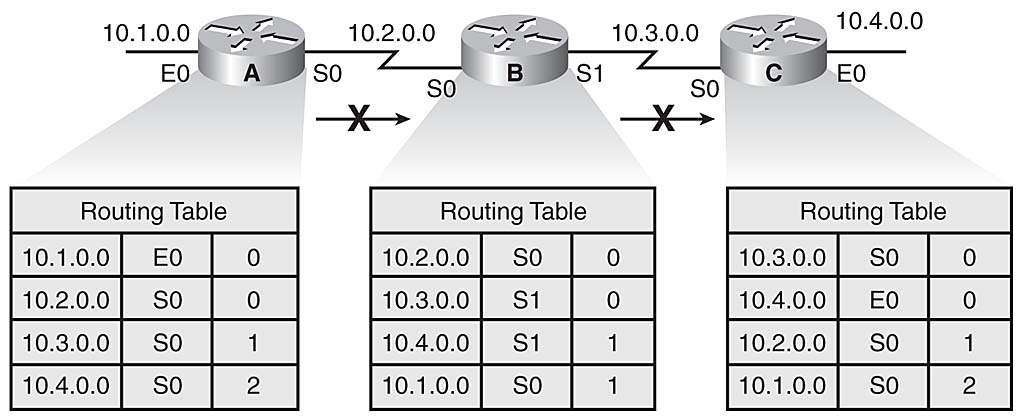
Split Horizon
Preventing Routing Loops with Route Poisoning
Another operation complementary to split horizon is a technique called route poisoning. Route poisoning attempts to improve convergence time and eliminate routing loops caused by inconsistent updates. With this technique, when a router loses a link, the router advertises the loss of a route to its neighbor device. Route poisoning enables the receiving router to advertise a route back toward the source with a metric higher than the maximum. The advertisement back seems to violate split horizon, but it lets the router know that the update about the down network was received. The router that received the update also sets a table entry that keeps the network state consistent while other routers gradually converge correctly on the topology change. This mechanism allows the router to learn quickly of the down route and to ignore other updates that might be wrong for the hold-down period. This prevents routing loops.
Figure 3-16 illustrates the following example. When network 10.4.0.0 goes down, Router C poisons its link to network 10.4.0.0 by entering a table entry for that link as having infinite cost (that is, being unreachable). By poisoning its route to network 10.4.0.0, Router C is not susceptible to incorrect updates from neighboring routers, which may still have an outdated entry for network 10.4.0.0.
{kind=link}
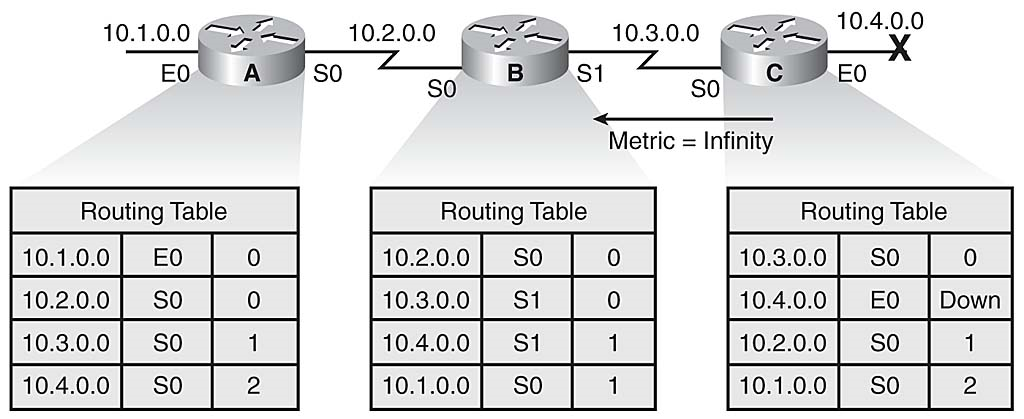
Route Poisoning
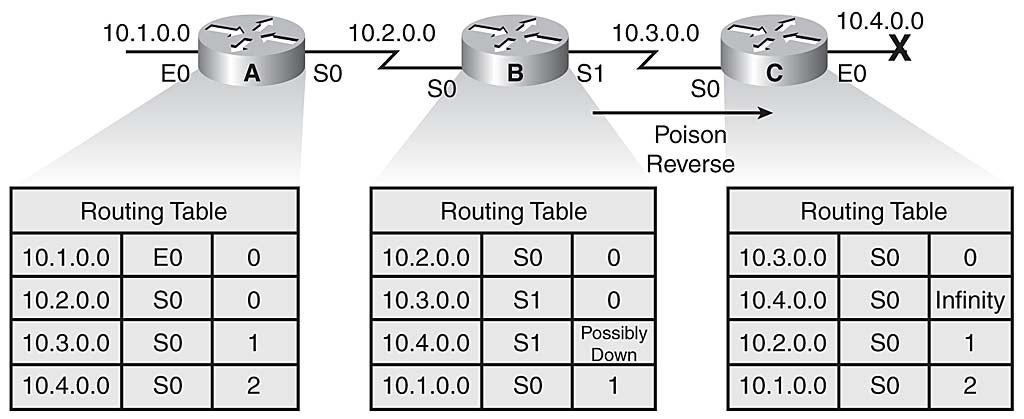
When Router B sees the metric to 10.4.0.0 jump to infinity, it sends an update called a poison reverse to Router C, stating that network 10.4.0.0 is inaccessible, as illustrated in Figure 3-17. This is a specific circumstance overriding split horizon, which occurs to make sure that all routers on that segment have received information about the poisoned route.
{kind=link}
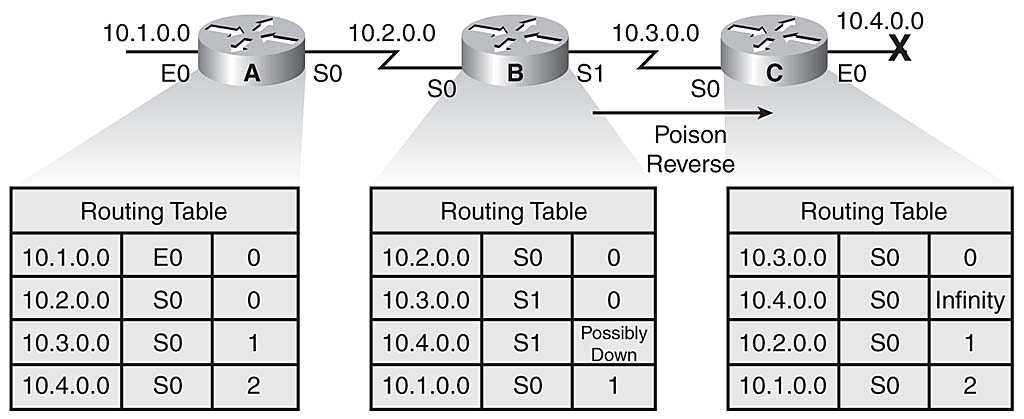
Poison Reverse
Route Maintenance Using Hold-Down Timers
Hold-down timers prevent regular update messages from inappropriately reinstating a route that might have gone bad. Hold-downs tell routers to hold any changes that might affect routes for some period of time. The hold-down period is usually calculated to be just greater than the time necessary to update the entire network with a routing change.
Hold-down timers perform route maintenance as follows:
-
When a router receives an update from a neighbor indicating that a previously accessible network is now inaccessible, the router marks the route as inaccessible and starts a hold-down timer.
-
If an update arrives from a neighboring router with a better metric than originally recorded for the network, the router marks the network as accessible and removes the hold-down timer.
-
If at any time before the hold-down timer expires, an update is received from a different neighboring router with a poorer metric, the update is ignored. Ignoring an update with a higher metric when a holddown is in effect enables more time for the knowledge of the change to propagate through the entire network.
-
During the hold-down period, routes appear in the routing table as "possibly down."
Figure 3-18 illustrates the hold-down timer process.
{kind=link}
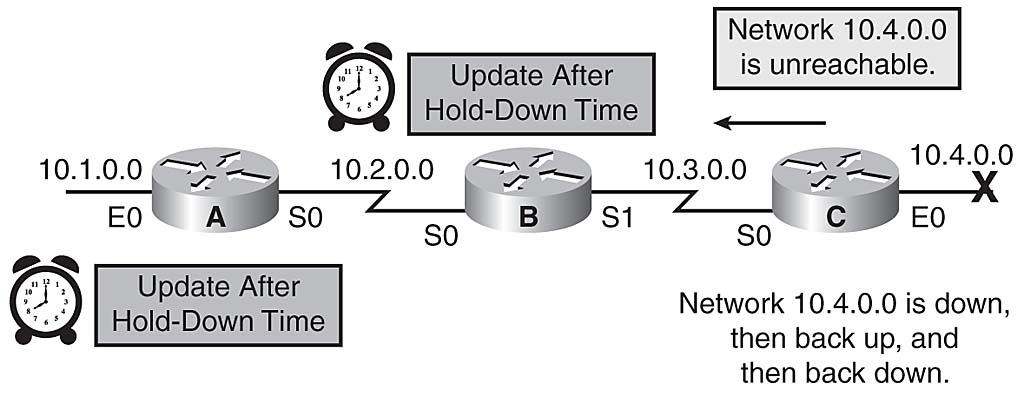
Hold-Down Timers
Route Maintenance Using Triggered Updates
In the previous examples, routing loops were caused by erroneous information calculated as a result of inconsistent updates, slow convergence, and timing. If routers wait for their regularly scheduled updates before notifying neighboring routers of network catastrophes, serious problems can occur, such as loops or traffic being dropped.
Normally, new routing tables are sent to neighboring routers on a regular basis. A triggered update is a new routing table that is sent immediately, in response to a change. The detecting router immediately sends an update message to adjacent routers, which, in turn, generate triggered updates notifying their adjacent neighbors of the change. This wave propagates throughout the portion of the network that was using the affected link. Figure 3-19 illustrates what takes place when using triggered updates.
{kind=link}
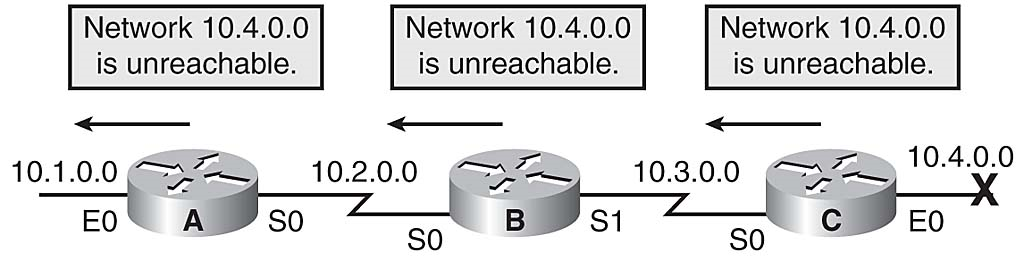
Triggered Updates
Triggered updates would be sufficient with a guarantee that the wave of updates reached every appropriate router immediately. However, two problems exist:
-
Packets containing the update message can be dropped or corrupted by some link in the network.
-
The triggered updates do not happen instantaneously. A router that has not yet received the triggered update can issue a regular update at just the wrong time, causing the bad route to be reinserted in a neighbor that had already received the triggered update.
Coupling triggered updates with holddowns is designed to get around these problems.
Route Maintenance Using Hold-Down Timers with Triggered Updates
Because the hold-down rule says that when a route is invalid, no new route with the same or a higher metric will be accepted for the same destination for some period, the triggered update has time to propagate throughout the network.
The troubleshooting solutions presented in the previous sections work together to prevent routing loops in a more complex network design. As depicted in Figure 3-20, the routers have multiple routes to each other. As soon as Router B detects the failure of network 10.4.0.0, Router B removes its route to that network. Router B sends a trigger update to Routers A and D, poisoning the route to network 10.4.0.0 by indicating an infinite metric to that network.
{kind=link}
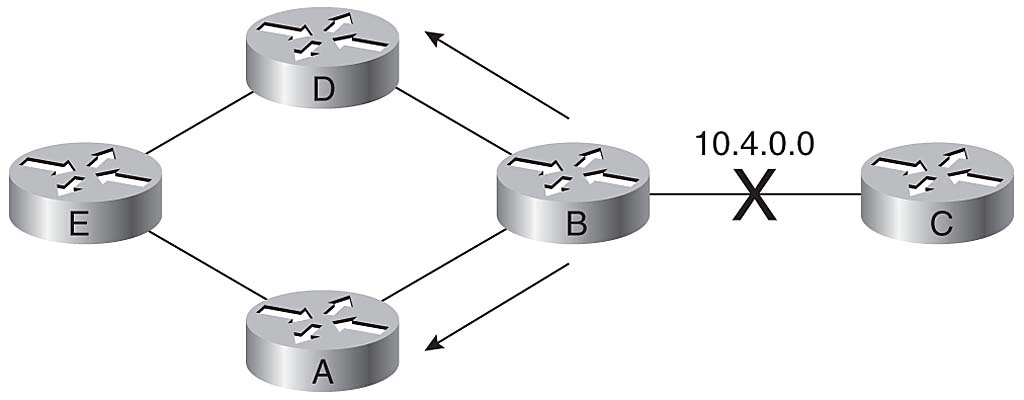
Implementing Multiple Solutions
Routers D and A receive the triggered update and set their own hold-down timers, noting that the 10.4.0.0 network is "possibly down." Routers D and A, in turn, send a triggered update to Router E, indicating the possible inaccessibility of network 10.4.0.0. Router E also sets the route to 10.4.0.0 in holddown. Figure 3-21 depicts the way Routers A, D, and E implement hold-down timers.
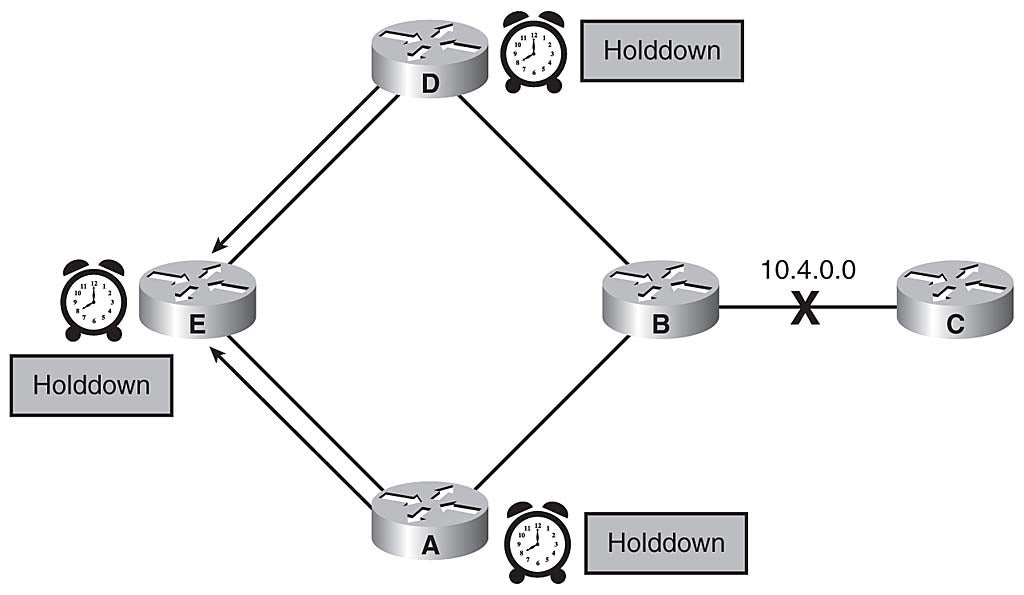{kind=link}
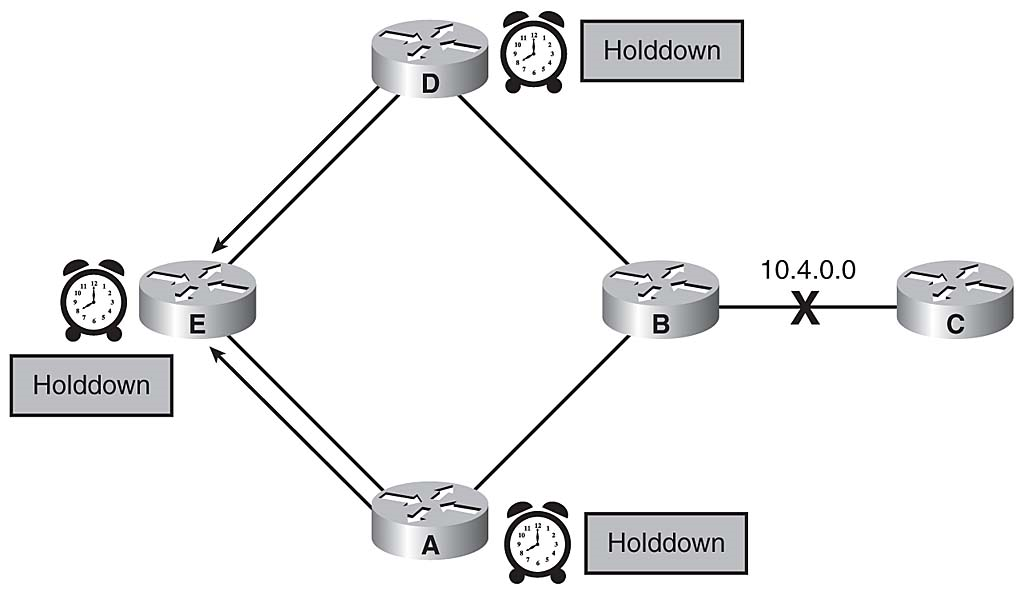
Route Fails
Router A and Router D send a poison reverse to Router B, stating that network 10.4.0.0 is inaccessible. Because Router E received a triggered update from Routers A and D, it sends a poison reverse to Routers A and D. Figure 3-22 illustrates the sending of poison reverse updates.
{kind=link}
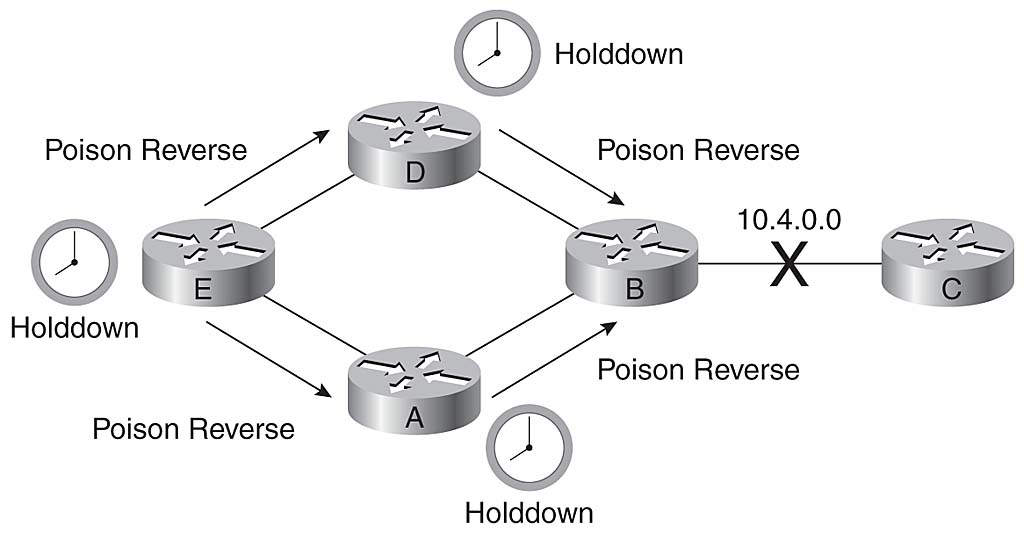
Route Holddown
Routers A, D, and E will remain in holddown until one of the following events occurs:
-
The hold-down timer expires.
-
Another update is received, indicating a new route with a better metric.
-
A flush timer, which is the time a route will be held before being removed, removes the route from the routing table.
During the hold-down period, Routers A, D, and E assume that the network status is unchanged from its original state and attempt to route packets to network 10.4.0.0. Figure 3-23 illustrates Router E attempting to forward a packet to network 10.4.0.0. This packet will reach Router B. However, because Router B has no route to network 10.4.0.0, Router B will drop the packet and return an Internet Control Message Protocol (ICMP) network unreachable message.
{kind=link}
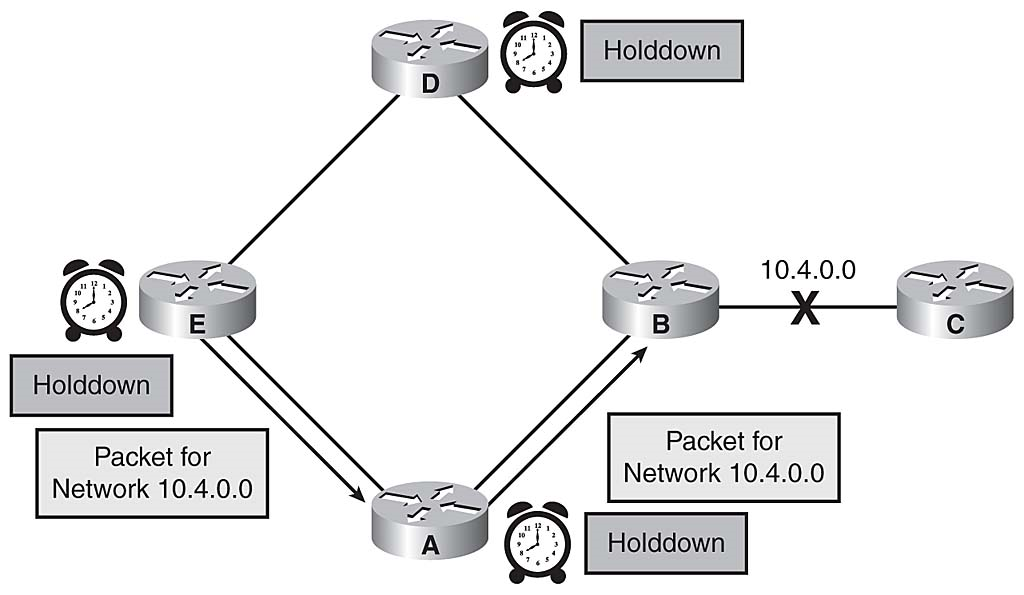
Packets During Holddown
When the 10.4.0.0 network comes back up, Router B sends a trigger update to Routers A and D, notifying them that the link is active. After the hold-down timer expires, Routers A and D add route 10.4.0.0 back to the routing table as accessible, as illustrated in Figure 3-24.
{kind=link}
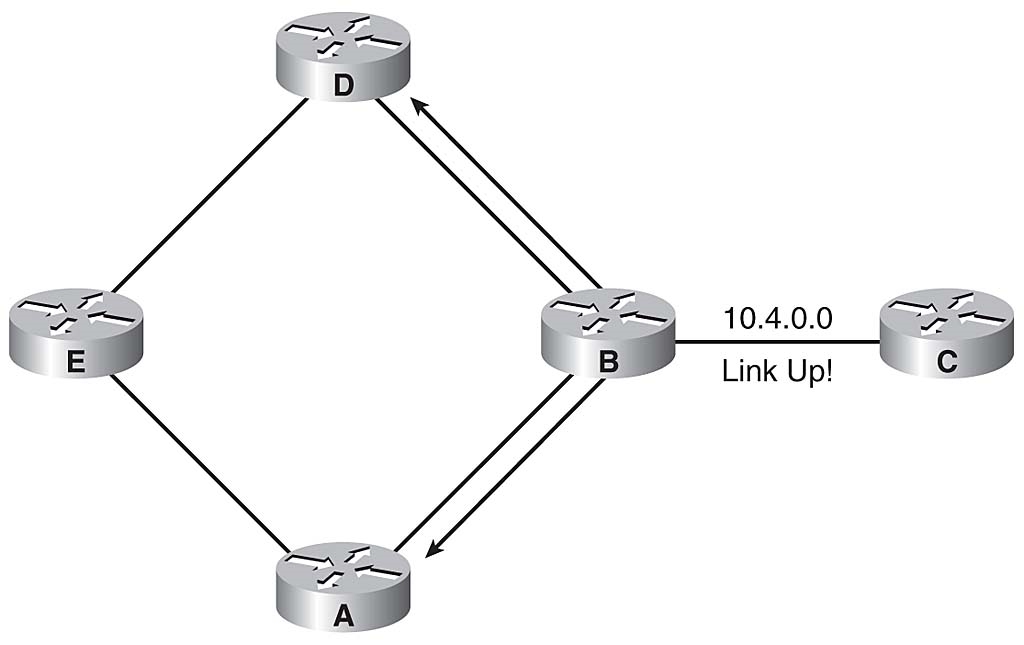
Network Up
Routers A and D send Router E a routing update stating that network 10.4.0.0 is up, and Router E updates its routing table after the hold-down timer expires, as illustrated in Figure 3-25.
{kind=link}
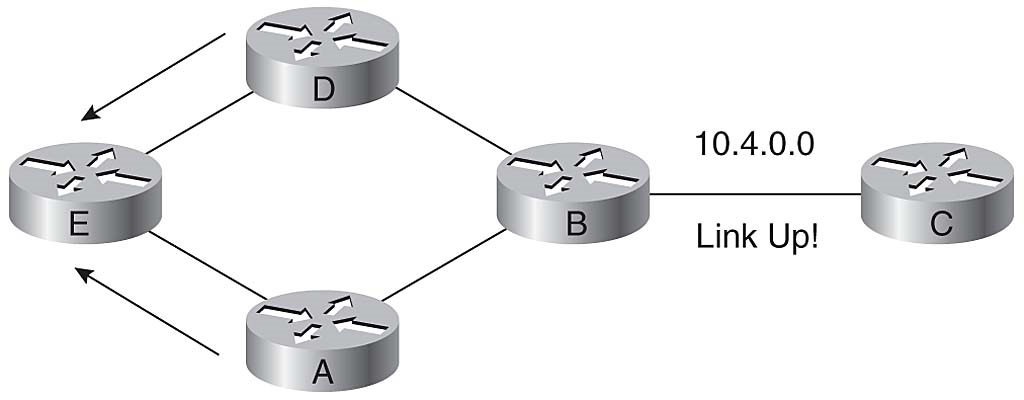
Network Converges
Link-State and Advanced Distance Vector Protocols
In addition to distance vector–based routing, the second basic algorithm used for routing is the link-state algorithm. Link-state protocols build routing tables based on a topology database. This database is built from link-state packets that are passed between all the routers to describe the state of a network. The shortest path first algorithm uses the database to build the routing table. Figure 3-26 shows the components of a link-state protocol.
{kind=link}
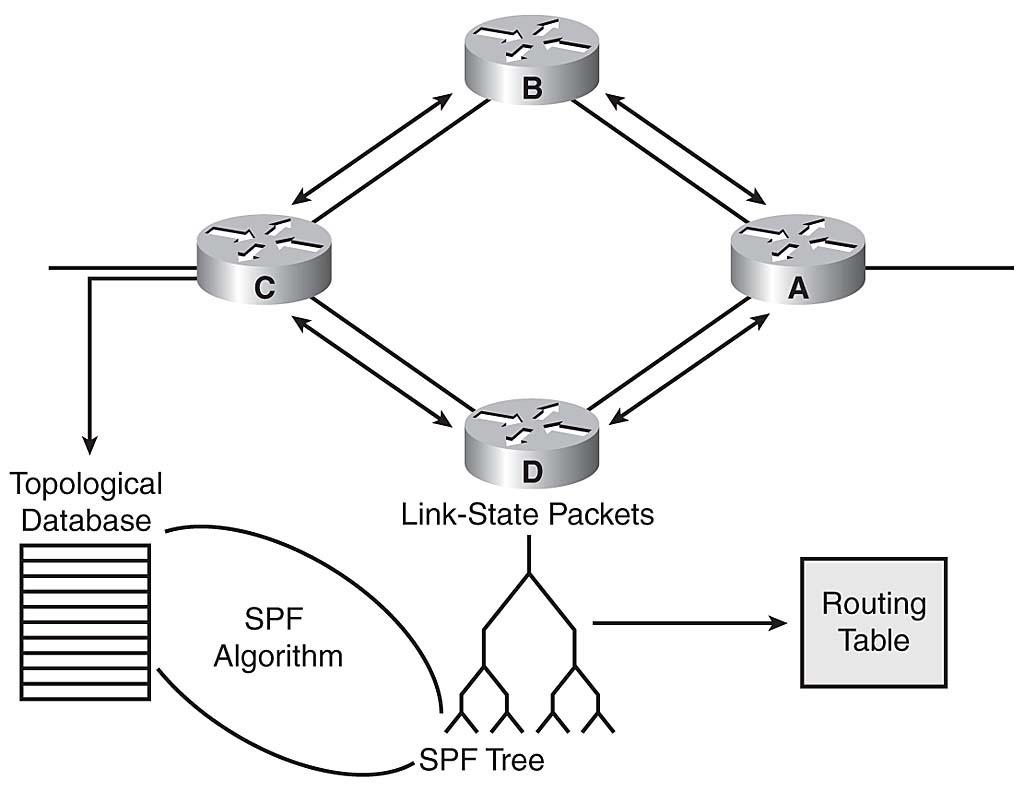
Link-State Protocols
Understanding the operation of link-state routing protocols is critical to being able to enable, verify, and troubleshoot their operation.
Link-state-based routing algorithms—also known as shortest path first (SPF) algorithms—maintain a complex database of topology information. Whereas the distance vector algorithm has nonspecific information about distant networks and no knowledge of distant routers, a link-state routing algorithm maintains full knowledge of distant routers and how they interconnect.
Link-state routing uses link-state advertisements (LSA), a topological database, the SPF algorithm, the resulting SPF tree, and, finally, a routing table of paths and ports to each network.
Open Shortest Path First (OSPF) and Intermediate System-to-Intermediate System (IS-IS) are classified as link-state routing protocols. RFC 2328 describes OSPF link-state concepts and operations. Link-state routing protocols collect routing information from all other routers in the network or within a defined area of the internetwork. After all the information is collected, each router, independently of the other routers, calculates its best paths to all destinations in the network. Because each router maintains its own view of the network, it is less likely to propagate incorrect information provided by any one particular neighboring router.
Link-state routing protocols were designed to overcome the limitations of distance vector routing protocols. Link-state routing protocols respond quickly to network changes, send triggered updates only when a network change has occurred, and send periodic updates (known as link-state refreshes) at long intervals, such as every 30 minutes. A hello mechanism determines the reachability of neighbors.