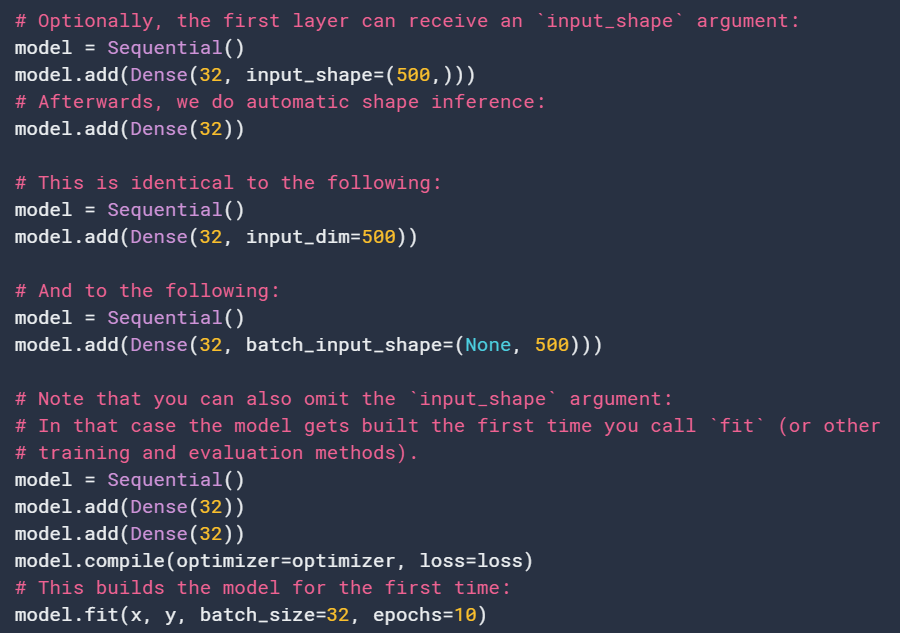
有两种方法初始化Model:
1. 利用函数API,从Input开始,然后后续指定前向过程,最后根据输入和输出来建立模型:

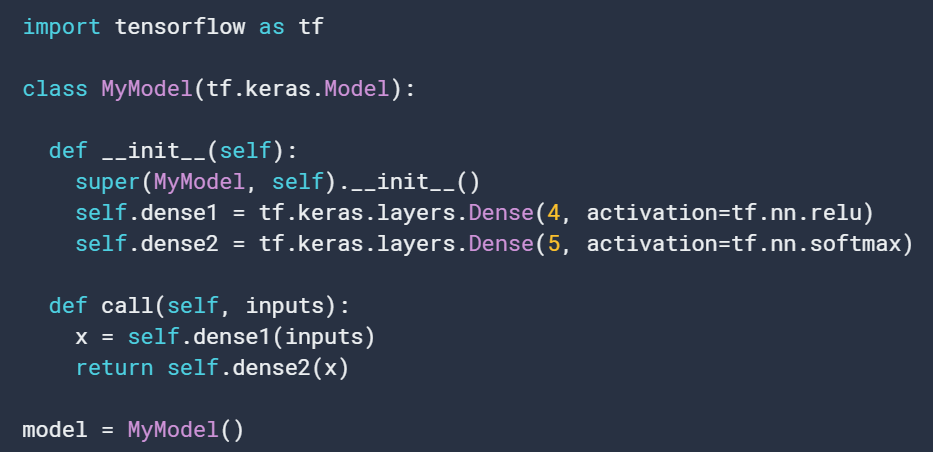
2. 通过构建Model的子类来实现:类似于pytorch的nn.Module:通过在__init__中定义层的实现,然后再call函数中实现前向过程:
方法:
1. compile
用于配置模型训练

optimizer: string型优化器名,tf.keras.optimizers.
loss:string型函数名,目标函数或tf.keras.losses.Loss ,目标函数需为:scalar_loss = fn(y_true, y_pred)。如果模型有多个输出,可以在每个outpu利用不同的损失通过传递一个字典或者列表loss。
metric:在训练和测试中用到的度量方法。典型的可以用metrics=['accuracy']。对于多输出情况可以传递一个字典:metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}。也可以传递一个列表(长度得和输出的长度一致):metrics=[['accuracy'], ['accuracy', 'mse']] or metrics=['accuracy', ['accuracy', 'mse']].
loss_weights:可选。格式为列表或字典,来对不同损失进行加权。最终的loss将会是这些损失的加权和。
sample_weight_mode: 如果需要实现时序模式的加权,可以设为’temporal‘,默认为None。如果model有多个输出,可以利用不同的sample_weight_mode在不同的输出上。
weightd_metrics: 有许多评估方法metrics组成的列表,由sample_weight或者class_weight来进行加权。
target_tensors:默认情况下keras将会为模型traget创建placeholders,就是在训练时为target位置放入数据。如果希望利用自己的target tensor,可以利用该参数。可以是单tensor(单输出情况),也可以是tensor列表或者字典映射。
distribute:TF2不支持。
2. evaluate

x: 输入数据,可以是numpy数组(或列表numpy表示多输入)、可以实tf tensor(或列表tensor)、可以是字典、可以是tf.data数据集、可以是生成器或者keras.utils.Sequence实例
y:目标数据。类似x。
batch_size: 整数或None。不指定则默认为32。符号tensor,dataset,generator、 keras.utils.Sequence实例的情况下不要指定该参数。
verbose:0或1。Verbosity mode. 0 = silent, 1 = progress bar.
sample_weight: 用于在损失函数中进行加权,可选。
step:整数或None。开始评估前所需要的步数。
callbacks: keras.callbacks.Callback 列表实例。
max_queue_size: 整数,仅对于输入是生成器或keras.utils.Sequence 时使用。生成器队列的最大尺寸。不指明则默认为10.
workers: 整数,仅对于输入是生成器或keras.utils.Sequence 时使用。使用基于进程的线程时要启动的最大进程数。默认为1.
use_multiprocessing:布尔。仅对于输入是生成器或keras.utils.Sequence 时使用。
3. fit
迭代训练模型
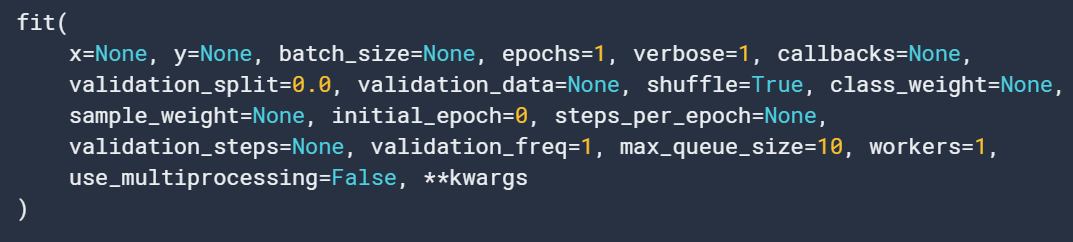
前几个参数用法同上。
validation_split:位于0-1之间的浮点数。划分一定比例的数据用于验证。这部分数据将不会用于训练。选取时将会采用x和y中shuffle前的最后样本。
validation_data:模型将会在这上面进行验证,不参与训练。指定后将会覆盖validation_split 参数,格式为:

class_weight: 可选。字典格式:将类索引(整数)映射到权重(浮点)值,用于加权损失函数(仅在训练期间)。这有助于告诉模型“更加关注”来自表示不足的类的样本。
steps_per_epoch:整数或None。周期中迭代次数。训练数据是类似于tf的tensor时默认情况就是数据大小/批量大小。当x是tf.data时不指定该参数则周期迭代直到输入数据被遍历完。
validaton_steps:仅当有validation_data时有效。
validation_freq:仅当有validation_data时有效。整数则表示在进行新的验证前需要训练多少个epoch。validation_freq=[1, 2, 10]则表示在第1,2,10个epoch之后进行验证。
4. get_layer
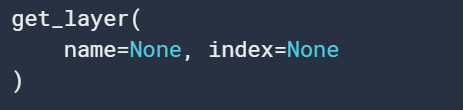
根据名字或索引来检索一个layer。如果都提供的话,先考虑index。索引基于水平图遍历的顺序(自下而上)。
5. load_weights

从TF或HDF5权重文件中载入权重。 如果by_name为False,则根据网络拓朴来载入权重,这意味着网络结构应与保存的权重一致。不包含权重的层不考虑在网络结构中,所以添加或移除这些层不影响。如果by_name为True,仅仅有相同名字的层权重会被载入。这对于微调或者迁移模型中需要改变一些层的操作是有用的。当by_name=False时仅仅tf格式的权重是支持的。注意到从tf和HDF5中load操作有细微不同。HDF5基于展平的权重列表,而TF是基于在model中定义的层的名字。skip_mismatch为布尔,仅在by_name=True时有效:对于形状或数目不能匹配的层进行略过。
6. predict

对输入样本进行预测,参数和前面基本一致。
7. predict_on_batch
对于单一的批量进行预测。x的要求和前面一样。
8. reset_metrics和reset_states:重置metrics的状态、重置state。
9. save

保存模型到tf或HDF5文件中。要保存的文件savefile包括:

保存的模型可以通过keras.models.load_model. 载入。有load_model返回的模型是是一个已编译的模型,可以使用(除非保存的模型从未编译过)。由Sequential和函数API构建的模型可以保存为HDF5和SavedModel格式。子类模型可以仅可被保存为 SavedModel格式。
参数save_format:可以为r 'tf' or 'h5', 在TF2中默认为tf,TF1中默认为h5.
signature仅在’tf‘格式中可用。
10. save_weights

保存所有层的权重,save_format可以指定村委HDF5或TF格式。 当村委HDF5格式时,权重文件需要有:

存为TF格式时,网络引用的所有对象都以与tf.train.Checkpoint相同的格式保存,包括分配给对象属性的任何层实例或优化器实例。对于使用tf.keras.Model(inputs,outputs)构建的网络,网络使用的层实例将被自动跟踪/保存。对于从tf.keras.Model继承的用户定义类,必须将层实例分配给对象属性,通常在构造函数中。详见tf.train.Checkpoint和tf.keras.Model文档。
虽然格式相同,但不要混合使用save_weights和tf.train.Checkpoint。Model.save_weights保存的检查点应使用Model.load_weights加载。使用tf.train.Checkpoint.save保存的检查点应使用相应的tf.train.Checkpoint.restore还原。
TensorFlow格式从根对象开始匹配对象和变量,self表示save_weights,贪婪地匹配属性名。对于Model.save是模型,对于Checkpoint.save是检查点,即使检查点附加了模型。这意味着,使用save_weights保存tf.keras.Model并加载到tf.train.Checkpoint中,同时附加一个模型(反之亦然),将与模型的变量不匹配。有关TensorFlow格式的详细信息,请参阅guide to training checkpoints。
11. summary

打印网络信息。positions:每行日志元素的相对或绝对位置。如果未提供,则默认为[.33、.55、.67、1.]。
12. test_on_batch

如果reset_metrics=True,则metrics仅在该批量中返回。False则将度量将有状态地根据批量累积。
13. to_json和to_yaml
返回不同格式的网络信息。可以分别利用 keras.models.model_from_yaml(yaml_string, custom_objects{}).、 keras.models.model_from_json(json_string, custom_objects={})来载入网络中。
14. train_on_batch

在单一批量数据上进行单次梯度更新。返回训练loss。
tf.keras.Sequential
方法基本和Model一样。