近来论文看了许多,但没多少时间总结下来。今天暂时记录一篇比较旧的论文,选择理由是 Discriminative features。
做图像说白了就是希望有足够有判别性的特征,这样在分类或者匹配、检索的时候才能有较好的精度。
一. 综述
这篇论文思想很简单。如何称之为有判别性的特征?作者利用编码器的思想,对于同一ID的图形的特征,如果编码后仍可以较好的解码为同一ID的特征,那么我们就说这个特征有判别力。这里有个点值得注意:编码器是针对图像特征,非图像本身。好的特征表示大概有2个衡量标准:可以很好的重构出输入数据、对输入数据一定程度下的扰动具有不变性。普通的autoencoder、sparse autoencoder、stacked autoencoder则主要符合第一个标准,而deniose autoencoder和contractive autoencoder则主要体现在第二个。在一些分类任务中,第二个标准显得更加重要。
二. 摘要
编码器一般用在非监督领域,这里将编码器加在监督学习里,为了学得的特征有好的判别性。这里利用编解码器来重建同一label的个体的特征。这样做是为了最小化类内方差。
三. 介绍
有许多重建模型算法:DAE(denoising auto-encoder)、CAE(contractive auto-encoder)。但这些算法都是在非监督领域,为了获得更有判别性的特征还得是监督学习。所以作者将编码器思想与监督学习(softmax传统监督分类)结合到了一起。此外作者指出AE对于图像变换不够鲁棒。传统AE限于小图、对齐的简单图像。作者提出class-encoder作为softmax classifier的一个限制项(辅助),从而优于纯softmax。
结构如下:
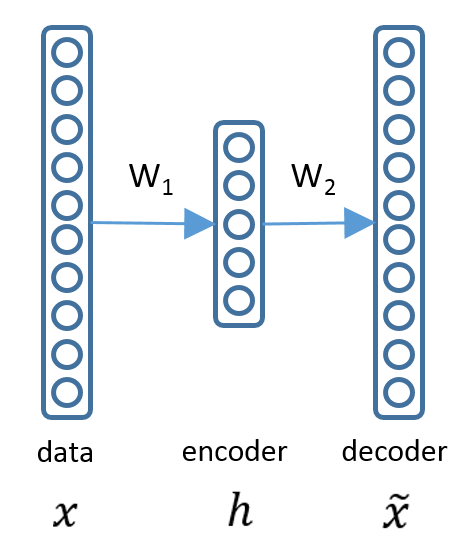
x为输入数据(特征),h为隐层,xhat为重构(同一label的特征)。那么最小化重构损失即可:
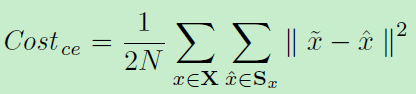
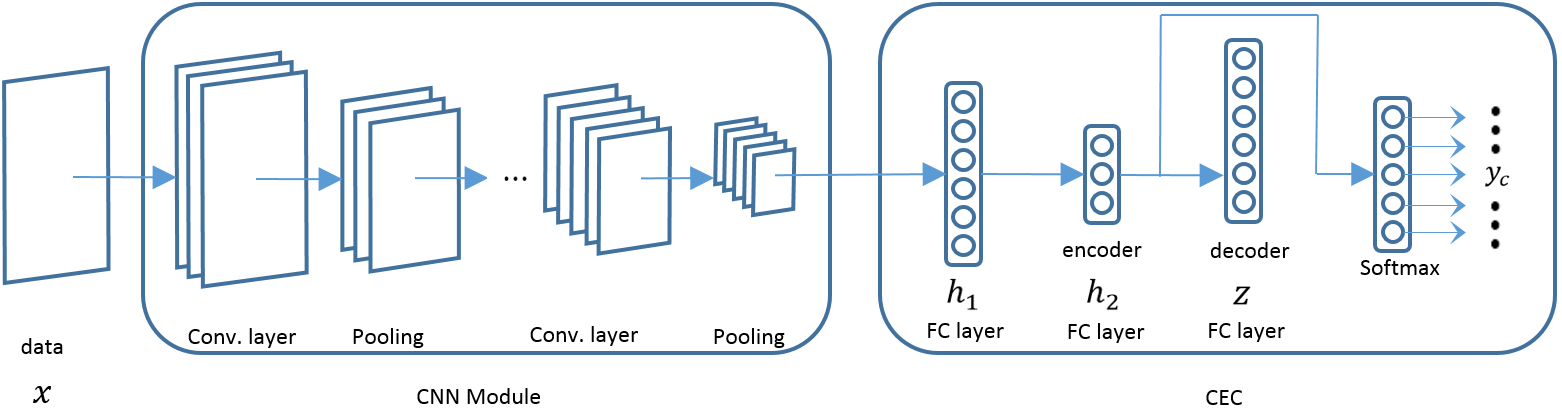
所以整体模型即为两支路:利用编码器优化特征、利用softmax分类:
同样,作者验证隐层一层就够好,但是隐层神经元数目不同结果也不同:
最终实验验证了加上编码器的softmax要优于纯softmax。有个点是:作者采取了一层卷积和两层局部连接层 two locally-connected layers,类似于卷积,但是层间不共享参数。因此它适用于提取一组有规律的图像:例如人脸。
四. 结论
该模型只用到了类内的对,也就是正样本对,没有用到任何不匹配对。而其他算法(DeepID2)同时利用了正负对,这说明负对的贡献在训练中是比较小的。类内重建是有助于学习鲁棒、有判别性的特征。在特征层面上的策略很好解决了FC net的上的尺寸以及变换问题。
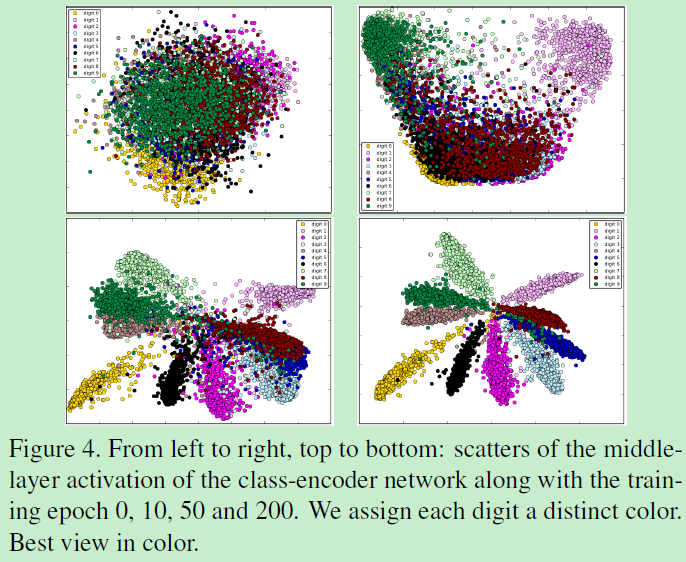
附:特征向量feature embedding:每列为同一ID:
