一篇BMVC18的论文,关于semantic keypoints matching、dense matching的工作,感觉比纯patch matching有意思,记录一下。
1. 摘要
提出一种针对correspondence matching的直接解决方案。没有采用一贯的基于正负样本对(一般需要困难负样本挖掘)的解决方案,本文提出了一种相似性热图生成器(similarity heatmap generator )来直接处理。对于所有query points直接在目标图像中生成相似性热图。结果大部分做到了SOTA。
2. 介绍
Correspondence search在好多领域都很重要。这一任务可以有很多变体:finding exact matches, e.g., in stereo matching, to finding semantic correspondence。早期工作肯定依赖于SIFT,SURF,近来都用siamese net做,例如用预训练VGG做image-to-image semantic keypoint matching ,其共同点都是要不利用一个matching 框架或在描述子空间搜索最近邻。然而作者认为这些工作都没有直接针对精确对应点定位而训练。
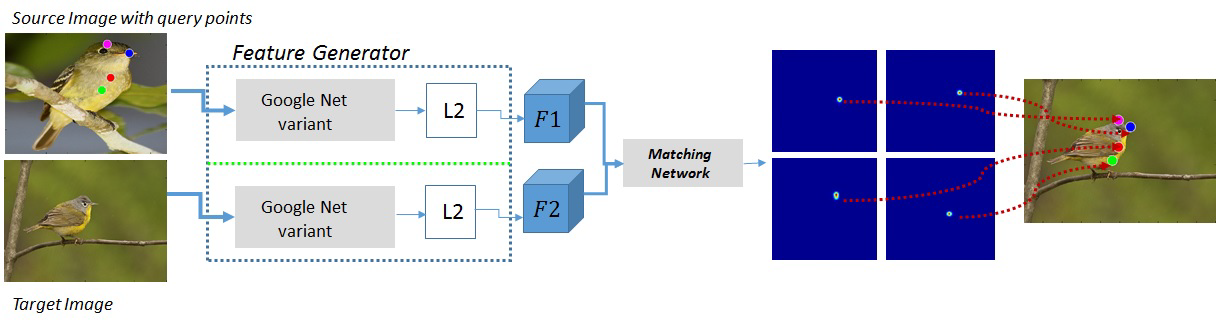

作者以精确对应匹配为目标,端到端搭建了包括feature generator和match network两个组成部分的网络。heatmap的峰值就是目标图像的位置。heatmaps based representation可以实现 N-pairs based metric learning, 也即无需困难负样本采样。
本文的框架可以用来预测稀疏抑或稠密的视觉对应关系。利用多类分类损失来训练网络,且不含有spatial transformer layers。且我们的方法直接在raw images上操作,不需region proposals。评估数据集有:PF-Pascal , PF-Willow , Pascal-Parts , the KITTI-Flow 2015 [19] and MPI Sintel [4] datasets 。网络trained from sctatch。
总结贡献如下:
- 提出一个端到端的方法来解决correspondence search问题。
- 所提出的matching network可以被扩展到任何标准的深度网络来端到端解决精确对应匹配问题。
- 基于热图的表示enables N-pairs based metric learning,且无需困难负样本采样(triplet、contrastive divergence based metric learning)。
3. 相关工作
Correspondence search是一个CV中的基础问题,早期有SIFTSURFDAISY。接着Siamese net被用来patch similarity、face embedding、stereo matching,又有人利用预训练的net来做semantic correspondence search。利用triplet loss做fine-grained 图像ranking。又有Siamese net利用内积layer和多分类loss 做高效视差估计。尽管表现都很好,但之前的方法都是估计patch-patch或patch-image相似性,且对于多关键点的匹配相似性需要训练测试时多次前向传播。

![]()
近来的方法,基于image-image的semantic keypoints matching被提出。Choy提出的“Universal Correspondence Network”+spatial transformer layers利用metric learning方法高效训练,对于匹配多个关键点在预测时需要一次单向传播。然而因为是metric learning,需要额外的困难负样本挖掘。所以额外引入了distance measure和k近邻超参数。与之相比我们提出的端到端网络不需困难负样本挖掘。Kim提出了一个全卷积自相似性描述子对于稠密语义关键点匹配,然鹅他们的方法仍需要在顶端利用matching framework来实现对应关系。相比我们的方法是self contained且直接预测correspondences。【10】提出利用appearances和geometry匹配一对图像中的region proposals。我们的方法只需要利用appearances,无需region proposals。
我们思路来源于论文Improved Deep Metric Learning with Multi-class N-pair Loss Objective。文中提出了N-pairs loss,比contrastive divergence和triplet loss实现了更好的结果。然而他们的方法是为了实现patched based matching。而本文利用N-pairs loss是为了解决key points matching。
4. Correspendence Search
解释Correspendence Search:给定source image I1,I1中有query points pn,此外目标target image I2,目标很明确就是要找target image中与I1中每个关键点匹配的关键点qn。框架如图1,包括feature generator和matching network。
feature generator即以source image I1和target image I2为输入,生成特征F1和F2。matching network以F1、F2为输入生成N个相似性热图,对于N个query points而言。
1) Feature Generator
如图1,两个siamese分支都是feature generator,包含了两份google-net拷贝。输入图片,输出特征图F1,F2。
2) Matching Network
用来生成peaked similarity热图,对于目标image中的每个query point而言。训练时最小化预测的相似图与gt的差异,无需困难负样本挖掘,因为这个网络已将其作为训练的一部分来产生所有query point的负样本的不相似特征。网络结构在图2。包含一系列简单层,无可训练参数。图很直观了,不多做解释。
从图2可以看到matching network主要有7个操作:Crop layer、Reshape R1、Copy、Reshape R2、Dot Product、SoftMax、Reshape R3。很好理解,这里直接粘过来:

内积操作就是对两个特征处理结果的结合:
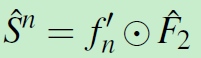
内积层高效计算每个cropped特征与F2中的每个特征的相似度。

训练:
为每个query point赋ground truth:

训练样本:![]()
最小化预测S与真值S之间的交叉熵损失:

测试:
为每个query点pn预测一个对应的匹配点qn:
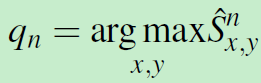
qn即为所预测的相似度图中的峰值peak。在定位peak之前利用bilinear-sampling来上采样相似度图。
5. 实验
在semantic keypoints matching 和 dense matching两个任务上做实验。
1)semantic keypoints matching
数据集:PF-PASCAL [9], PF-Willow [9] and Pascal-Parts [30] datasets
评价指标:PCK

2)dense correspondences
数据集: KITTI-Flow 2015 [19] and MPI Sintel [4] benchmarks
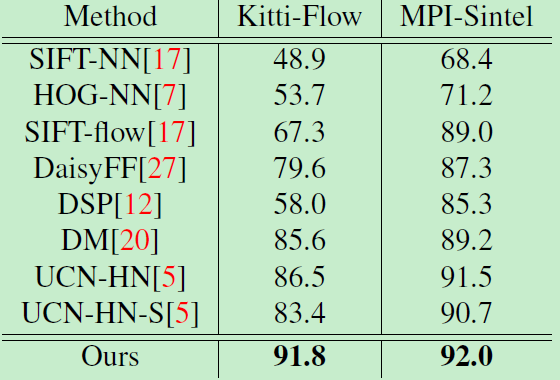
DAISY [27], DSP [12], and DM [20],这些传统方法 应用 global optimization作为预处理步骤,实现了更精准的对应。本文没有采用任何预处理,和spatial transformer layers,没有明显的过拟合。达到了SOTA。