1.需求:
1. 点击 排行榜

2. 单击右边分类排行榜中,任意一个分类。如 喜剧。
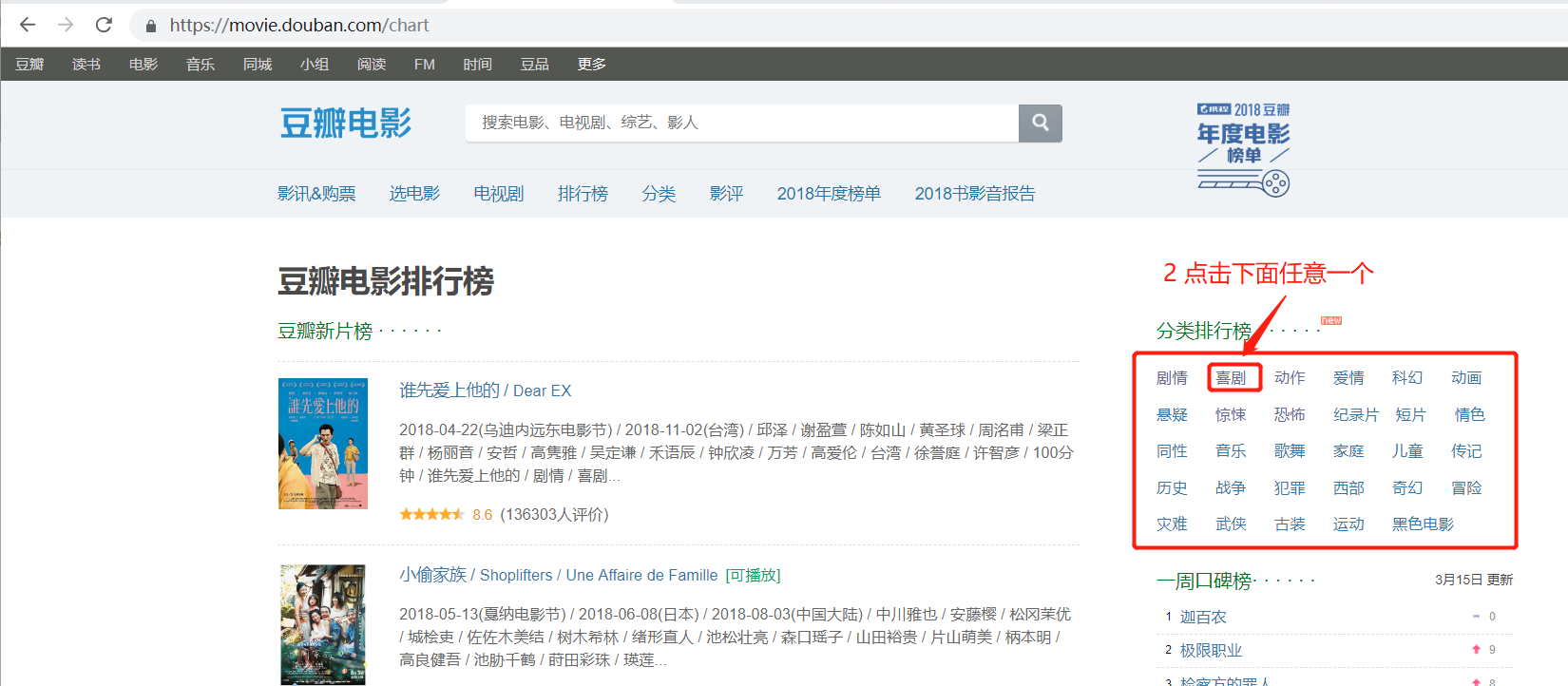
3.进入了喜剧片 页面。 该页面为数据动态加载页面 。拉滚动条到底部,数据会新加载一部分。要求是把该分类
(喜剧)下的所有电影信息爬取出来。 最后把每个分类下的所有电影信息也爬取下来。

2.爬取豆瓣动态数据,页面特点分析:
1. ajax -get 请求,获取数据
2. 拉滚动条到底部才加载新的数据
3. ajax -get 请求,response 返回的是一个json 类型数据,要的数据在其中。
4. ajax-get 的参数 变化。 params ,通过改变参数,得到不同类型的数据。
特点具体分析:
1. 进入 : https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
先空network 下所有请求,后在该地址回车,可以得到3个ajax 请求。
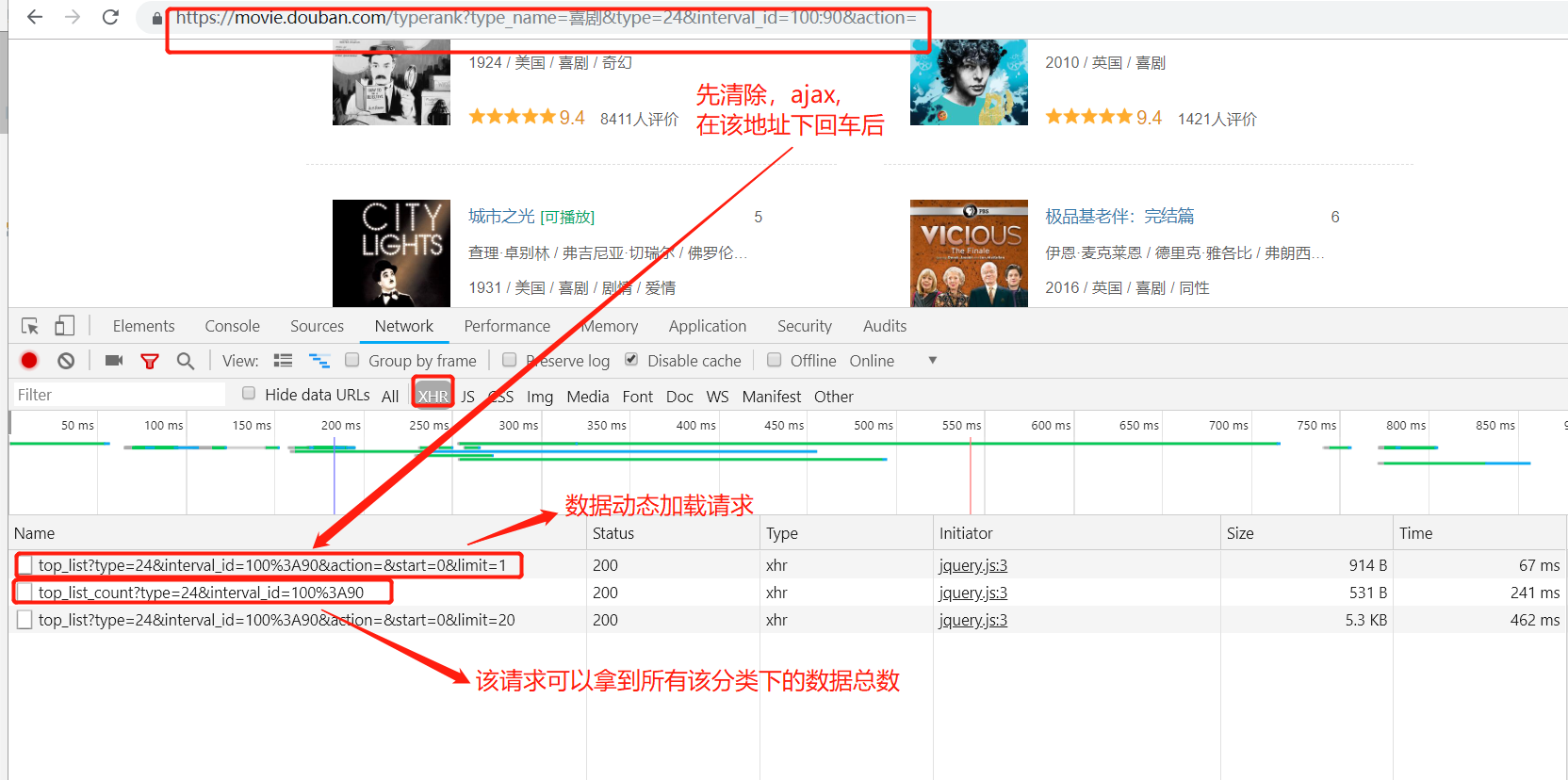

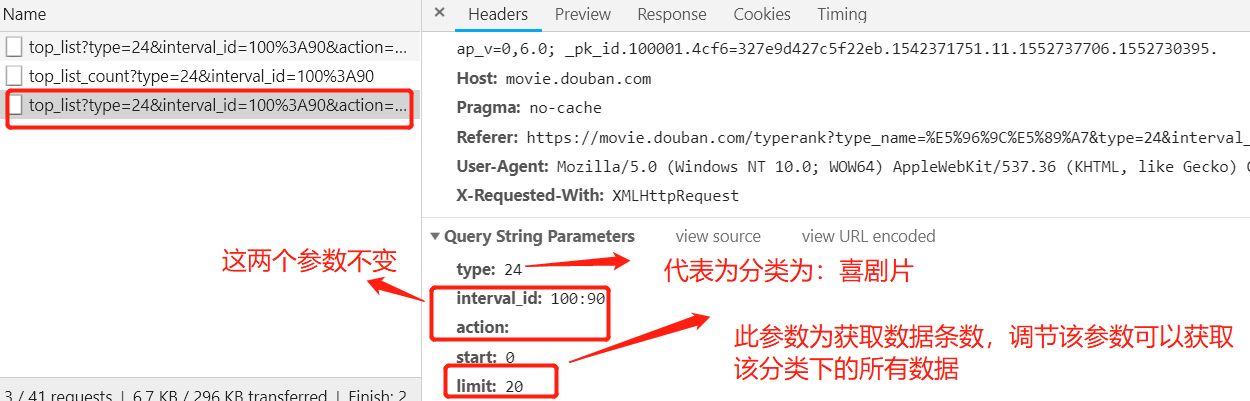
经上分析:
1. 参数 type 和 limit 是关键。
2. limit 的最大值就是该分类下的所有电影总数,而获取电影总数可以发请求到
# https://movie.douban.com/j/chart/top_list_count?type=24&interval_id=100%3A90
url = " https://movie.douban.com/j/chart/top_list_count"

携带的参数: ?type=24&interval_id=100%3A90
params={"type":"24",'interval_id':''100:90"}
3. 获取 所有type 值: url = "https://movie.douban.com/chart"

最后分析总结:
1. get请求 :url1 = https://movie.douban.com/chart 到该地址下拿到所有type值,弄成字典,{“喜剧”:“24”,“动作”:“5”.......}
2.get 请求 : url2 = https://movie.douban.com/j/chart/top_list_count ,带上参数 type 获取该分类下的所有电影总数。
3.get请求 : url3 = https://movie.douban.com/j/chart/top_list
需要的参数: type , limit (l把该分类下所有的电影总数,赋值给 limit ,就可以爬取该分类下所有的电影。 把type 做改
变就可以 爬取不同分类下的所有电影。
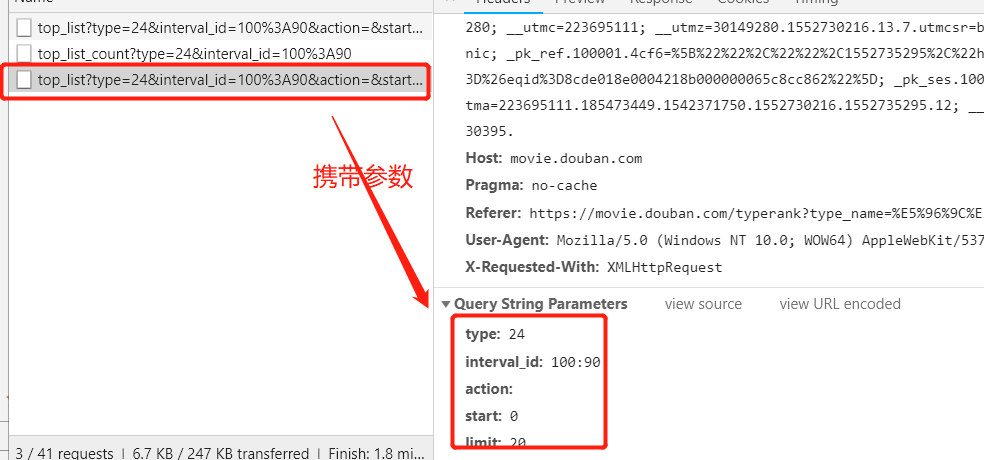
所以整体的爬取思路已经非常清晰。
代码实现:


class Douban(object): def __init__(self): self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } self.type_dic={} #存 self.type=None self.moive_type=None self.total_data_nums=None self.name=None # 电影类型 def get_type_dic(headers): ''' 获取豆瓣分类的电影,对应type值, :return: 返回为一个字典 :{'喜剧': '24', '动作': '5'} ,value表示type值 ''' dic = {} type_dic={} url = "https://movie.douban.com/chart" page_text = requests.get(url, headers=self.headers).text # 使用正则 <span><a href="/typerank?type_name=黑色电影&type=31&interval_id=100:90&action=">黑色电影</a></span> ex = 'type_name=(.*?)&type=(.*?)&interval_id' lst = re.findall(ex, page_text, re.S) for item in lst: dic[item[0]] = item[1] type_dic[item[0]]=item[1] # print(dic) # 格式: {'喜剧': '24', '动作': '5'} 数字表示 type return type_dic # {'喜剧': '24', '动作': '5'} self.type_dic=get_type_dic(self.headers) def show_movie_type(self): count=0 for name,type in self.type_dic.items(): count+=1 print("%s-----%s"%(count,name)) moive_type = input("请选择你要爬取的电影类型:").strip() self.type = self.type_dic.get(moive_type) return self.type # 获取某一个 类型 所有电影总数 ,如喜剧 type 为24 ,把type 传入该函数就能获取 def get_total_num(self): url_count = 'https://movie.douban.com/j/chart/top_list_count' params_count = { # "type": "11", # 电影分类 ,可变 # "interval_id": '100:90', "type": self.type, "interval_id": '100:90', } # 向该发请求,拿到总共的数据总数 count_data = requests.get(url=url_count, headers=self.headers, params=params_count) count_data_dic = count_data.json() # print(count_data_dic) # {'playable_count': 330, 'total': 614, 'unwatched_count': 614} self.total_data_nums = count_data_dic.get("total") # 拿到该类型电影所有的电影数 return self.total_data_nums def get_total_data(self): # url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=1' url = "https://movie.douban.com/j/chart/top_list" params = { # "type": "11", "type": self.type, "interval_id": '100:90', "action": "", "start": "0", # "limit": "120" "limit": self.get_total_num() } res_text = requests.get(url, params=params, headers=self.headers).json() # 得到的是一个json 数据 此处为列表 filename = "%s.txt"%(self.name) f=open(filename,"w",encoding="utf-8") count = 0 for item in res_text: count += 1 # print("%s====>" % count, item)# 在此处可以存数据 f.write(json.dumps(item,ensure_ascii=False)+" ") print("%s===>%s---%s---%s"%(item['title'],item['types'],item['regions'],item['actors'])) f.close() print("%s文件:已经保存!"%filename) def run(self): while 1: count = 0 relation_dic={} for name, type in self.type_dic.items(): count += 1 print("%s-----%s" % (count, name)) # 给用户展示 可以选择的电影内容 relation_dic[str(count)]=type moive_type = input("选择你要爬取的电影类型(Q退出):").strip() # 把用户选择的电影类型赋值给 self.type self.type = self.type_dic.get(moive_type) or relation_dic.get(moive_type) if moive_type.upper() == "Q": break if not self.type: print("你选择的电影类型不存在,请重新选择!") else: # 把用户选择的电影类型存起来,用于保存,作为文件名 if self.type_dic.get(moive_type): self.name = self.type_dic.get(moive_type) else: choose_type=relation_dic[moive_type] for name ,type in self.type_dic.items(): if choose_type==type: self.name=name self.get_total_data() douban = Douban() douban.run()
以上是用类来实现的, 用户输入编号或电影分类名,就可以下载该类下的所有电影信息,并保存。(此处保存到文件。)