http://www.jb51.net/article/50680.htm
神马是“解释器模式”?
先翻开《GOF》看看Definition:
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
在开篇之前还是要科普几个概念:
抽象语法树:
解释器模式并未解释如何创建一个抽象语法树。它不涉及语法分析。抽象语法树可用一个表驱动的语法分析程序来完成,也可用手写的(通常为递归下降法)语法分析程序创建,或直接client提供。
解析器:
指的是把描述客户端调用要求的表达式,经过解析,形成一个抽象语法树的程序。
解释器:
指的是解释抽象语法树,并执行每个节点对应的功能的程序。
要使用解释器模式,一个重要的前提就是要定义一套语法规则,也称为文法。不管这套文法的规则是简单还是复杂,必须要有这些规则,因为解释器模式就是按照这些规则来进行解析并执行相应的功能的。
先来看看解释器模式的结构图和说明:
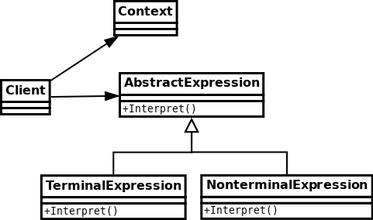
AbstractExpression:定义解释器的接口,约定解释器的解释操作。
TerminalExpression:终结符解释器,用来实现语法规则中和终结符相关的操作,不再包含其他的解释器,如果用组合模式来构建抽象语法树的话,就相当于组合模式中的叶子对象,可以有多种终结符解释器。
NonterminalExpression:非终结符解释器,用来实现语法规则中非终结符相关的操作,通常一个解释器对应一个语法规则,可以包含其他的解释器,如果用组合模式来构建抽象语法树的话,就相当于组合模式中的组合对象。可以有多种非终结符解释器。
Context:上下文,通常包含各个解释器需要的数据或是公共的功能。
Client:客户端,指的是使用解释器的客户端,通常在这里将按照语言的语法做的表达式转换成为使用解释器对象描述的抽象语法树,然后调用解释操作。
下面我们通过一个xml示例来理解解释器模式:
首先要为表达式设计简单的文法,为了通用,用root表示根元素,abc等来代表元素,一个简单的xml如下:
<?xml version="1.0" encoding="UTF-8">
<root id="rootId">
<a>
<b>
<c name="testC">12345</c>
<d id="1">d1</d>
<d id="2">d2</d>
<d id="3">d3</d>
<d id="4">d4</d>
</b>
</a>
</root>
约定表达式的文法如下:
1.获取单个元素的值:从根元素开始,一直到想要获取取值的元素,元素中间用“/”分隔,根元素前不加“/”。比如,表达式“root/a/b/c”就表示获取根元素下,a元素下,b元素下,c元素的值。
2.获取单个元素的属性的值:当然是多个,要获取值的属性一定是表达式的最后一个元素的属性,在最后一个元素后面添加“.”然后再加上属性的名称。比如,表达式“root/a/b/c.name”就表示获取根元素下,a元素下,b元素下,c元素的name属性的值。
3.获取相同元素名称的值,当然是多个,要获取值的元素一定是表达式的最后一个元素,在最后一个元素后面添加“$”。比如,表达式“root/a/b/d$”就表示获取根元素下,a元素下,b元素下的多个d元素的值的集合。
4.获取相同元素名称的属性的值,当然也是多个:要获取属性值的元素一定是表达式的最后一个元素,在最后一个元素后面添加"$"。比如,表达式“root/a/b/d$.id$”就表示获取根元素下,a元素下,b元素下的多个d元素的id属性的值的集合。
上面的xml,对应的抽象语法树,可能的结构如图:
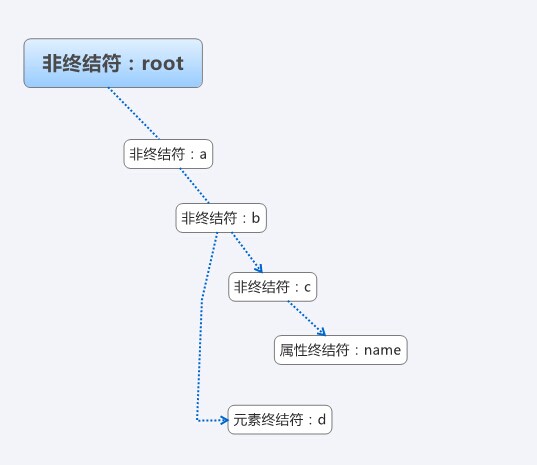
下面我们来看看具体的代码:
1.定义上下文:
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理元素
this.preEle = null;
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEle = null;
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEle: function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i < len; i++) {
if ((nowEle = tempNodeList[i]).nodeType === 1)
if (nowEle.nodeName === eleName)
return nowEle;
}
return null;
},
getPreEle: function () {
return this.preEle;
},
setPreEle: function (preEle) {
this.preEle = preEle;
},
getDocument: function () {
return this.document;
}
};
在上下文中使用了一个工具对象XmlUtil来获取xmlDom,下面我使用的是DOM3的DOMPaser,某些浏览器可能不支持,请使用搞基浏览器:
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('<root id="rootId"><a><b><c name="testC">12345</c><d id="1">d1</d><d id="2">d2</d><d id="3">d3</d><d id="4">d4</d></b></a></root>', 'text/xml');
return xmldom;
}
};
下面就是解释器的代码:
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEle = context.getPreEle();
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEle().getAttribute(this.propName);
}
};
先来看看如何使用解释器获取单个元素的值:
void function () {
var c = new Context();
// 想要获取多个d元素的值,也就是如下表达式的值:“root/a/b/c”
// 首先要构建解释器的抽象语法树
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var cEle = new ElementTerminalExpression('c');
// 组合
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
console.log('c的值是 = ' + root.interpret(c));
}();
输出: c的值是 = 12345
然后我们再用上面代码获取单个元素的属性的值:
void function () {
var c = new Context();
// 想要获取d元素的id属性,也就是如下表达式的值:“a/b/c.name”
// 这个时候c不是终结了,需要把c修改成ElementExpression
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var cEle = new ElementExpression('c');
var prop = new PropertyTerminalExpression('name');
// 组合
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('c的属性name值是 = ' + root.interpret(c));
// 如果要使用同一个上下文,连续进行解析,需要重新初始化上下文对象
// 比如,要连续的重新再获取一次属性name的值,当然你可以重新组合元素
// 重新解析,只要是在使用同一个上下文,就需要重新初始化上下文对象
c.reInit();
console.log('重新获取c的属性name值是 = ' + root.interpret(c));
}();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表 示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用 再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优 势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还 有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
正是由于采用一个解释器对象负责一条语法规则的方式,使得扩展新的语法非常容易。扩展了新的语法,只需要创建相应的解释器对象,在创建抽象语法树的时候使用这个新的解释器对象就可以了。
缺点:
不适合复杂的语法
如果语法特别复杂,构建解释器模式需要的抽象语法树的工作是非常艰巨的,再加上有可能会需要构建多个抽象语法树。所以解释器模式不太适合复杂的语法。使用语法分析程序或编译器生成器可能会更好一些。
何时使用?
当有一个语言需要解释执行,并且可以将该语言中的句子表示为一个抽象语法树的时候,可以考虑使用解释器模式。
在使用解释器模式的时候,还有两个特点需要考虑,一个是语法相对应该比较简单,太负责的语法不适合使用解释器模式玲玲一个是效率要求不是很高,对效率要求很高的,不适合使用。
前面介绍了如何获取单个元素的值和单个元素属性的值,下面来看看如何获取多个元素的值,还有多个元素中相拥名称的值,还有前面的测试都是人工组合好 的抽象语法树,我们也顺便实现以下简单的解析器,把符合前面定义的语法的表达式,转换成为前面实现的解释器的抽象语法树: 我就直接把代码贴出来了:
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i < len; i++) {
if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('<root
id="rootId"><a><b><c
name="testC">12345</c><d id="1">d1</d><d
id="2">d2</d><d id="3">d3</d><d
id="4">d4</d></b></a></root>', 'text/xml');
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i < len; i++) {
tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i < len; i++) {
ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i < len; i++) {
nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i < len; i++) {
ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i < len; i++) {
nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i < len; i++) {
console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i < len; i++) {
console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i < len; i++) {
onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
/**
* 按照分解出来的位置和名称来设置需要解析的元素名称
* @param {Boolean} end [是否最后一个]
* @param {String} ele [元素名称]
* @param {Boolean} propertyValue [是否取属性]
* @param {Object} mapPath [设置需要解析的元素名称,还有该元素对应的解析模型的表]
*/
function setParsePath(end, ele, propertyValue, mapPath) {
var pm = new ParserModel();
pm.setEnd(end);
// 如果带有“$”符号就说明不是一个值
pm.setSingleValue(!(ele.indexOf(DOLLAR) >= 0));
pm.setPropertyValue(propertyValue);
// 去掉"$"
ele = ele.replace(DOLLAR, '');
mapPath[ele] = pm;
listEle.push(ele);
}
// 开始实现第二步-------------------------------------
/**
* 把分解出来的元素名称根据对应的解析模型转换成为相应的解释器对象
* @param {Object} mapPath [分解出来的需解析的元素名称,还有该元素对应的解析模型]
* @return {Array} [把每个元素转换成为相应的解释器对象后的数组]
*/
function mapPath2Interpreter(mapPath) {
var list = [];
var pm, key;
var obj = null;
// 一定要按照分解的先后顺序来转换成解释器对象
for (var i = 0, len = listEle.length; i < len; i++) {
key = listEle[i];
pm = mapPath[key];
// 不是最后一个
if (!pm.isEnd()) {
if (pm.isSingleValue())
// 是一个值,转化
obj = new ElementExpression(key);
else
// 是多个值,转化
obj = new ElementsExpression(key);
} else {
// 是最后一个
// 是属性值
if (pm.isPropertyValue()) {
if (pm.isSingleValue())
obj = new PropertyTerminalExpression(key);
else
obj = new PropertysTerminalExpression(key);
// 取元素的值
} else {
if (pm.isSingleValue())
obj = new ElementTerminalExpression(key);
else
obj = new ElementsTerminalExpression(key);
}
}
list.push(obj);
}
return list;
}
// 开始实现第三步-------------------------------------
/**
* 构建抽象语法树
* @param {[type]} list [把每个元素转换成为相应的解释器对象后的数组]
* @return {[type]} [description]
*/
function buildTree(list) {
// 第一个对象,也是返回去的对象,就是抽象语法树的根
var returnReadXMLExpr = null;
// 定义上一个对象
var preReadXmlExpr = null;
var readXml, ele, eles;
for (var i = 0, len = list.length; i < len; i++) {
readXml = list[i];
// 说明是第一个元素
if (preReadXmlExpr === null) {
preReadXmlExpr = readXml;
returnReadXMLExpr = readXml;
// 把元素添加到上一个对象下面,同时把本对象设置成为oldRe
// 作为下一个对象的父节点
} else {
if (preReadXmlExpr instanceof ElementExpression) {
ele = preReadXmlExpr;
ele.addEle(readXml);
preReadXmlExpr = readXml;
} else if (preReadXmlExpr instanceof ElementsExpression) {
eles = preReadXmlExpr;
eles.addEle(readXml);
preReadXmlExpr = readXml;
}
}
}
return returnReadXMLExpr;
}
return {
// 公共方法
parse: function (expr) {
listEle = [];
var mapPath = parseMapPath(expr);
var list = mapPath2Interpreter(mapPath);
return buildTree(list);
}
};
}();
void function () {
// 准备上下文
var c = new Context('Interpreter.xml');
// 通过解析其获取抽象语法树
var readXmlExpr = Parser.parse('root/a/b/d$.id$');
// 请求解析,获取返回值
var ss = readXmlExpr.interpret(c);
console.log('------------parsing--------------');
for (var i = 0, len = ss.length; i < len; i++) {
console.log('d的属性id的值是 = ' + ss[i]);
}
console.log('---------------parsed--------------');
// 如果要使用同一个上下文,连续进行解析,需要重新初始化上下文对象
c.reInit();
var readxmlExpr2 = Parser.parse('root/a/b/d$');
var ss2 = readxmlExpr2.interpret(c);
console.log('------------parsing--------------');
for (i = 0, len = ss2.length; i < len; i++) {
console.log('d的值是 = ' + ss2[i]);
}
console.log('---------------parsed--------------');
c.reInit();
var readxmlExpr3 = Parser.parse('root/a/b/c');
var ss3 = readxmlExpr3.interpret(c);
console.log('------------parsing--------------');
console.log('c的name属性值是 = ' + ss3);
console.log('---------------parsed--------------');
c.reInit();
var readxmlExpr4 = Parser.parse('root/a/b/c.name');
var ss4 = readxmlExpr4.interpret(c);
console.log('------------parseing--------------');
console.log('c的name属性值是 = ' + ss4);
console.log('---------------parsed--------------');
}();
// 这样就实现了类似XPath的部分功能
// 没错,就类似于jQuery选择器的部分功能
}());
输出: d的值是 = d1
d的值是 = d2
d的值是 = d3
d的值是 = d4
d的属性id的值是 = 1
d的属性id的值是 = 2
d的属性id的值是 = 3
d的属性id的值是 = 4
------------parsing--------------
d的属性id的值是 = 1
d的属性id的值是 = 2
d的属性id的值是 = 3
d的属性id的值是 = 4
---------------parsed--------------
------------parsing--------------
d的值是 = d1
d的值是 = d2
d的值是 = d3
d的值是 = d4
---------------parsed--------------
------------parsing--------------
c的name属性值是 = 12345
---------------parsed--------------
------------parseing--------------
c的name属性值是 = testC
---------------parsed--------------