n()外的计数函数还包括
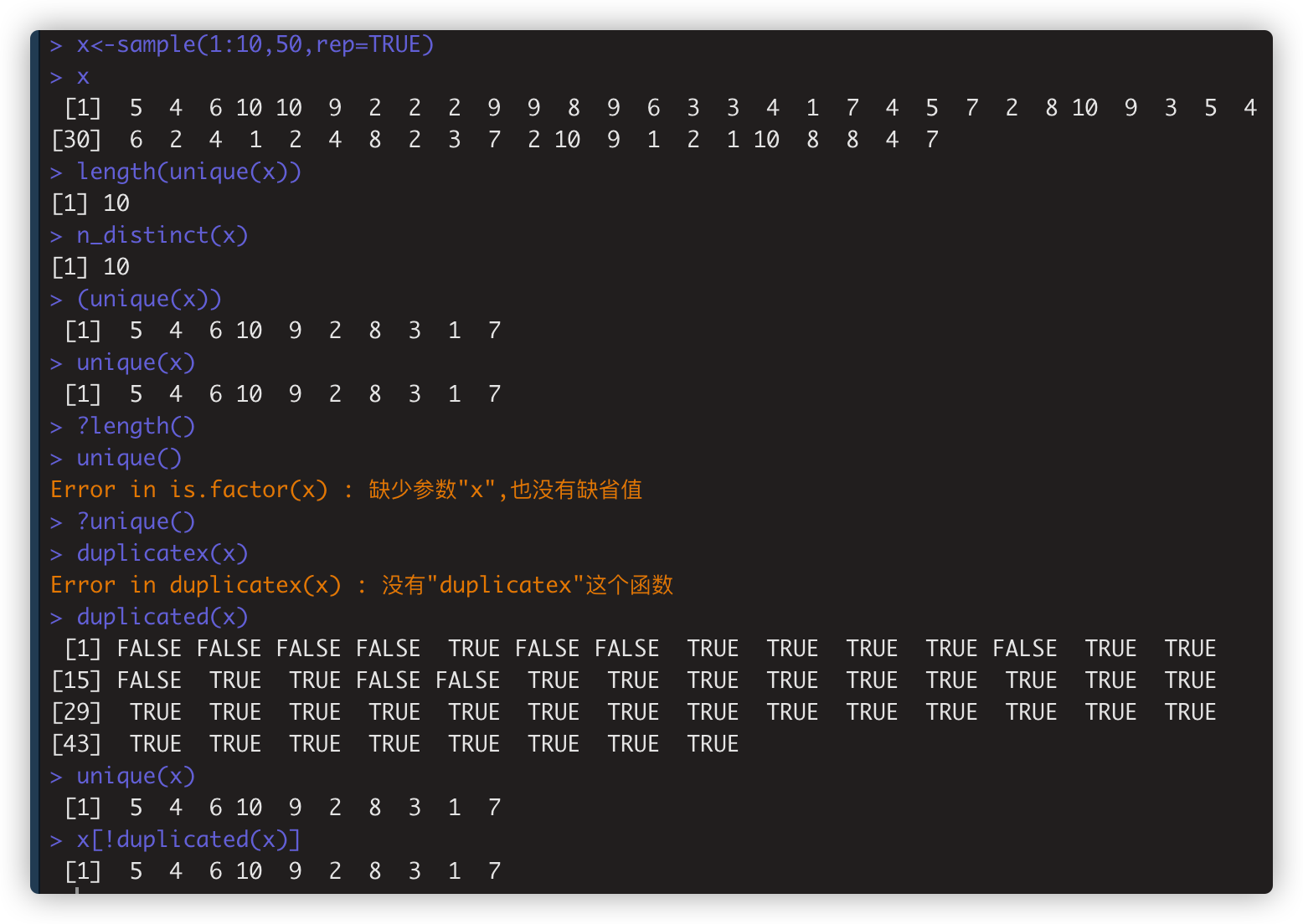
- n_distinct(x)取x向量中unique值的个数,等同 length(unique(x))
。如: 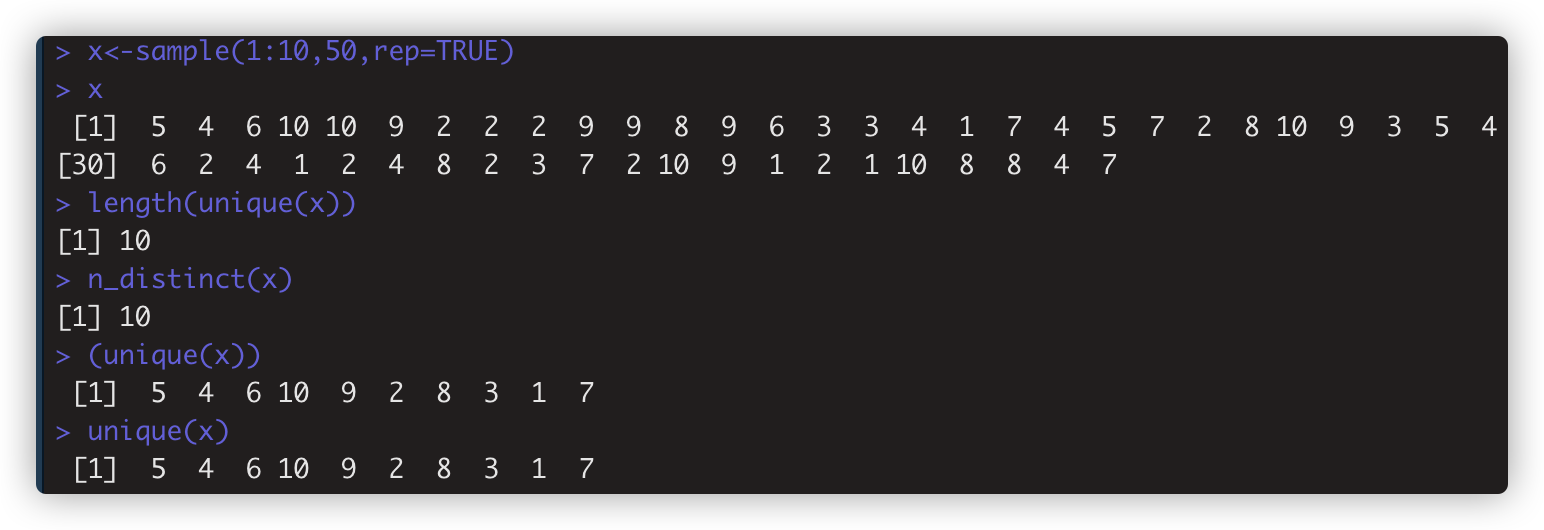
- tally(x, wt = NULL, sort = FALSE, name = "n")
- count(x, ..., wt = NULL, sort = FALSE, name = "n",.drop = group_by_drop_default(x))
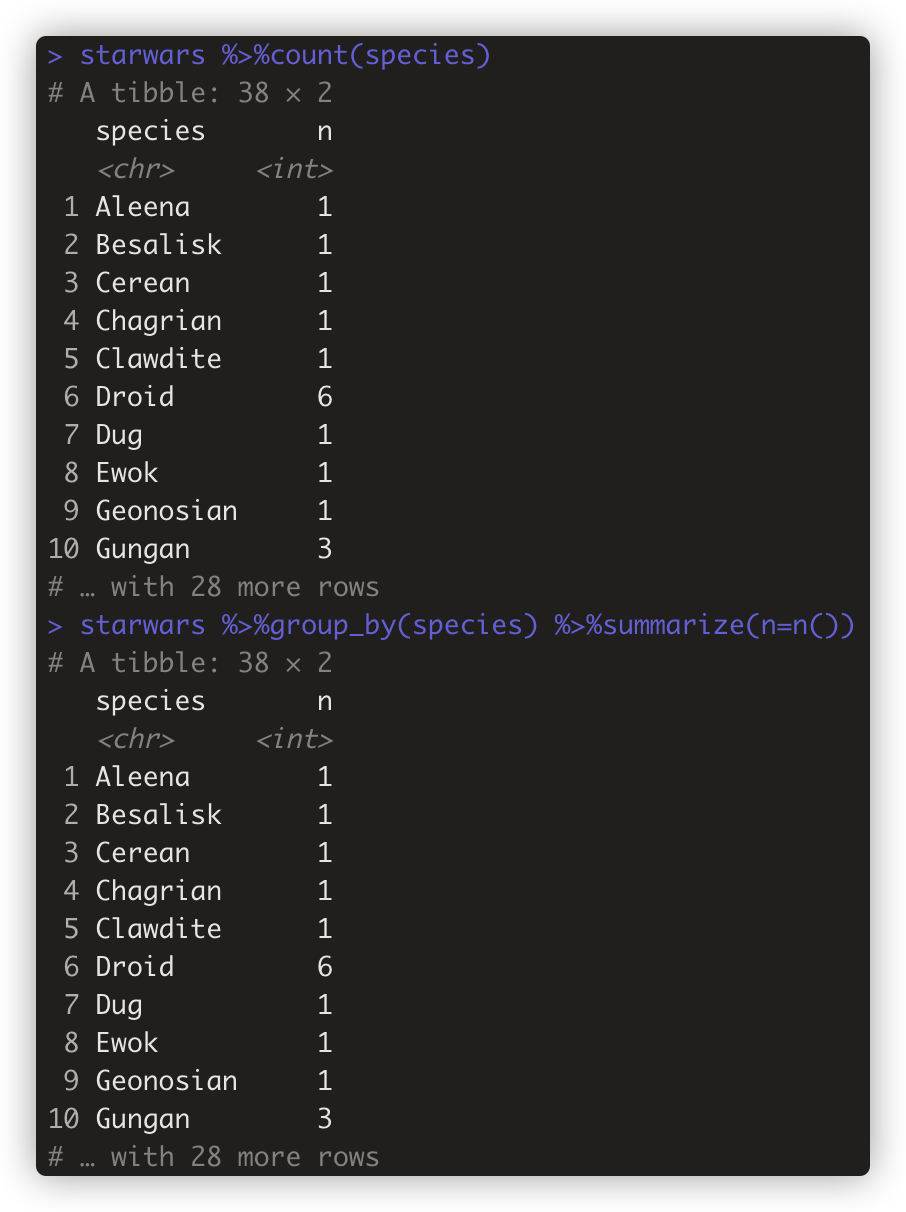
- starwars %>%count(species) 等同 starwars %>%group_by(species) %>%summarize(n=n())
- #count 计算变量作为分组的计数。
- add_tally(x, wt, sort = FALSE, name = "n")
- add_count(x, ..., wt = NULL, sort = FALSE, name = "n")
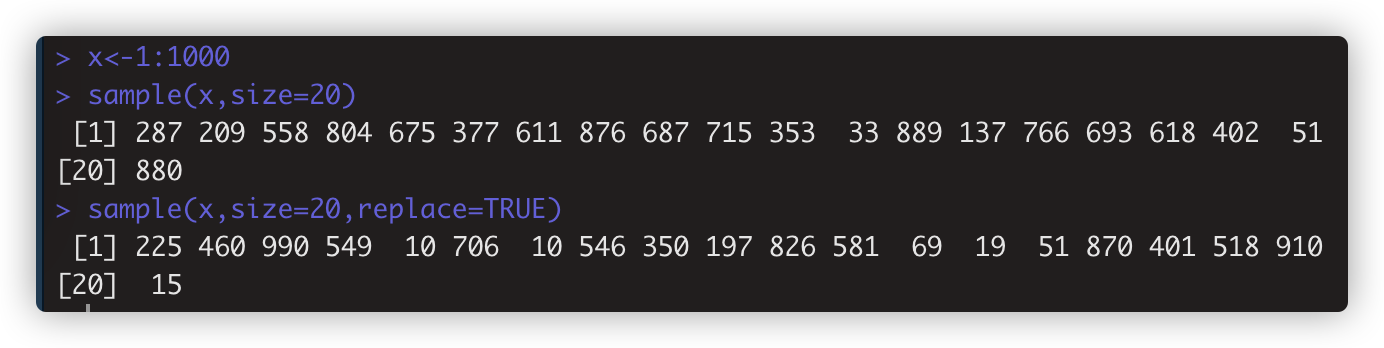
sample(x,size=20,replace=TRUE) 抽样,
size取样次数。默认是x向量元素的个数次。
replace() 可重复抽样。

length() 取向量元素的个数。
unique() 返回已删除duplicate的向量. unique(x)等效 x[!duplicated(x)]
duplicated(x) 检测向量中哪些元素是前面元素的duplicates。