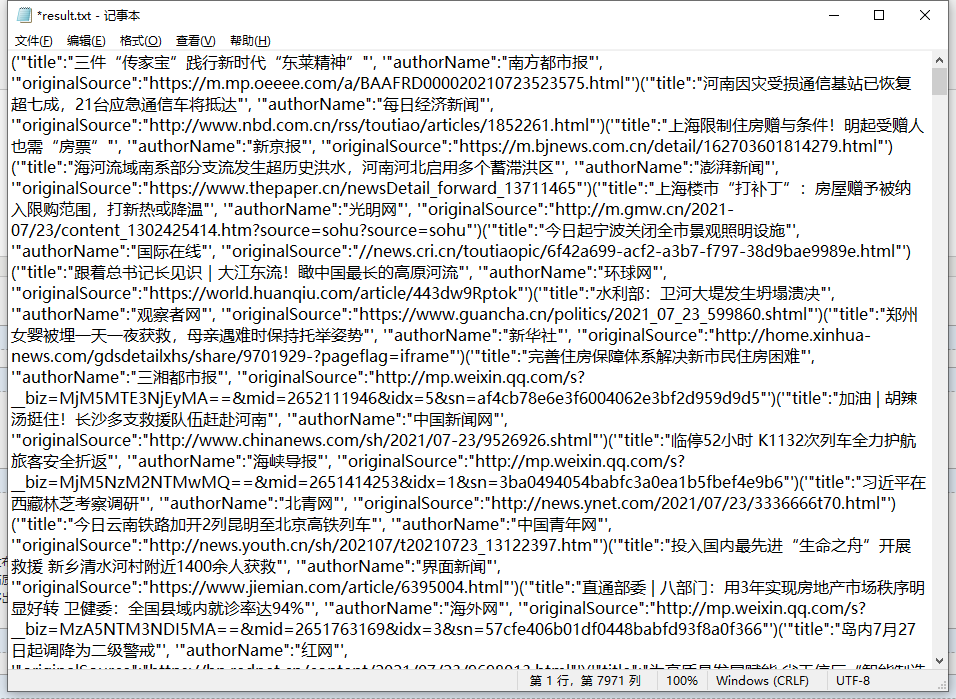
一 、整体流程
爬取页面:https://www.sohu.com/c/8/1460?spm=smpc.news-home.top-subnav.2.1627024626549cMWiORW
获取url——爬取出版社及新闻名称及其超链接——解析数据——存储数据
二、分析
观察页面发现,搜狐新闻页面属于动态页面(动态页面也可采取selenium获取数据,效率比较慢)
打开network,XHR并没有想要的内容,所以得换个思路
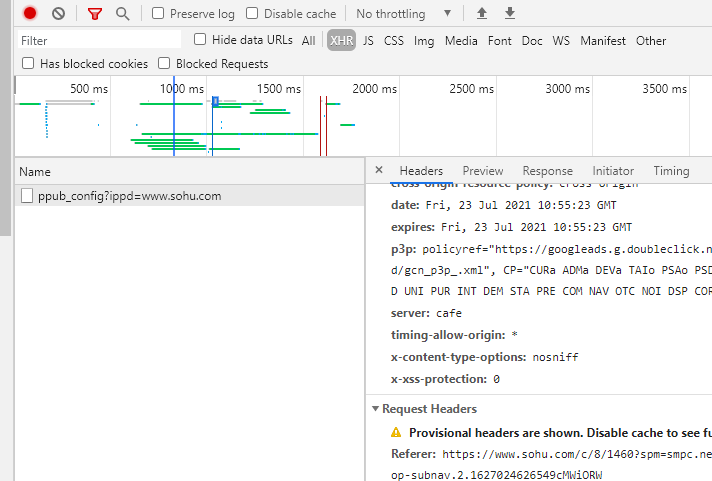
network中杂七杂八的请求比较多,可以过滤掉便于查看可疑请求
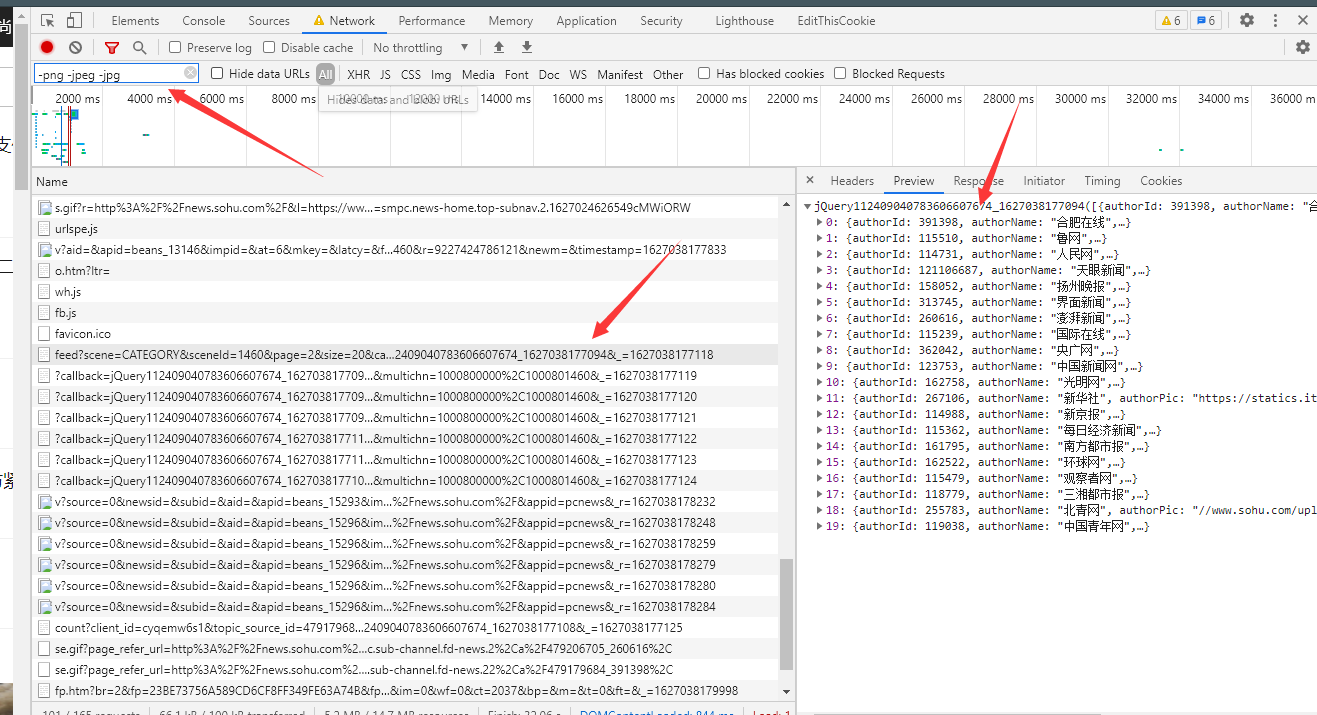
在ALL中发现该文件有需要的内容
分析一下url
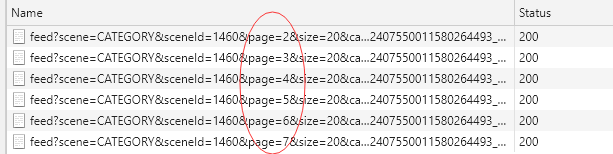
发现page每次变化
可以采用字符串拼接出来url
三、代码实现
import requests
import re
# 获取数据
def get_one_page(url):
response = requests.get(url)
return response.text
# 采用正则进行提取数据
def parse_one_page(data):
result = re.findall(r'("title":".*?").*?("authorName":".*?").*?("originalSource":".*?")', data)
return result
# 写入数据
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(content)
# 根据page获取数据
def main(page):
url = "https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=1460&size=20&page=" + str(page)
data = get_one_page(url)
for item in parse_one_page(data):
write_to_file(str(item))
if __name__ == '__main__':
for i in range(1, 20):
main(page=i)
四、结果