1模块: 龟叔这个python内部有些功能无法完成,需要借助已经实现了的函数或者类来完成这些功能.引入了模块这个概念
模块的格式:: 别人写好的一组功能: 包含文件夹py文件C语言写好并编译好的一些文件dll结尾的文件
2.引入的好处:(1) 分类管理方法, (2) 节省内存 (3)提供更多的功能
3,分类 (1)内置模块: 安装python解释器的时候跟着装上的那些方法
(2)第三方模块/扩展模块 没在安装python解释器的时候安装的那些功能
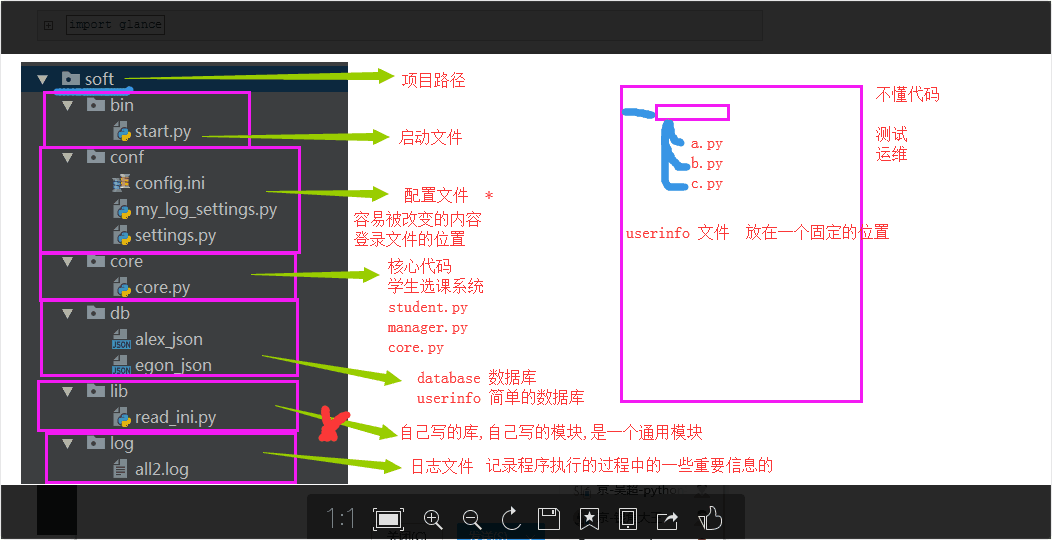
(3)自定义模块 你写的功能如果是一个通用的功能,那你就把它当做一个模块
4,PEP8规范:
要导入一个py文件的名字,但是不加.py后缀名
模块的名字必须要满足变量的命名规范, 一般情况下 模块都是小写字母开头的名字
所有的模块导入都应该尽量放在这个文件的开头
模块导入顺序:(1)先导入内置模块 (2)再导入第三方模块 (3)最后导入自定义模块
6,模块的倒入方式
(1) import 模块名 理解: 加载模块一次,模块内的所有变量名字(包括变量,函数,或者类),都可以通过模块来引用,多次引用没有意义,不会重新加载模块
调用方法: 模块名.变量名 =====>变量名: 模块名.变量名 函数名: 模块名.变量名 () 类名: 模块名.变量名() 实例化对象
空间变化: 名称空间都是各自独立的,只不过通过模块名建立一种引用关系
重命名: 引入的模块变量名被修改,调用的时候就用新的变量调用 用 as 修改,修改后的变量名与被调用的模块重新建立引用关系
小技巧但不建议用: ====> 一行倒入多个模块,模块名之间用逗号隔开
(2)from 模块名 import 变量名 理解:加载一次模块,指定引用模块内模块内的某个变量名(包括变量,函数,或者类),可以引用多个不同的变量
调用方法 =====> :变量名: 直接用 函数名: 变量名() 类名: 变量名() 实例化对象
空间变化: 名称空间都是各自独立的,只不过通过变量名建立一种与模块内的变量名的引用关系 注意:本py文件命名时最好不要重复命名.这样会破坏引用关系
重命名: 引入的模块变量名被修改,调用的时候就用新的变量调用 用 as 修改,修改后的变量名与被调用的模块重新建立引用关系
from 模块名 inport * 这种格式的导入模块,直接导入模块内的所有变量名 ,通过内置命令可以控制需要用的变量名固定格式如下:
__all__ = ['login','高永杰'] 列表内得而所有元素都是可以
6: 模块倒入效率: 当导入文件的时候,python解释器就会在文件所在目录的__pycache__ 下生成一个编译好的pyc文件,这个文件具有通用型,可以跨平台使用,以后在导入 这个模块的时候就省时间
模块的循环引用: 模块的倒入过程,千万注意不能形成环形引用, 和两个模块互相引用 技巧:可以画图,排除是否有循环引用
7; 重点: __name__ 本质是个内置的私有变量名,str类型的.
这里要提前了解一个概念<sys.moudles这是一个全局字典,python启动时,会记录下导入的模块,是一个字典,__main__这个字符串key.永远与当前文件的py文件是一个键值对
特性: 当文件以脚本运行时,print(__name__ )就是__main__ 这个结果格式也是字符串
当文件以模块被引用时: 模块内的__name__ 就会变成模块名, 这样配合sys.moudles就能调用该模块的内存地址
也正是引文这种特性,一般在编写代码时,为了在被调用时不打印不必要的内容,常用以下格式的固定内容来过滤内容
if __name == '__main__':
xxxxxxxx()
8,模块的搜索路径:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
我们自定义的模块名不应该与系统内置模块重名
内置函数 print(dri()) 这样可以查看模块内所有定义的名字,返回一个有序的字符串列表
import builtins dir(builtins) 可以查看内置函数或者变量的名字
注意:::sys.path 从第一个路径是当前执行文件的所在的文件夹开始寻找
9: 包: 由各种py文件组成的带有__init__.py的文件夹
导入包相当于执行了包下面的 __init__.py 文件
通过在__init__文件内设计导入模块,来完成实际需要导入的模块
绝对路径: copypath
相对路径:使用了相对导入的模块只能被当作模块执行,不能被当作脚本执行
10.软件开发规范: